无预训练模型拿下ARC-AGI榜三!Mamba作者用压缩原理挑战Scaling Law
无预训练模型拿下ARC-AGI榜三!Mamba作者用压缩原理挑战Scaling Law压缩即智能,又有新进展!
来自主题: AI技术研报
9595 点击 2025-12-16 09:56
 搜索
搜索
压缩即智能,又有新进展!

近日,北京大学团队提出一个直接基于已有预训练模型进行极低比特量化的通用框架——Fairy2i。该框架通过广泛线性表示将实数模型无损转换为复数形式,再结合相位感知量化与递归残差量化,实现了在仅2比特的情况下,性能接近全精度模型的突破性进展。

为破解机器人产业「一机一调」的开发困境,智源研究院开源了通用「小脑基座」RoboBrain-X0。它创新地学习任务「做什么」而非「怎么动」,让一个预训练模型无需微调,即可驱动多种不同构造的真实机器人,真正实现了零样本跨本体泛化。
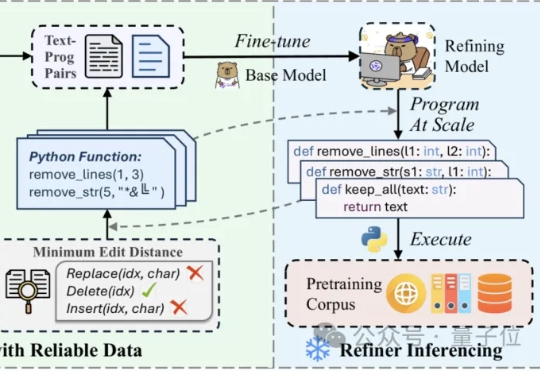
在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据? 中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。

预训练模型能否作为探索新架构设计的“底座” ? 最新答案是:yes!
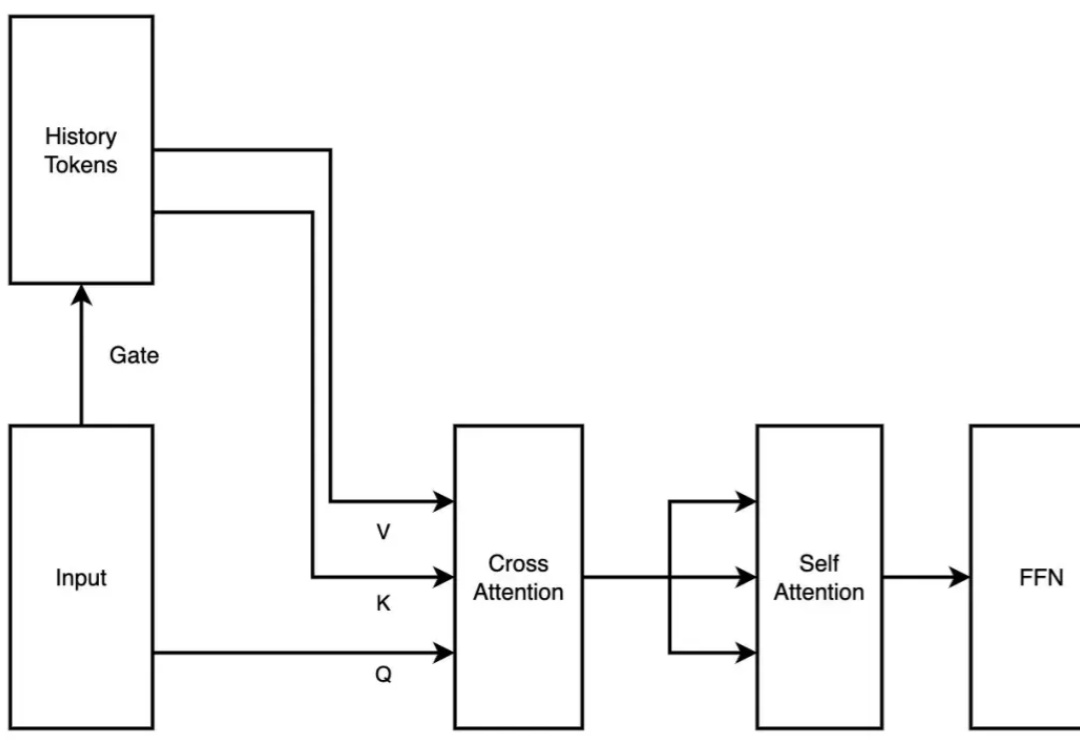
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。

