



大模型竞赛转向:决胜关键为何是“后训练”?
大模型竞赛转向:决胜关键为何是“后训练”?随着基础大模型在通用能力上的边际效益逐渐递减、大模型技术红利向产业端渗透,AI的技术范式也开始从原来的注重“预训练”向注重“后训练”转移。后训练(Post-training),正从过去锦上添花的“调优”环节,演变为决定模型最终价值的“主战场”。
来自主题:
AI技术研报
8626 点击 2025-07-20 12:30
随着基础大模型在通用能力上的边际效益逐渐递减、大模型技术红利向产业端渗透,AI的技术范式也开始从原来的注重“预训练”向注重“后训练”转移。后训练(Post-training),正从过去锦上添花的“调优”环节,演变为决定模型最终价值的“主战场”。
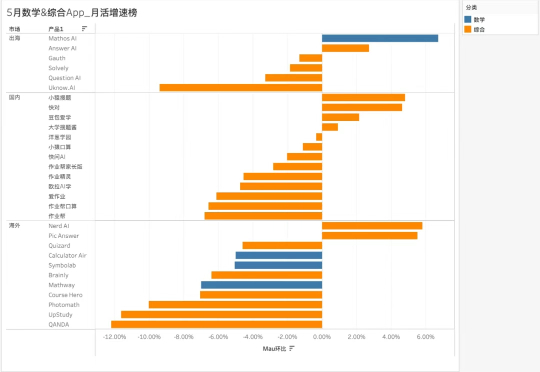
白鲸出海联合点点数据、非凡产研发布第 6 期全球 AI 教育产品榜(包含 App 和 Web 端,前 5 期可参考底部推荐文章)。本期我们延续上一期,将 5 大分类归类为语言学习、数学&综合、学习/教学工具&儿童教育(目前这 2 类产品较少暂归在一起),三大板块进行分析,但具体产品的分类标准与往期一致。
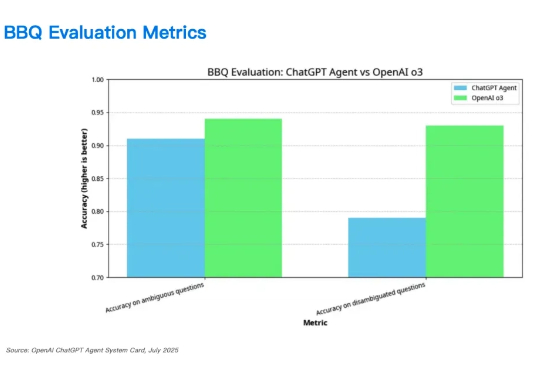
这应该是上线以来案例最少的 Agent 了,OpenAI GPT Agent奥特曼你不给我用,就别怪我用 Manus 跟你硬碰硬了。
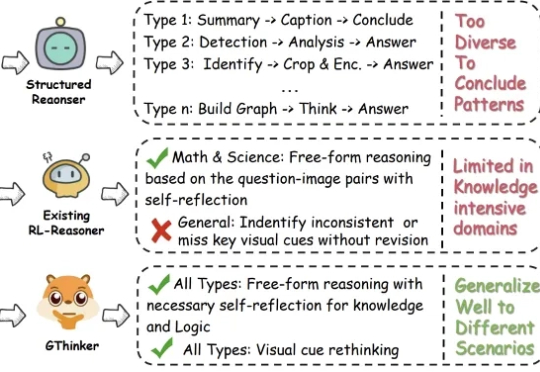
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。

程序员最有价值的技能已经不再是编写代码了,而是精确地向 AI 传达意图。一份完善的规范才是包含完整意图的真正「源代码」。

在 Web 端 AI 产品中,ChatBot 仍然牢牢占据访问量的主导地位,「DeepSeek」、「豆包」与「通义」位列榜单前三,构成头部竞争格局。然而,这一阵营内部也开始显现出明显的分化趋势。

本来还觉得今天OpenAI开发布会,这篇昨晚提前写完的稿子发不了了,要给ChatGPT Agent让路,结果,果然,OpenAI又拉了。。。还是聊聊AI硬件吧。最近花了1500,又买了一个录音这块的AI硬件,TicNote。

