


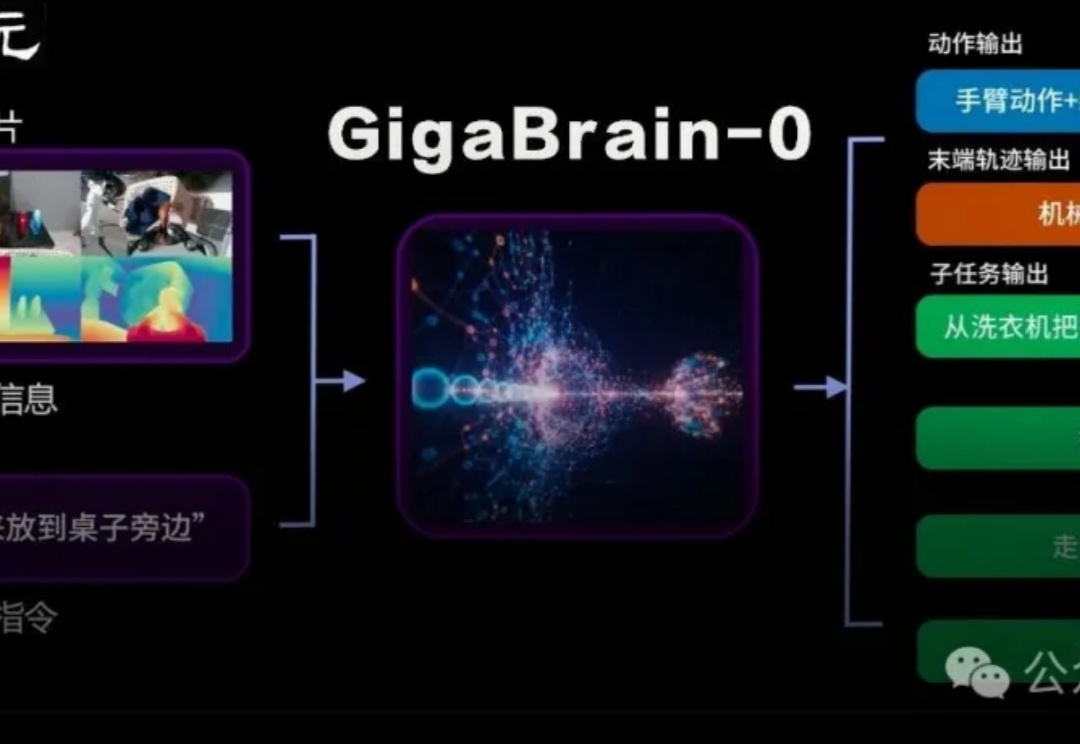
刚刚,最佳VLA模型GigaBrain-0开源:世界模型驱动10倍数据,真机碾压SOTA
刚刚,最佳VLA模型GigaBrain-0开源:世界模型驱动10倍数据,真机碾压SOTA国内首个利用世界模型生成数据实现真机泛化的端到端VLA具身基础模型GigaBrain-0重磅发布。
来自主题:
AI技术研报
6045 点击 2025-10-29 18:14
国内首个利用世界模型生成数据实现真机泛化的端到端VLA具身基础模型GigaBrain-0重磅发布。

全球首款开卖的家务人形机器人来了!

就像 Windows 或 macOS 为软件提供运行环境,Flowith OS 为 AI Agent 提供思考与行动的环境。Flowith 正式发布了一个全新的产品:名为 Flowith OS 的新物种。它选择了一个「另辟蹊径」的路径,尝试为 AI Agent 打造一个全新的 AI-Native 式的操作系统。

数字化浪潮重塑全球产业格局的进程中,人工智能应用的爆发式增长正以前所未有的力度重构生产力边界,而算力作为支撑这一变革的核心基础设施,其供需之间的紧张关系正逐渐成为影响产业持续升级的重要瓶颈。

“AI 将彻底改变游戏开发。”——类似的宣言,这几年几乎天天都能在社交媒体上看到。但最近,一位科技投资人用亲身示范告诉我们:AI 生成游戏的“未来”,可能还离“惊艳”很远,甚至更接近“恐怖谷”。

