



先解行为,再训Agent:CMU开源首份Agentic Search日志数据,把Agent拆开给你看
先解行为,再训Agent:CMU开源首份Agentic Search日志数据,把Agent拆开给你看在大模型驱动的 Agentic Search 日益常态化的背景下,真实环境中智能体 “如何发查询、如何改写、是否真正用上检索信息” 一直缺乏系统刻画与分析。
来自主题:
AI技术研报
8538 点击 2026-02-09 14:55
在大模型驱动的 Agentic Search 日益常态化的背景下,真实环境中智能体 “如何发查询、如何改写、是否真正用上检索信息” 一直缺乏系统刻画与分析。

上映于2013年的《Her》,是焦可最喜欢的一部电影。影片中的AI Samantha没有脸、没有形象,人们能感知的,只有她温柔沉静的声音。当Samantha说出,“最近你经历的事情太多了,你失去了一部分的自己”,男主角潸然泪下。

是时候打破运动行业的「苦难叙事」了。 做一款 AI native 的运动手表,会有多少想象空间?

"我最初装上Codex时说,绝不会让它完全控制我的电脑。这句话大概坚持了两小时。"OpenAI CEO Sam Altman在Cisco AI Summit上坦承,自己现在用两台笔记本电脑工作——一台
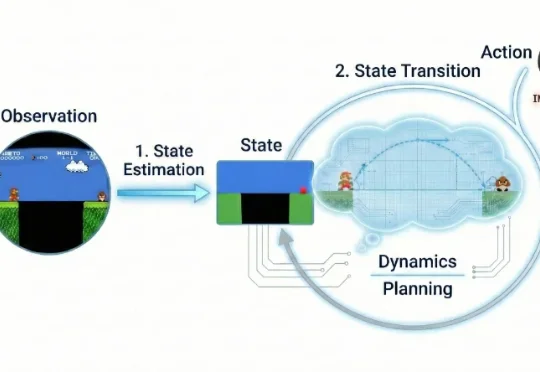
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
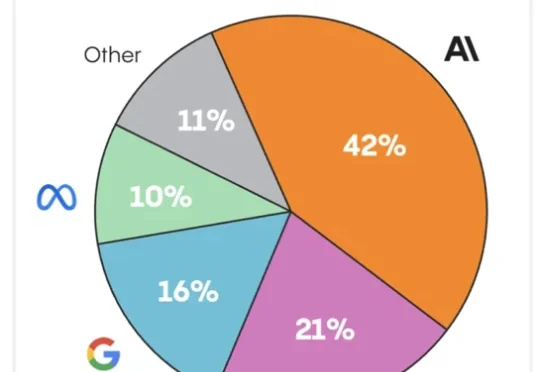
直到OpenAI发布GPT3.5的第3年后,人们才好像恍然意识到:AGI 的 A 其实有可能是Anthropic。

很多人都没注意到,谷歌悄悄放了一个大招,既不是 Gemini 也不是 nano banana pro,而是一份报告。这份报告调研了全球 3446 名企业高管(这些企业年营收都不低于 1000 万美元,不是小卡拉米)。
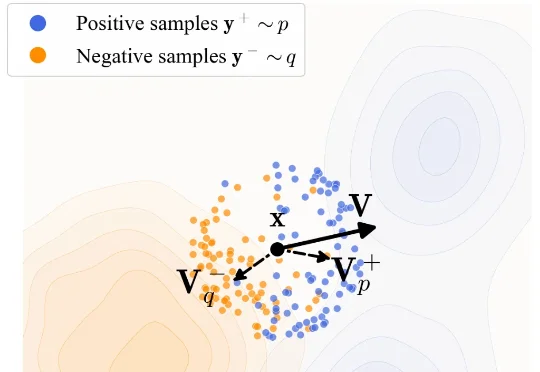
训练一个生成模型是很复杂的一件事儿。 从底层逻辑上来看,生成模型是一个逐步拟合的过程。与常见的判别类模型不同,判别类模型通常关注的是将单个样本映射到对应标签,而生成模型则关注从一个分布映射到另一个分布。