只需一段视频,就可以直接生成可用的4D网格动画?!来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。
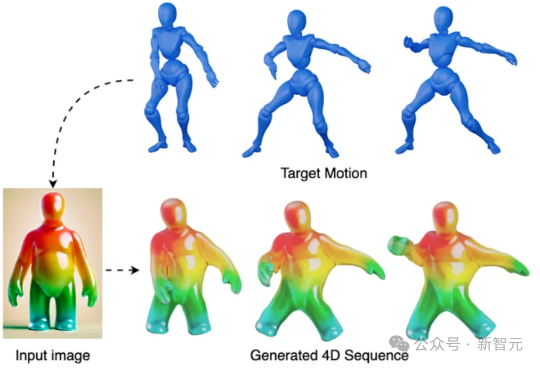
PhysRig是UIUC与Stability AI联合提出的首个面向角色动画的可微物理绑定框架。通过将刚性骨架嵌入弹性软体体积,并使用Material Point Method(MPM)进行可微分物理模拟,PhysRig能够自然还原皮肤、脂肪、尾巴等柔性结构的变形过程,显著提升角色动画的真实感,解决传统LBS无法克服的体积丢失与变形伪影问题。
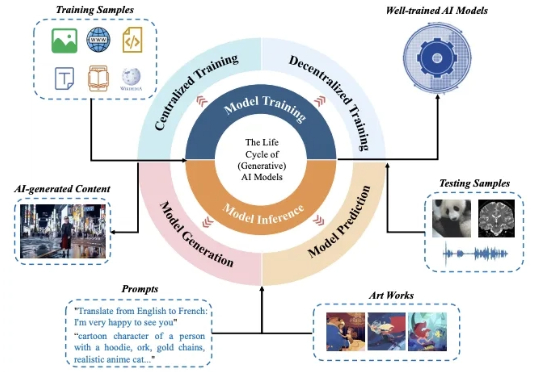
你是否也曾担心过,随手发给 AI 助手的一份代码或报告,会让你成为下一个泄密新闻的主角?又或是你在网上发布的一张画作,会被各种绘画 AI 批量模仿并用于商业盈利?
OpenAI通用推理模型在国际奥数竞赛中达到金牌水平,解出5题得分35/42。模型通过新技术实现长时间复杂推理和自然语言证明,非专用系统。标志AI在创造性思考和科学研究的重大突破,为解决千年难题铺路。GPT-5即将发布但暂缺此能力。

世界首个实时AI扩散视频模型炸场,Karpathy亲自站台,颠覆AI视频交互,0延迟+无限时长,每秒24帧不卡顿,MirageLSD首次实现AI直播级生成。

Apple Intelligence 进入新的一章。 近日,苹果发布了 2025 年 Apple Intelligence 基础语言模型技术报告。

病理诊断,是AI改变医疗的关键环节。近年来,癌症诊断需求不断增长,随之而来的是病理科巨大的供给挑战。
「硅谷最贵华人」庞若鸣昔日老将Mark Lee与Tom Gunter加入Meta!扎克伯格亲自挂帅,誓补AI人才与算力短板。苹果深陷人事动荡。AI战局愈演愈烈,硅谷风云再起。

成立仅8个月已成为最新独角兽,估值飙升至18亿美元。 目前已拥有超230万免费活跃用户、18万付费订阅者,付费用户首月留存率甚至已超ChatGPT。

在爆火仅四个月后,Manus AI 突然几乎全面撤出中国市场,不仅清空全部社交账号内容,而且国行版本的 Manus 也疑似暂停推进。
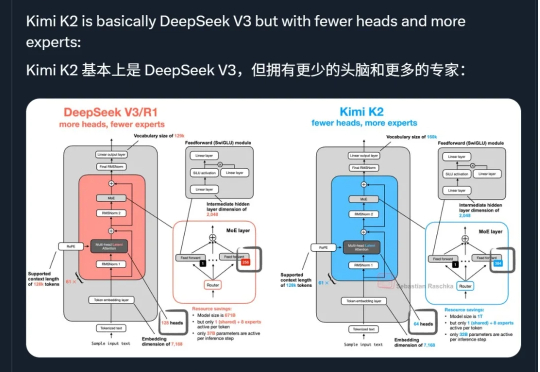
几千人盲投,Kimi K2超越DeepSeek拿下全球开源第一!
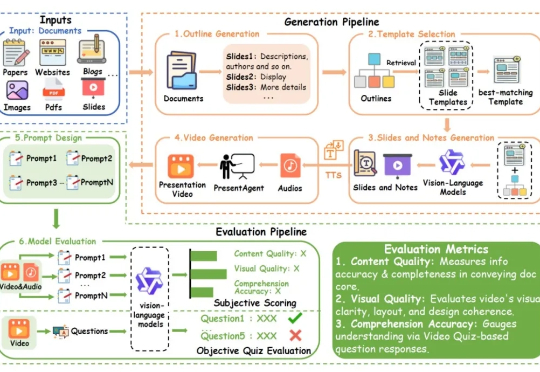
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。

