每月20元!智谱GLM-4.5杀入Claude Code,开启编程API“包月”时代
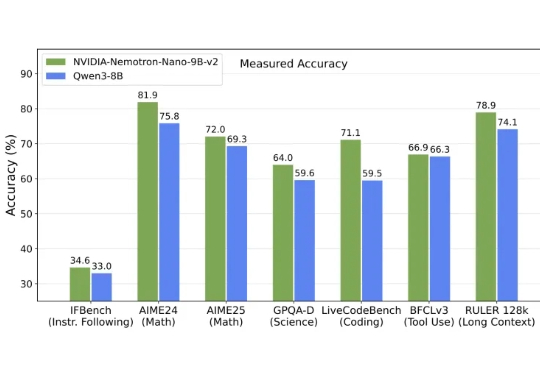
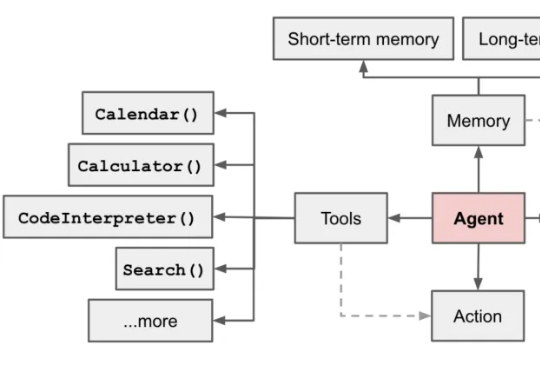
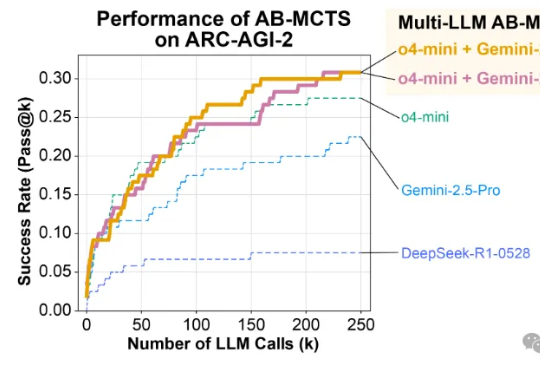
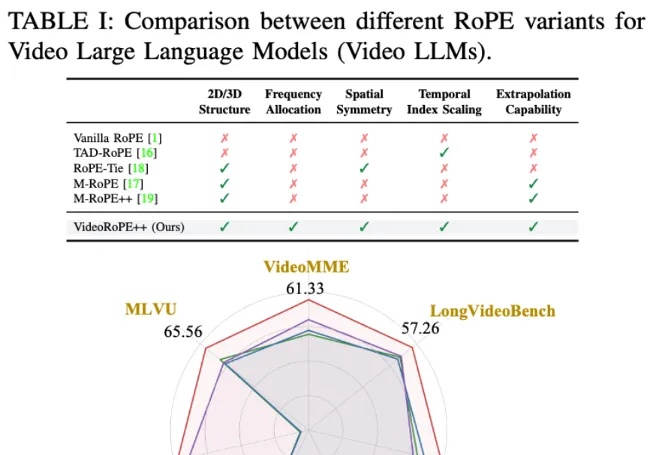
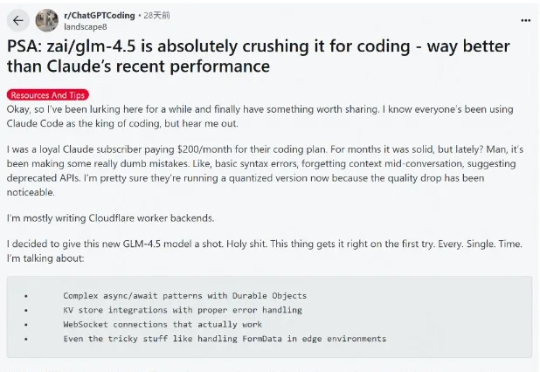
每月20元!智谱GLM-4.5杀入Claude Code,开启编程API“包月”时代这段时间 AI 编程的热度完全没退,一个原因是国内接连推出开源了不少针对编程优化的大模型,主打长上下文、Agent 智能体、工具调用,几乎成了标配,成了 Claude Code 的国产替代,比如 GLM-4.5、DeepSeek V3.1、Kimi K2。
来自主题: AI资讯
16074 点击 2025-09-02 11:41