Sora 2的爆火,又一次让AI视频生成站在全球范围的大风口上。
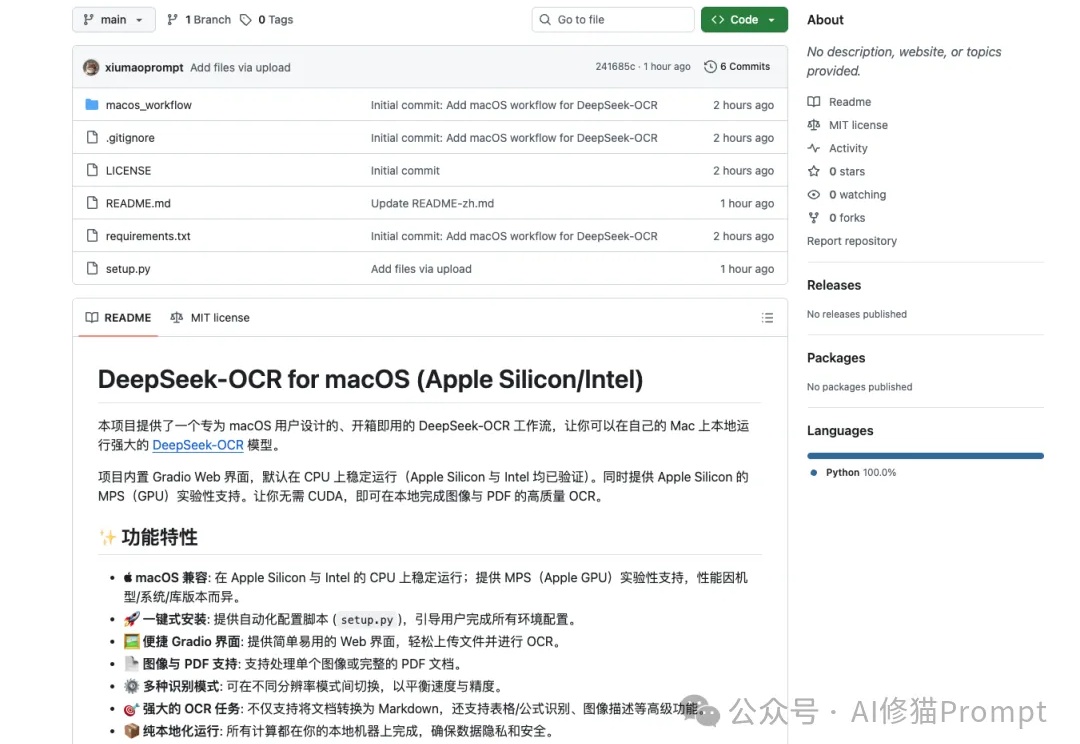
DeepSeek-OCR这段时间非常火,但官方开源的文件是“按 NVIDIA/CUDA 习惯写的 Linux 版推理脚本+模型权重”,而不是“跨设备跨后端”的通吃实现,因此无法直接在苹果设备上运行,对于Mac用户来说,在许多新模型诞生的第一时间,往往只能望“模”兴叹。

今年三月,Liam Fedus 在推特上宣布离开 OpenAI。这条推文的影响力超出了所有人的预期——硅谷的风投们几乎是立刻行动起来,争相联系这位 ChatGPT 最初小团队的核心成员、曾领导 OpenAI 关键的后训练部门的研究者,他的离职甚至一度引发了一场“反向竞标”。