Uni-AdaFocus 是一个通用的高效视频理解框架,实现了降低时间、空间、样本三维度冗余性的统一建模。代码和预训练模型已开源,还有在自定义数据集上使用的完善教程,请访问项目链接。
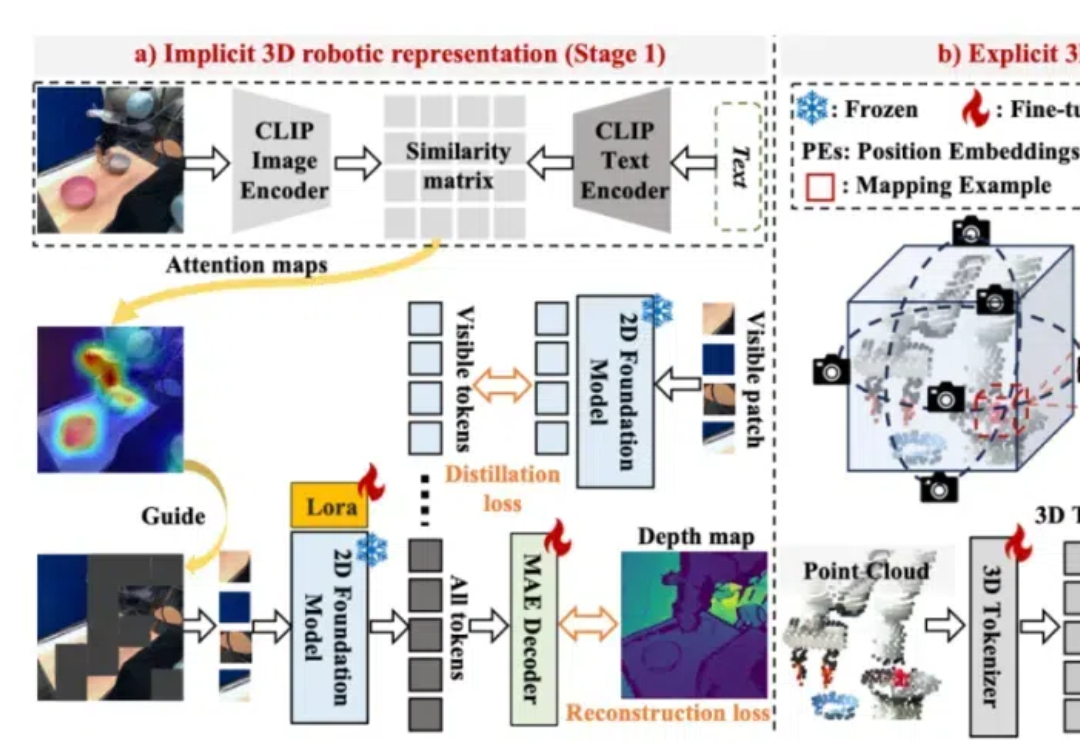
为了构建鲁棒的 3D 机器人操纵大模型,Lift3D 系统性地增强 2D 大规模预训练模型的隐式和显式 3D 机器人表示,并对点云数据直接编码进行 3D 模仿学习。Lift3D 在多个仿真环境和真实场景中实现了 SOTA 的操纵效果,并验证了该方法的泛化性和可扩展性。

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。
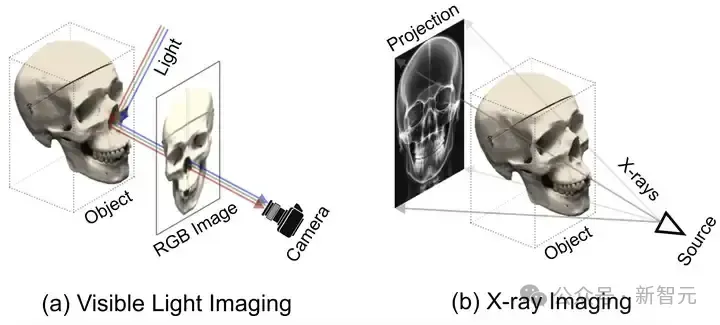
SAX-NeRF框架,一种专为稀疏视角下X光三维重建设计的新型NeRF方法,通过Lineformer Transformer和MLG采样策略显著提升了新视角合成和CT重建的性能。研究者还建立了X3D数据集,并开源了代码和预训练模型,为X光三维重建领域的研究提供了宝贵的资源和工具。