初创公司 Xmax AI 推出的首个虚实融合的实时交互视频模型 X1,没有复杂的 Prompt,不需要漫长的渲染等待,只需要手势进行交互,就可以让虚拟世界与现实相连,在镜头中令「幻想」成真,让用户体验到实时交互的心流体验。

Claude,堪称AI界「老油条」。这不,沃顿商学院Ethan Mollick教授发现,Claude Opus 4.6会自主决定「思考」时间。只要不涉及编程、数学的任务,哪怕是再难的问题,干活主打一个「偷工减料」。

大规模表格模型(LTM)而非大规模语言模型(LLM)的 Fundamental 公司 Nexus 模型,在多个重要方面突破了当代人工智能实践。该模型具有确定性——即每次被询问相同问题时都会给出相同答案——且不依赖定义当代大多数人工智能实验室模型的 Transformer 架构 。
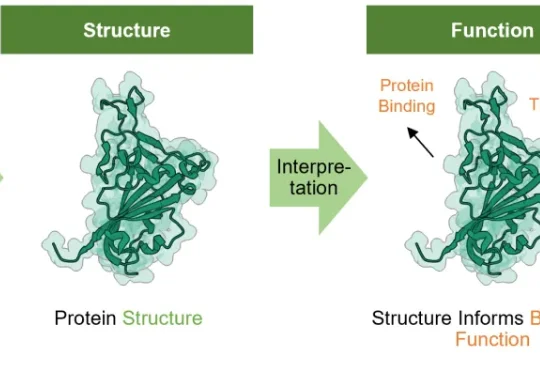
在生物基石模型的全球激烈竞逐中,IntelliGen AI 于本周末正式发布了 IntelliFold 2,这是继 2025 年 7 月 IntelliFold 首版发布后的一次重大升级 [2]。

Aishwarya Naresh Reganti 和 Kiriti Badam 曾在 OpenAI、Google、Amazon、Databricks 等公司参与构建并成功推出了 50 多个企业级 AI 产品。最近,他们在播客节目中,与主持人 Lenny 细致分享了当前 AI 产品开发中的常见陷阱与成功路径。基于该播客视频,InfoQ 进行了部分删改。
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?
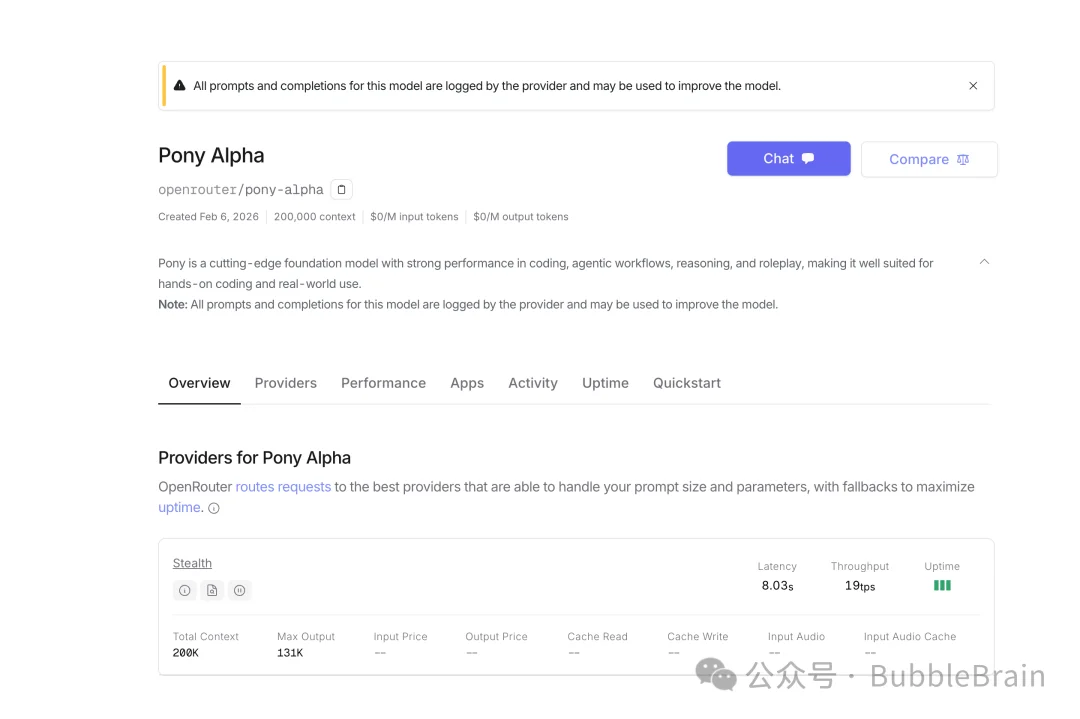
这周真的特别期待,应该可以看到各路厂商神仙打架。这股战火,从周末就开始了。 除了字节发布的Seedance2.0以外,还有个神秘的模型Pony Alpha 也上线到OpenRouter了,已经看到很多网友们纷纷猜测到底是谁家的模型。

