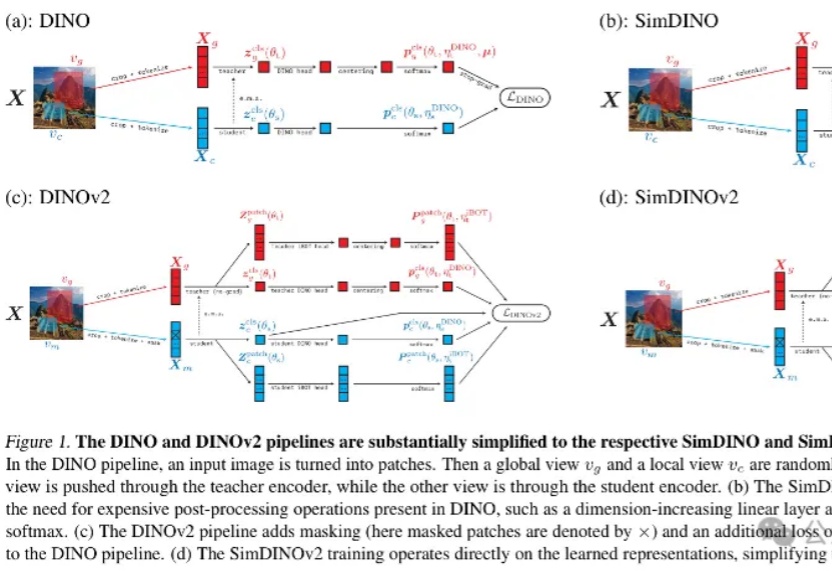
港大马毅谈智能史:DNA 是最早的大模型,智能的本质是减熵
港大马毅谈智能史:DNA 是最早的大模型,智能的本质是减熵而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。
来自主题: AI技术研报
11224 点击 2025-05-25 12:43