AI风起云涌,数据隐私如履薄冰。华南理工大学联手深圳北理莫斯科大学,推出FedMSBA与FedMAR,筑成联邦学习的安全堡垒,守护个人隐私!
强化学习是近来 AI 领域最热门的话题之一,新算法也在不断涌现。
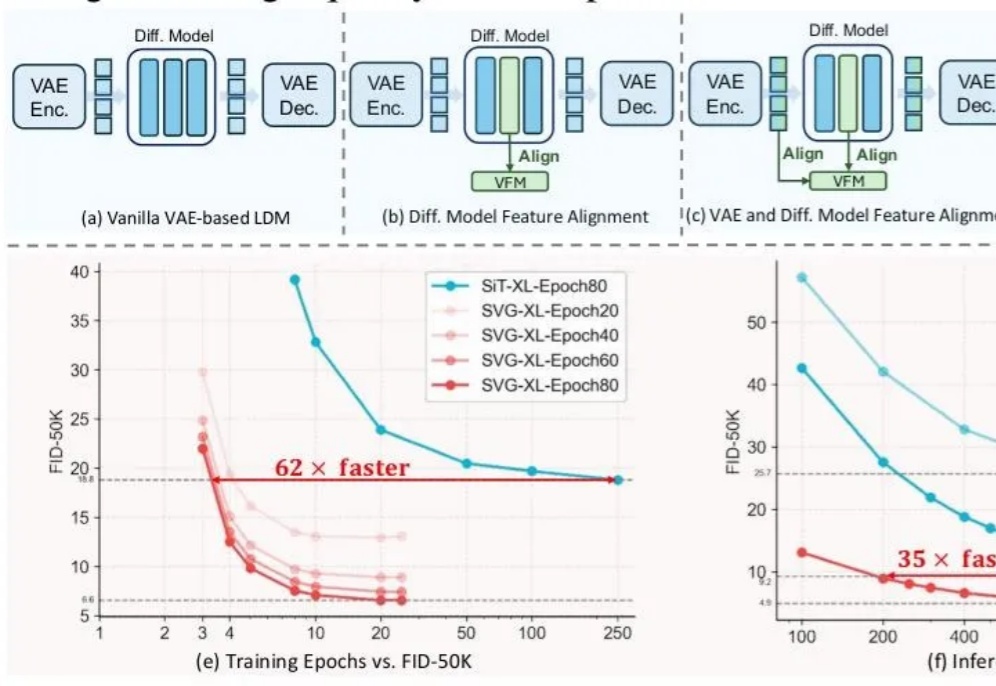
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
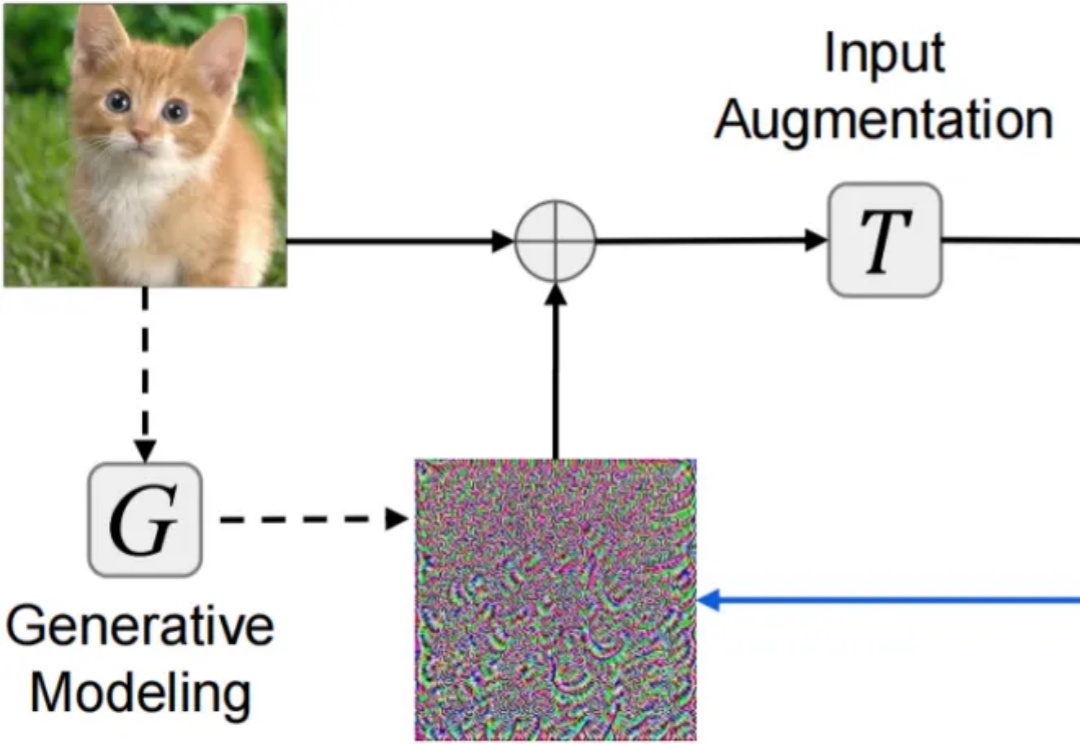
对抗样本(adversarial examples)的迁移性(transferability)—— 在某个模型上生成的对抗样本能够同样误导其他未知模型 —— 被认为是威胁现实黑盒深度学习系统安全的核心因素。尽管现有研究已提出复杂多样的迁移攻击方法,却仍缺乏系统且公平的方法对比分析:(1)针对攻击迁移性,未采用公平超参设置的同类攻击对比分析;(2)针对攻击隐蔽性,缺乏多样指标。