就在刚刚,智元机器人举办了全球首个机器人晚会《机器人奇妙夜》。200 多台机器人在台上唱歌、跳舞、打太极,甚至还演小品、变魔术。讲真,春晚年年看,但含人量几乎为 0 的机器人专场,这还真是人类历史上头一遭。
在今天,我可以拍着胸脯说,OpenAI的Codex+GPT-5.3-codex,就是你最佳的入门、进阶、毕业的一条龙产品。你要相信我,愚钝如我,也能在它上面感受到进入心流的爽感,一个周末用它,解决了我四五个过去我完全一个人无法实现的开发需求。

27岁独立开发者靠它月入数万,前市场经理睡觉时它写邮件赚钱,柏林辍学生卖自定义技能赚12.7万美元——AI智能体的「iPhone时刻」已来,只是钱还没平均分。

OpenAI 的硬件产品,真的要来了,但可能会是个「阉割版」。据智慧皮卡丘最新爆料,OpenAI 首款面向消费者的 AI 耳机命名将定为「Dime」(即 10 美分硬币),大概也是形容其极度小巧精致。
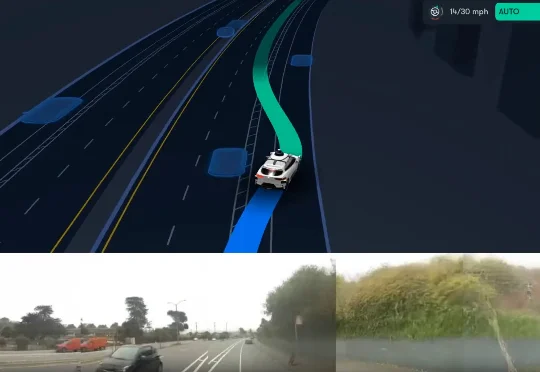
刚刚,Alphabet 旗下的自动驾驶汽车公司 Waymo,推出了最新世界模型 Waymo World Model,其基于 DeepMind 的 Genie 3 构建,在大规模、超真实自动驾驶仿真方面树立了全新的行业标杆。

短短一周,AI 就让硅谷科技股经历了两次「大屠杀」。 Claude Cowork 让软件股一天内市值蒸发近 2580 亿美元(折合人民币 19785.13 亿元)。

