
全球最大触觉数据集Daimon-Infinity,竟然出自一家具身上游公司
全球最大触觉数据集Daimon-Infinity,竟然出自一家具身上游公司4 月 15 日,戴盟机器人联合Google DeepMind、中国移动、新加坡国立大学、香港科技大学、上海交通大学、日本东北大学等海内外数十家顶尖学术机构与知名企业,发布了全球最大规模含触觉全模态物理世界数据集Daimon-Infinity。
来自主题: AI技术研报
6196 点击 2026-04-18 07:27
 搜索
搜索
4 月 15 日,戴盟机器人联合Google DeepMind、中国移动、新加坡国立大学、香港科技大学、上海交通大学、日本东北大学等海内外数十家顶尖学术机构与知名企业,发布了全球最大规模含触觉全模态物理世界数据集Daimon-Infinity。

香港城市大学朱宗龙、曾晓成团队给出了终极终结方案。他们首创了一套AI驱动的自动化闭环研发平台。从2万个分子的“大海捞针”,到自动化机械臂精准制备,再到AI实时反馈调整,全程无需人类插手。

近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,

2026年3月26日彭博独家爆料,AI独角兽Moonshot AI(月之暗面)正处于考虑在香港进行IPO的早期阶段,计划登陆香港资本市场。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大
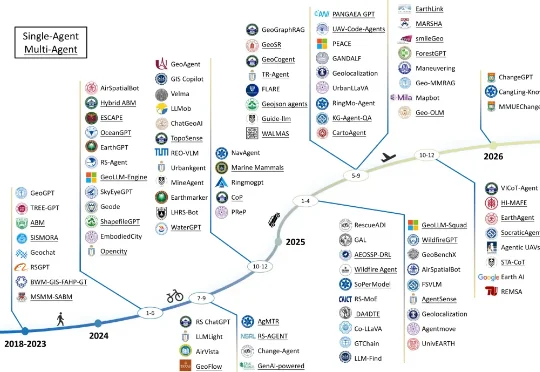
如今,一场由 AI 智能体驱动的变革正在发生。近日,来自香港科技大学、西北工业大学、清华大学等多家高校及研究机构的学者联合发布了遥感 AI 智能体领域系统综述。全文逾万字,首次为「遥感智能体」给出了严格定义,系统梳理了其架构、应用、数据集与未来方向。

香港用户终于等来了这一天——谷歌宣布将逐步向香港开放 Gemini 网页应用,这意味着以后再也不需要翻墙 VPN 就能用上谷歌的 AI 助手了。在此之前,使用香港网络的用户一直无法直接访问 Gemini,需要借助 VPN 等「曲线救国」的方式才能使用。
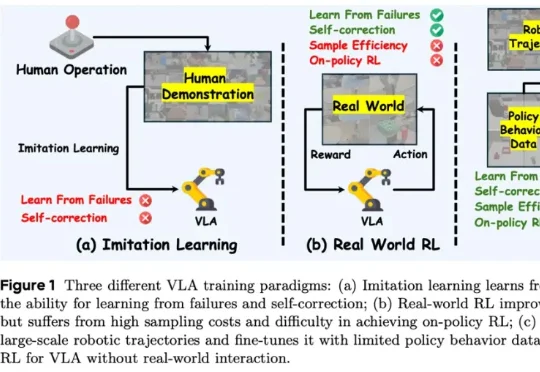
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。

香港科技大学 & 北航 & 商汤等提出了一个专门面向视频生成扩散模型的 QAT 范式 ——QVGen,在 3-bit / 4-bit 都能把质量拉回来,并且让 4-bit 首次接近全精度表现成为现实。该论文现已被 ICLR 高分接收:rebuttal 前 88666(top 1.4%),rebuttal 后 88886 (top 0.5%)。