昨晚 11 点,绕了好几道弯,我终于找朋友拿到了 FlowithOS 的内测码。这款产品昨天在 X 上挺火的,很多人转发。 体验了大半天之后,我非常兴奋。相比 Manus,或者 OpenAI 最近发布
OpenAI完成史上最重要的一次组织架构调整后,紧接着开了一场直播。首次公开了内部研究目标的具体时间表,其中最引人注目的是“在2028年3月实现完全自主的AI研究员”,具体到月份。

在北京时间凌晨举办的英伟达 GTC 大会上,黄仁勋用一系列人类历史创新的剪影开场,并把英伟达与 AI 创新直接拔高定调为「下一个阿波罗时刻」。除了展示下一代超级芯片 Vera Rubin,黄仁勋还大谈 6G、量子计算,机器人和自动驾驶,同时宣布要投资新的巨头,舞台大屏上英伟达的「合作」对象名单可以说是密密麻麻。

Anthropic深夜又放猛招!Claude直接以插件形态接入Excel,不仅能直接操作和读取数据,还能定位单元格内容,并给出修改理由。

2025年10月29日凌晨,英伟达创始人兼CEO黄仁勋在华盛顿举行的GTC华盛顿特区技术峰会上发表重磅演讲。

今天要讲的On-Policy Distillation(同策略/在线策略蒸馏)。这是一个Thinking Machines整的新活,这个新策略既有强化学习等在线策略方法的相关性和可靠性;又具备离线策略(Off-policy)方法的数据效率。