还在为发了广告没人点击而烦恼吗?还在纠结为什么花费巨资投放的数字营销效果越来越差吗?现实是,传统的营销漏斗已经彻底坍塌了。今天的消费者,特别是Gen Z和Gen Alpha,他们发现产品的方式已经完全改变:不再通过搜索引擎或者广告,而是通过TikTok的滚动浏览、Reddit的搜索,或者网红的推荐。
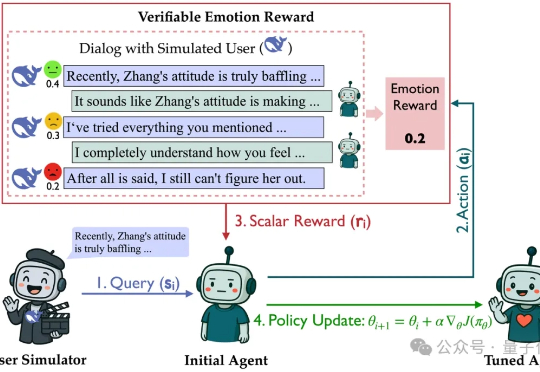
在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
Manus 团队刚分享了他们构建 Agent 的 Context 工程经验。刚好我在自己读的过程中,对全文进行了精校翻译,并高亮要点与排版。来自一线的分享,总共 6 条经验,共 5K 字。

在全球这场10万亿美元的AI技术革命中,新加坡正在成为关键节点。“在新加坡,有参加不完的AI 聚会。”Linkda创始人黄琳在新加坡创业10多年,近两年服务了数百家出海新加坡的中国企业,其中1/3是AI初创公司。
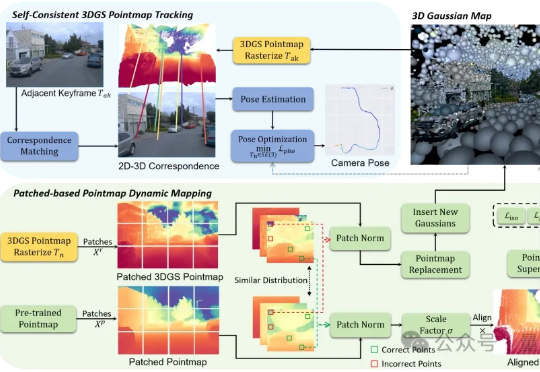
户外SLAM的尺度漂移问题,终于有了新解法! 香港科技大学(广州)的研究的最新成果:S3PO-GS,一个专门针对户外单目SLAM的3D高斯框架,已被ICCV 2025接收。

