2025 IMO真题撕碎AI数学神话,全球顶尖模型齐翻车!冠军铜牌都拿不到
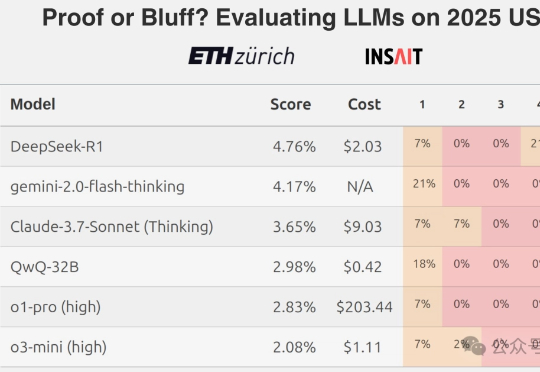
2025 IMO真题撕碎AI数学神话,全球顶尖模型齐翻车!冠军铜牌都拿不到AI做奥数的神话,刚刚被戳破了!最新出炉的2025 IMO数学竞赛中,全球顶尖AI模型无一例外翻车了。即便是冠军Gemini也只拿下可怜的31分,连铜牌都摸不到。Grok-4更是摆烂到底,连DeepSeek-R1都令人失望。看来,AI想挑战人类奥数大神,还为时尚早。
来自主题:
AI资讯
8632 点击 2025-07-18 17:37