


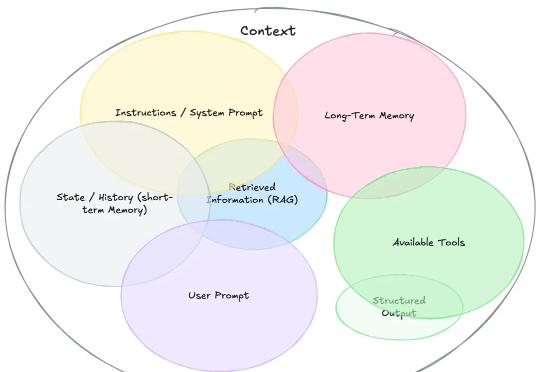
高质量「上下文工程」资源整理(含速览和精读)
高质量「上下文工程」资源整理(含速览和精读)上下文工程(Context Engineering)现在有多火,就不用多说了吧。
来自主题:
AI技术研报
10292 点击 2025-08-04 11:38
上下文工程(Context Engineering)现在有多火,就不用多说了吧。

长期以来,科学家(研究者)和工程师的角色定位泾渭分明。这种分野不仅存在于学术界,也深植于大众文化之中。比如在美剧《生活大爆炸》中,物理学家谢尔顿・库珀就时常以「真正的科学家」自居,对身为工程师的霍华德・沃洛维兹冷嘲热讽,两者的职业差异甚至成为该喜剧的重要素材。

这是一期真格基金管理合伙人戴雨森的访谈实录,也是2025年中,对于整个 AI 行业的一次半年度复盘。
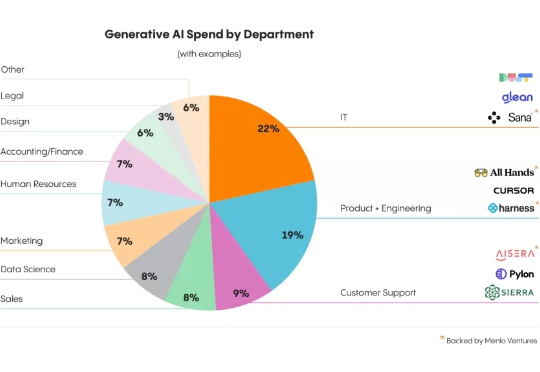
企业的生成式AI支出从2023年的23亿美元暴增至138亿美元,表明从试点阶段向规模化落地转变。超过70%的决策者预计生成式AI在短期内将被更广泛采用,日常工作中已广泛应用。
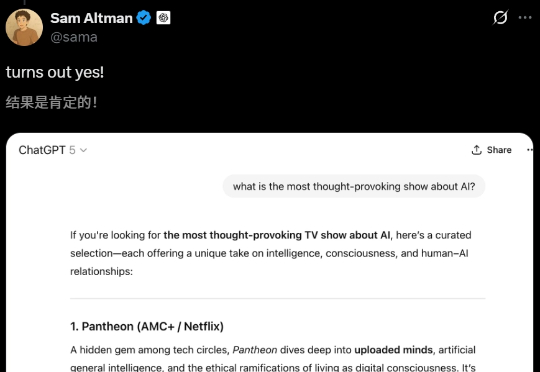
GPT-5真实回答场景曝光!在所有人都在等待GPT-5的时候,奥特曼「自导自演」了一个对话,想用GPT-5回答问题的截图「装波大的」。奥特曼当CEO有点屈才了,他太会营销了!
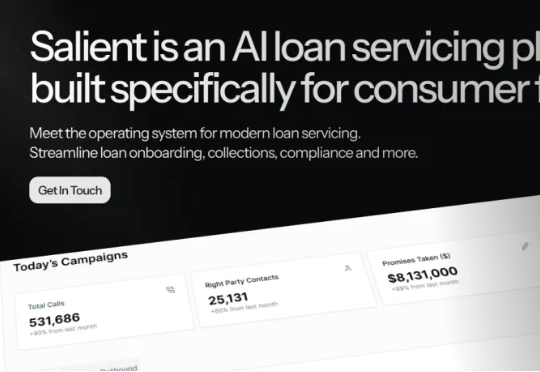
这家公司叫Salient,主打AI agents贷款服务,刚刚在A轮融资中筹集了6000万美元,折合人民币4.3亿元。此次融资由Andreessen Horowitz旗下的a16z领投,Matrix Partners、Michael Ovitz和Y Combinator跟投。
今天凌晨,马斯克再放大招更新Grok App。AI短视频30秒一键生成,真面对决谷歌Veo 3。刚刚,马斯克宣布:Grok Imagine今天开始向所有Grok Heavy用户推出。Grok iOS App升级,Imagine功能重磅升级!
最近整个 AI 圈的目光似乎都集中在 GPT-5 上,相关爆料满天飞,但模型迟迟不见踪影。昨天我们报道了 The Information 扒出的 GPT-5 长文内幕,今天奥特曼似乎也坐不住,发了推文表示「惊喜很多,值得等待」。