刚刚,这样一个消息在 Reddit 上引发热议:硅谷似乎正在从昂贵的闭源模型转向更便宜的开放源替代方案。
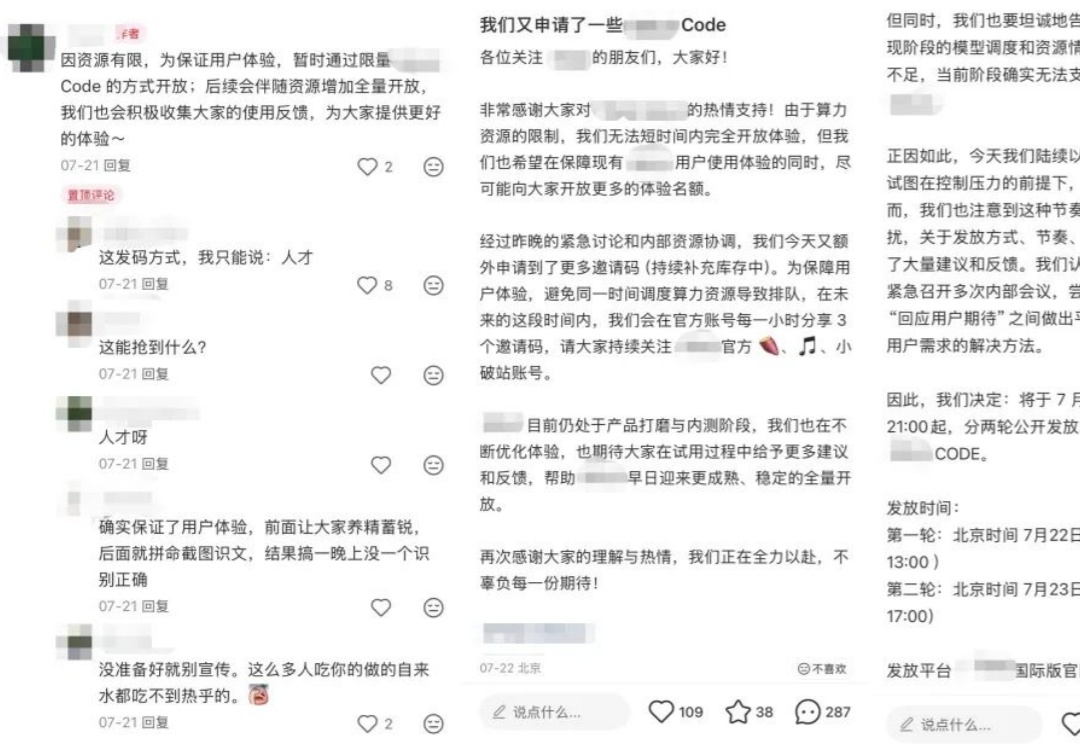
火爆只是表象,邀请码没这么厉害。
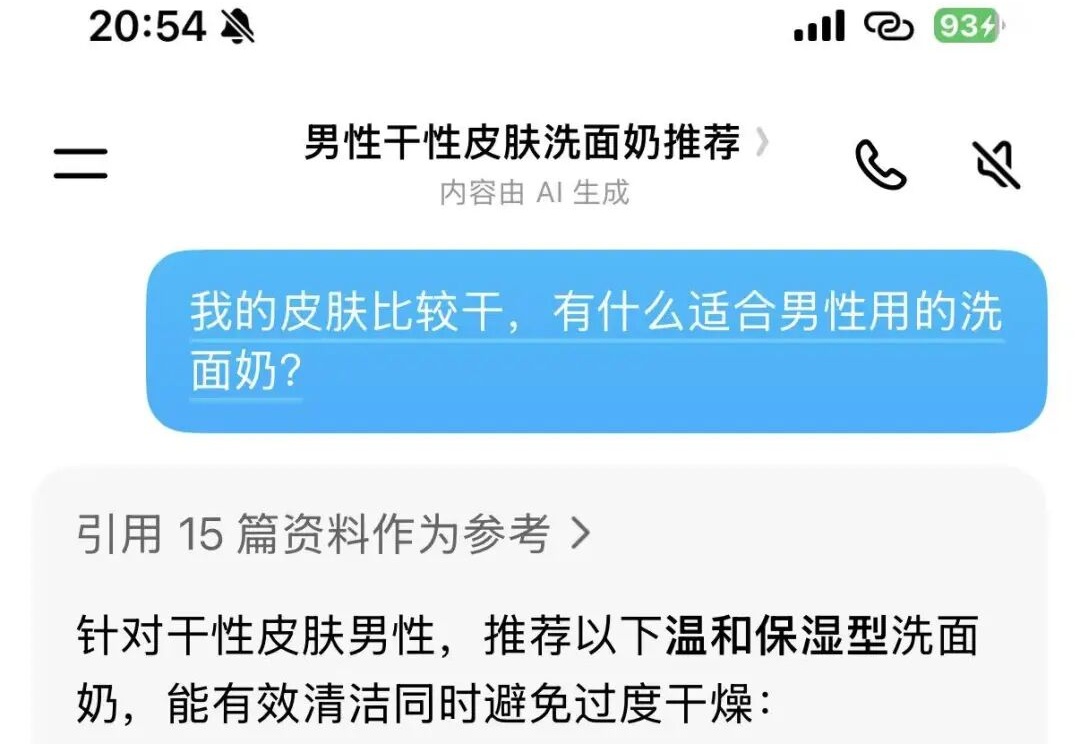
AI 带货,高级版摇一摇广告。