AI永生,迟早比人更聪明!Hinton惊人预言:开发超级智能,就是与虎为伴,稍有不慎,人类万劫不复!
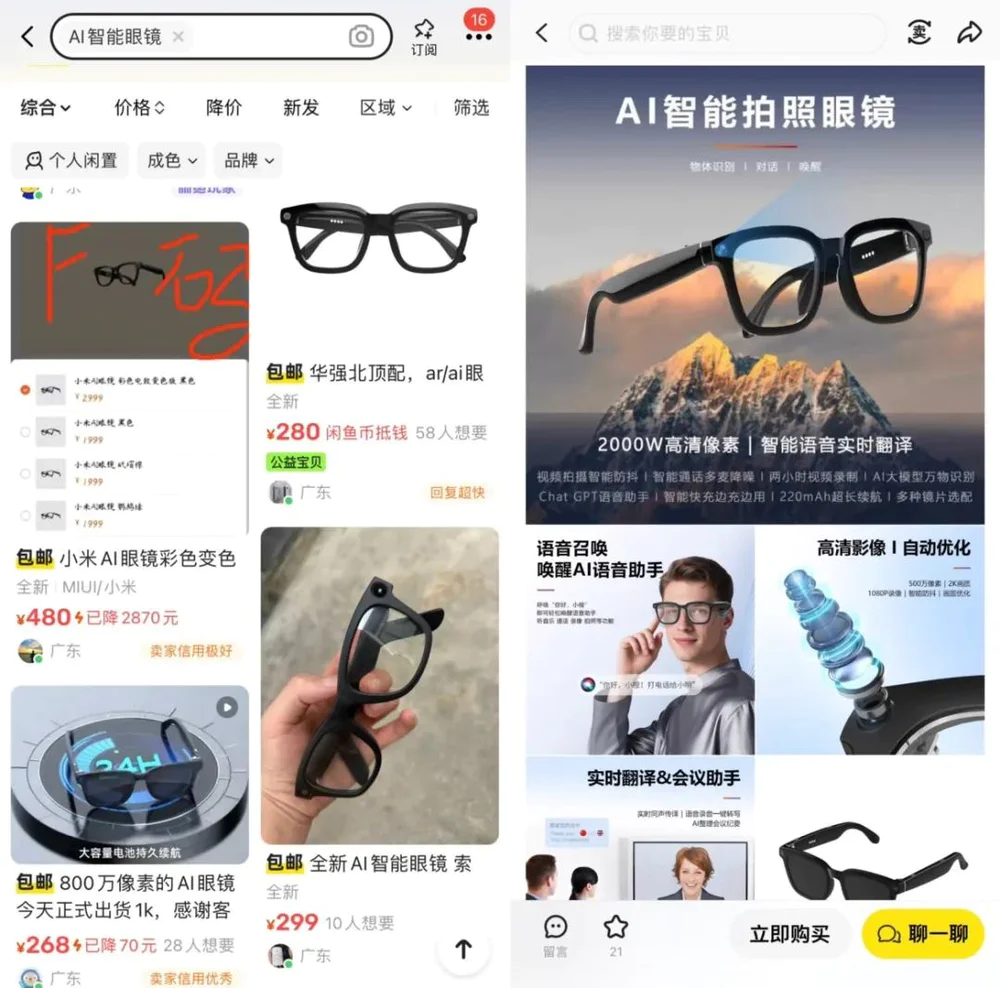
华强北推出低价AI眼镜,价格78-450元,截胡小米、Rokid等巨头产品。产品分为AI拍摄眼镜和AI音频眼镜,功能基础但销量火爆,月均数千台。厂商快速组装出货,靠价格优势和即买即得吸引消费者尝鲜,性能虽逊但性价比高。行业前景存疑,技术成熟需5年,海外市场更受欢迎。

最近,一条魔性视频在X(推特)上火了。效果be like:创意很抽象,但不得不说视频效果很惊艳。丝滑的动作、流利的口条以及整体的合成效果……有3D大片那种感觉了。如此效果,基于一个AI创意引擎实现——Creati。
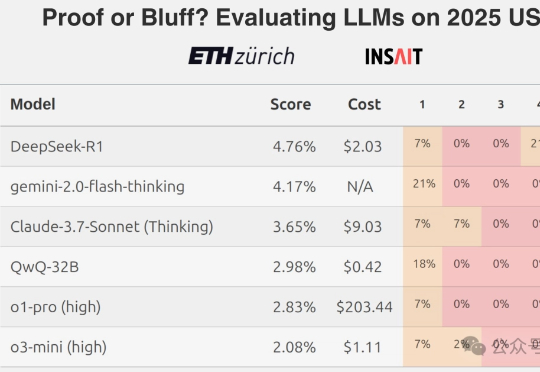
AI做奥数的神话,刚刚被戳破了!最新出炉的2025 IMO数学竞赛中,全球顶尖AI模型无一例外翻车了。即便是冠军Gemini也只拿下可怜的31分,连铜牌都摸不到。Grok-4更是摆烂到底,连DeepSeek-R1都令人失望。看来,AI想挑战人类奥数大神,还为时尚早。

扎克伯格哐哐哐挖人,现在算是大概清楚了。就在Meta内部一系列组织调整后,全新的架构正在初步浮出水面。不过不看不知道,一看真是哪里见过……

“他们这和偷有什么区别?”原创插画师张某发现,网络平台上有人将自己的作品通过AI软件进行细微篡改,然后做成拼图销售。因为拼图与原图看上去“如出一辙”,让许多消费者误以为是正版。张某起诉侵权人并要求下架侵权商品。

