Scaling Law没死!Gemini核心大佬爆料,谷歌已有颠覆性密钥
Scaling Law没死!Gemini核心大佬爆料,谷歌已有颠覆性密钥谷歌大模型将迎颠覆升级!Gemini负责人爆料:长上下文效率与长度双重突破在即,注意力机制迎来惊人发现。Scaling Law未死,正加速演变!
来自主题: AI资讯
8679 点击 2025-12-20 10:13
 搜索
搜索
谷歌大模型将迎颠覆升级!Gemini负责人爆料:长上下文效率与长度双重突破在即,注意力机制迎来惊人发现。Scaling Law未死,正加速演变!

两项关于大模型新架构的研究一口气在NeurIPS 2025上发布,通过“测试时训练”机制,能在推理阶段将上下文窗口扩展至200万token。两项新成果分别是:Titans:兼具RNN速度和Transformer性能的全新架构;MIRAS:Titans背后的核心理论框架。

斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。

当前视频检索研究正陷入一个闭环困境:以MSRVTT为代表的窄域基准,长期主导模型在粗粒度文本查询上的优化,导致训练数据有偏、模型能力受限,难以应对真实世界中细粒度、长上下文、多模态组合等复杂检索需求。

大模型「灾难性遗忘」问题或将迎来突破。近日,NeurIPS 2025收录了谷歌研究院的一篇论文,其中提出一种全新的「嵌套学习(Nested Learning)」架构。实验中基于该框架的「Hope」模型在语言建模与长上下文记忆任务中超越Transformer模型,这意味着大模型正迈向具备自我改进能力的新阶段。

月之暗面最新发布的开源Kimi Linear架构,用一种全新的注意力机制,在相同训练条件下首次超越了全注意力模型。在长上下文任务中,它不仅减少了75%的KV缓存需求,还实现了高达6倍的推理加速。
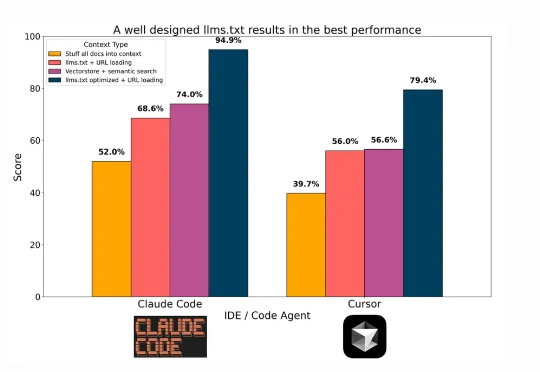
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。

InfLLM-V2是一种可高效处理长文本的稀疏注意力模型,仅需少量长文本数据即可训练,且性能接近传统稠密模型。通过动态切换短长文本处理模式,显著提升长上下文任务的效率与质量。从短到长低成本「无缝切换」,预填充与解码双阶段加速,释放长上下文的真正生产力。

老黄对token密集型任务下手了。

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。