对于机器人来说,世界模型真的有必要想象出精确的未来画面吗?在一篇新论文中,来自华盛顿大学、索尼 AI 的研究者提出了这个疑问。

2025西岸国际科技消费嘉年华(WTCC)模速路演日,九方智投控股旗下科技公司九方智擎作为金融科技代表亮相,分享AI+投顾从工具到“有温度的投资伙伴”的产业升级。
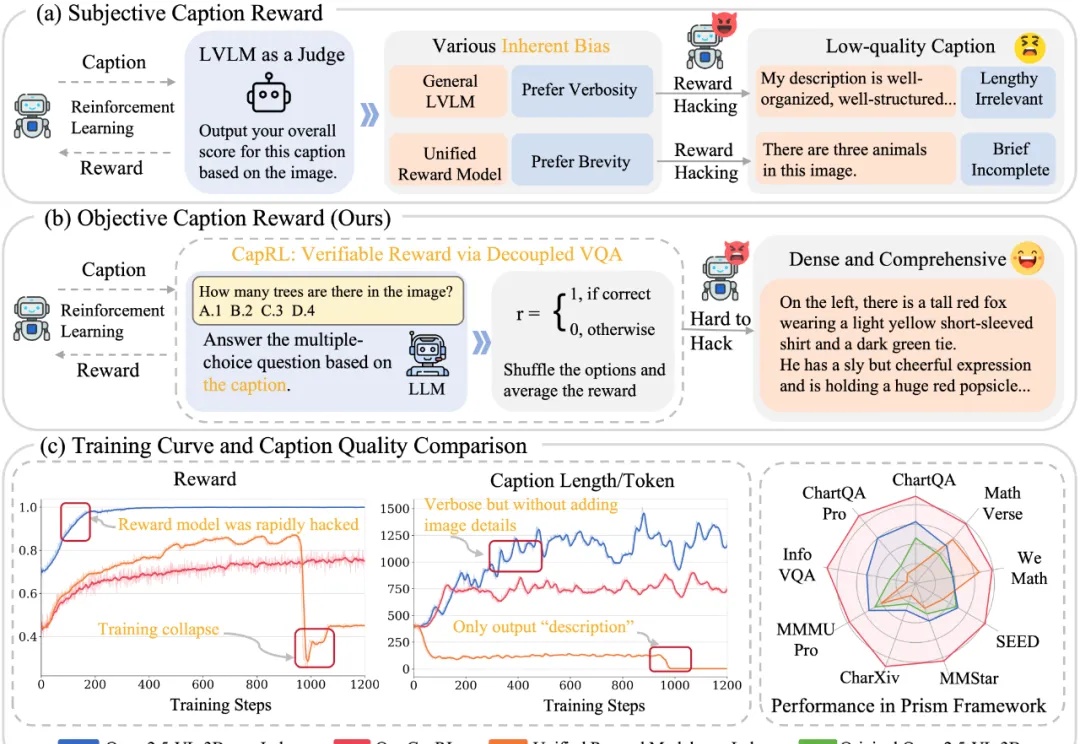
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。

大语言模型(LLMs)推理能力近年来快速提升,但传统方法依赖大量昂贵的人工标注思维链。中国科学院计算所团队提出新框架PARO,通过让模型学习固定推理模式自动生成思维链,只需大模型标注1/10数据就能达到全量人工标注的性能。这种方法特别适合像金融、审计这样规则清晰的领域,为高效推理监督提供了全新思路。

在当前评测生成式模型代码能力的浪潮中,传统依赖人工编写的算法基准测试集,正日益暴露出可扩展性不足与数据污染严重两大瓶颈。

在文化遗产与人工智能的交叉处,有一类问题既美也难:如何让机器「看懂」古希腊的陶器——不仅能识别它的形状或图案,还能推断年代、产地、工坊甚至艺术归属?有研究人员给出了一条实用且富有启发性的答案:把大型多模态模型(MLLM)放在「诊断—补弱—精细化评估」的闭环中训练,并配套一个结构化的评测基准,从而让模型在高度专业化的文化遗产领域表现得更接近专家级能力。

直到我看到 Dedalus Labs 宣布完成 1100 万美元种子轮融资的消息,才意识到有人正在系统性地解决这个问题。这家由 Cathy Di 和 Windsor Nguyen 创立的公司,正在构建一个基础设施层,让开发者能够用 5 行代码就搭建起一个功能完整的 AI agent。这不是夸张的营销话术,而是他们真正在做的事情。
刚刚,OpenAI宣布已完成资本结构重组。这就意味着,OpenAI上市的道路已经铺平,而软银前几天刚批准的225亿美元投资,也将顺利到账。具体来说,OpenAI重组后,非营利主体(即原本的OpenAI Nonprofit)改名为OpenAI Foundation,继续掌控营利实体——

蚂蚁集团这波操作大圈粉!智东西10月28日报道,10月25日,蚂蚁集团在arXiv上传了一篇技术报告,一股脑将自家2.0系列大模型训练的独家秘籍全盘公开。今年9月至今,蚂蚁集团百灵大模型Ling 2.0系列模型陆续亮相,其万亿参数通用语言模型Ling-1T多项指标位居开源模型的榜首

