
陈丹琦团队降本大法又来了:数据砍掉三分之一,性能却完全不减
陈丹琦团队降本大法又来了:数据砍掉三分之一,性能却完全不减陈丹琦团队又带着他们的降本大法来了—— 数据砍掉三分之一,大模型性能却完全不减。 他们引入了元数据,加速了大模型预训练的同时,也不增加单独的计算开销。
来自主题: AI资讯
8859 点击 2025-01-08 09:56
 搜索
搜索
陈丹琦团队又带着他们的降本大法来了—— 数据砍掉三分之一,大模型性能却完全不减。 他们引入了元数据,加速了大模型预训练的同时,也不增加单独的计算开销。
会议组织者都是 NLP 头部科学家,在语言建模方面有着相当的成果。

好家伙!为了揭秘Transformer内部工作原理,陈丹琦团队直接复现——

Claude 3.5 Sonnet的图表推理能力,比GPT-4o高出了27.8%。 针对多模态大模型在图表任务上的表现,陈丹琦团队提出了新的测试基准。 新Benchmark比以往更有区分度,也让一众传统测试中的高分模型暴露出了真实能力。

陈丹琦团队刚刚发布了一项新工作,主题是:
比斯坦福DPO(直接偏好优化)更简单的RLHF平替来了,来自陈丹琦团队。 该方式在多项测试中性能都远超DPO,还能让8B模型战胜Claude 3的超大杯Opus。 而且与DPO相比,训练时间和GPU消耗也都大幅减少。

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。

2024年苹果学者名单开奖了!全球21位学者入选名单中,11位华人博士成功入选。其中包括师从陈丹琦、韩家炜教授的博士生。
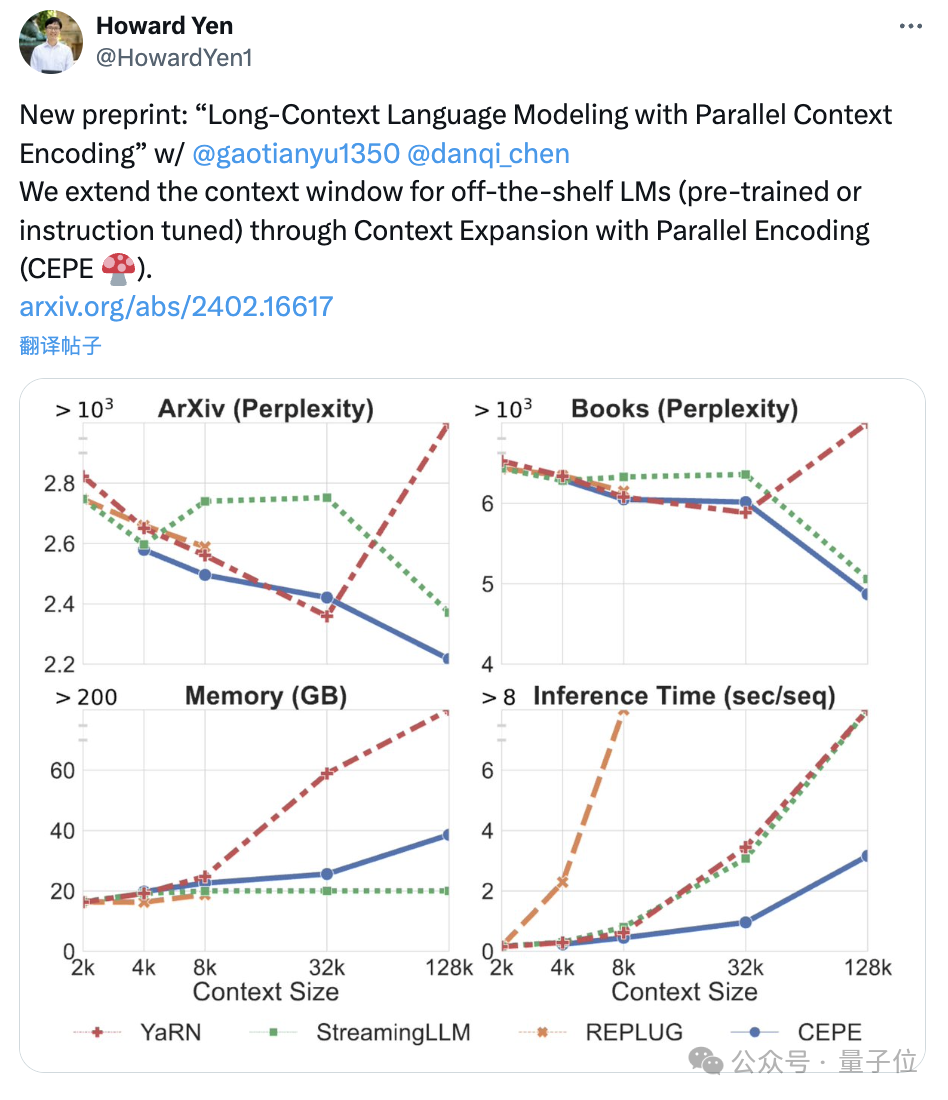
陈丹琦团队刚刚发布了一种新的LLM上下文窗口扩展方法:它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。

造大模型的成本,又被打下来了!这次是数据量狂砍95%的那种。陈丹琦团队最新提出大模型降本大法——数据选择算法LESS, 只筛选出与任务最相关5%数据来进行指令微调,效果比用整个数据集还要好。