你有没有想过,为什么大部分人在谈论AI的时候还在纠结ChatGPT能写多少字、回答多少问题,而有些人已经在用AI创造出让你分不清真假的视频内容?当全世界还在为文本生成AI争论不休时,一家名为fal的公司却在悄然重塑整个内容创作的基础设施。
拒绝小扎10亿刀报价的哥们儿,被挖出来了—— Andrew Tulloch,OpenAI前CTO Mira创业搭子,参与了OpenAI GPT-4o到o系列的研发,还曾在Meta工作过11年。

研究人员分析了20万条AI对话、整合了近3万项职业任务数据,通过计算覆盖率、成功率和影响范围三个维度,为每个职业算出了AI适用性分数。

创业,认知要领先,拼命地执行。 过去两年,字节跳动有不少业务高管离职,选择在AI领域创业。据IT桔子数据,仅2023年,就有超过18位字节高管选择出走创业,此外,字节高管在2020年之后创立或联合创立的公司,有40家之多。

7月26日,在世界人工智能大会(WAIC)上,中国移动正式发布了MoMA多模型与智能体聚合及服务引擎。

苹果CEO蒂姆·库克在内部大会上激励员工,强调AI革命与互联网和智能手机同等重要,苹果虽起步晚但将投资创新。Siri正被全面重做,明年春季发布新版本;公司招聘12000人加强研发,开发AI服务器芯片“Baltra”;全球扩张聚焦新兴市场;库克预告折叠iPhone等新产品,表示未来充满机会。

Arm宣布下场自研芯片,突破传统IP授权模式,计划将计算子系统(CSS)方案转化为实体芯片销售,首先瞄准高利润数据中心市场。此举打破与客户中立关系引发竞争担忧,旨在追求更高利润、展示技术潜力及抢占AI浪潮机遇。

理想最新纯电车型 i8 发布会上,创始人李想花费大量篇幅介绍车机的智能化,以及 VLA 技术下的智驾进化。 遥想上半年李想的「AI Talk」直播,在让人想夸一句「厂长实在是太想进步了」之外,不得不说马斯克对于「特斯拉从汽车公司」、「新能源公司」再到「AI 公司」的定位,对同行们的影响还是有点大了。

通过AI,我们已经可以创造出具备迷人外表、动人声音与善解人意语言能力的“智能存在”——形象、语言、陪伴,都已不再是幻想。最近,号称“地表最强AI”的Grok进行了一次重要更新。与以往不同,这次更新的重点并非提升模型的“智力”,而是专注于增强其情感能力。在此次更新中,Grok首次引入了“伴侣”(Com-panions)功能,允许用户创建拥有定制声音、外观和个性的AI伴侣。
主打“自动化执行、多模型调用、上下文记忆”的 AI 编程应用大热,但运行卡顿、资源消耗惊人、推理成本过高等问题也随之而来。
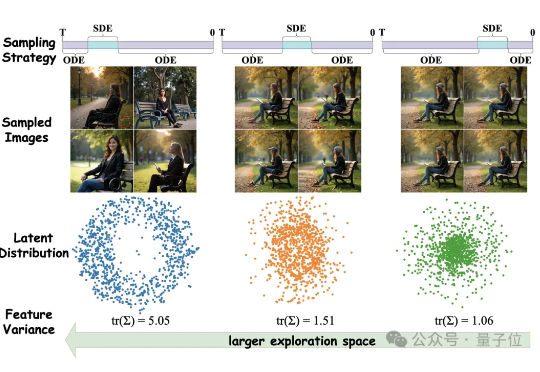
图像生成不光要好看,更要高效。 混元基础模型团队提出全新框架MixGRPO,该框架通过结合随机微分方程(SDE)和常微分方程(ODE),利用混合采样策略的灵活性,简化了MDP中的优化流程,从而提升了效率的同时还增强了性能。

n8n成立于2019年,已集成400多个第三方应用,支持自托管,拥有23万活跃用户(含3000家企业),代码库位列GitHub全球Top 50。区别于Zapier等传统SaaS平台,n8n采用“按工作流计费”+“支持自定义与本地部署”的模式,以“connect anything to everything”为理念,是高性价比和数据控制的开源自动化平台。
据彭博社消息,人工智能初创公司 Anaconda 在新一轮融资中估值达到 15 亿美元。这家为开发者和数据科学家提供 AI 开发工具的公司计划于本周宣布,本轮融资额超过 1.5 亿美元。
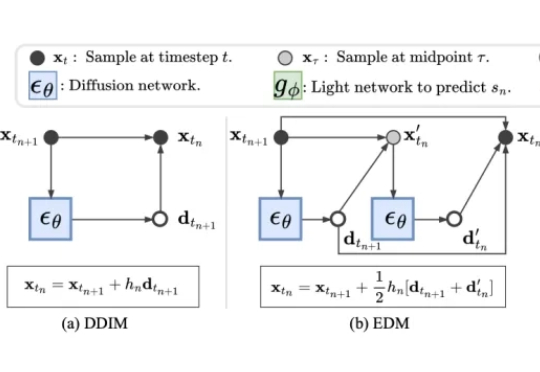
近年来,扩散模型(Diffusion Models)凭借出色的生成质量,迅速成为图像、视频、语音、3D 内容等生成任务中的主流技术。从文本生成图像(如 Stable Diffusion),到高质量人脸合成、音频生成,再到三维形状建模,扩散模型正在广泛应用于游戏、虚拟现实、数字内容创作、广告设计、医学影像以及新兴的 AI 原生生产工具中。

外卖平台补贴大战结束,美团、淘宝、京东转而聚焦AI投资,尤其在具身智能领域(机器人)。巨头面临硬件自研困境,多通过投资机器人公司协同创新,而非内部孵化。京东侧重提升物流仓储效率,美团覆盖本地生活场景,阿里专注大模型与智能中枢。这源于外卖市场饱和与低估值压力,巨头寻求新技术突破以创造增量。
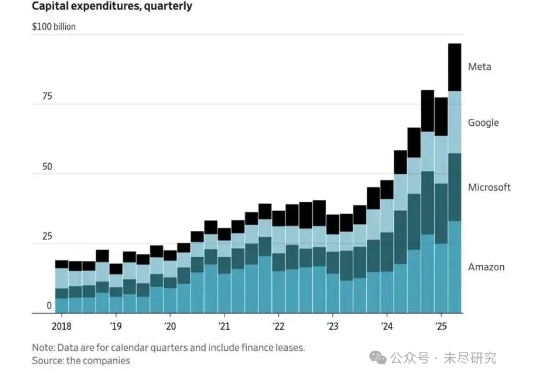
下半年刚开始,美国AI达到了一个新的高潮。继英伟达的市值超过4万亿美元之后,微软的市值也一度突破了4万亿美元。美国四大AI巨头的资本支出,各自都将达到每年上千亿美元。美国的AI独角兽企业的估值,达到数千亿美元。AI原生企业的年化收入突破百亿美元。硅谷挖一个AI顶级人才,价码飙到了10亿美元。
2025年的IMO,好戏不断。 7月19日,全世界顶尖大模型在2025年的IMO赛场上几乎全军覆没。时隔1天,OpenAI、DeepMind等顶尖实验室就在IMO 2025赛场斩获5/6题,震惊数学圈。

AI科学发现公司Autopoiesis Sciences宣布,其人工智能联合科学家Aristotle X1 Verify在多项基准测试中取得了显著成果,性能超越了所有主流AI模型。据悉,Aristotle X1 Verify在推理基准测试GPQA Diamond中达到了92.4%的准确率
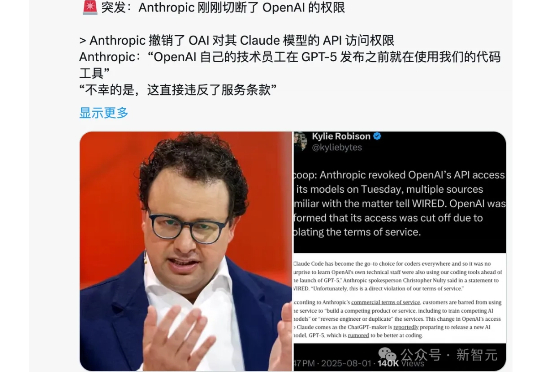
Anthropic突封OpenAI的ClaudeAPI,指其违约用Claude支援即将发布的GPT-5开发及安全测试。此举标志AI巨头围绕数据与接口展开新一轮封锁战,API成市场准入与创新博弈的战略资源,在业内引发热议与监管关注。

无需谷歌“钞能力”,两位清华校友强强联合,直接让基础模型Gemini 2.5 Pro轻松达到IMO金牌水平。

GPT-5,曾经差点难产?这条诞生路,简直是烈火炼真金。一边是人才出走、小扎截胡、团队内部陷入混乱,另一边,推理模型魔咒让研究者苦恼不已,项目甚至一度停摆。外媒曝出这期GPT-5诞生内幕,可谓亮点满满,干货十足。

“两次 CPU 飙升的背后有个巧合,那就是——‘我们 CEO 登录了账号。’于是,我们把 CEO 的账号给封了,继续排查原因......” 听起来像段子,但这真是 Sketch.dev 的工程师亲口写下的“事故总结”。而这一切的起因,只是因为一段由 AI 生成的代码。