梦瑶 发自 凹非寺 量子位 | 公众号 QbitAI 不是,谁也没跟我说今年的AI春节大战搞得这么猛猛猛啊!?! 年还没到呢,可灵就超绝不经意甩出一个「过大年计划」:推出可灵3.0多模态全家桶。 让每
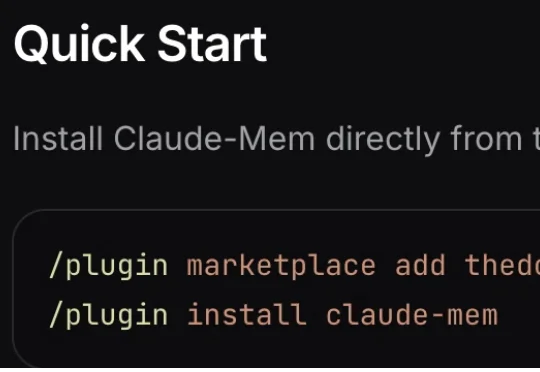
用Claude Code写代码的人,终于不用每次开新会话都从头解释项目背景了。顶GitHub开源热榜的一款持久化记忆系统Claude-Mem,直击AI编程助手最致命的痛点:跨会话失忆。
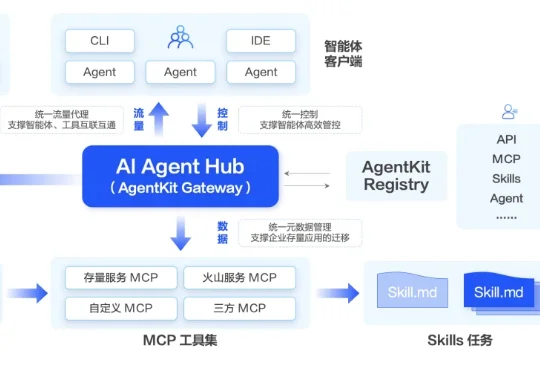
编辑|杨文、Panda 最近,OpenClaw 火得一塌糊涂。 短短几天,这个顶着红色龙虾 Logo 的开源 AI 助理 OpenClaw,就在 GitHub 上斩获超 16 万 star 量。 它就

一场AI春晚,浓缩海淀AI生态。 作者 | 王涵 编辑 | 漠影 在北京海淀区,你很容易产生一种“时空错位感”。 走在街头,擦肩而过的大学生讨论的是最新文献;走进咖啡厅,邻座对着电脑屏幕专注地敲着代码

目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?
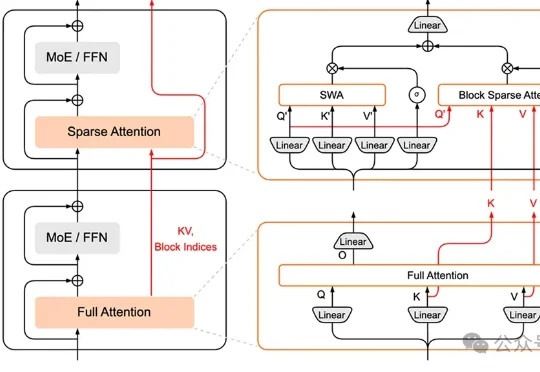
小米MiMo大模型团队,加入AI拜年战场——推出HySparse,一种面向Agent时代的混合稀疏注意力架构。

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务

LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混
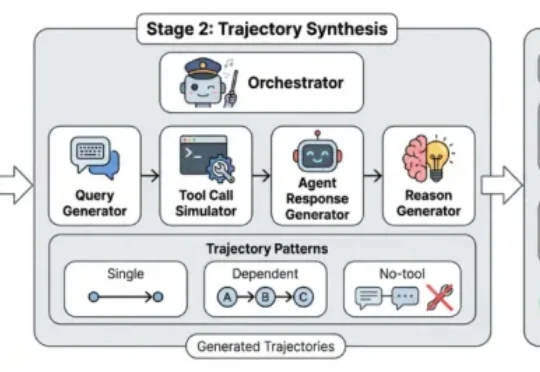
随着 AI 智能体(Agent)能力日益强大,其自主行为带来的安全风险也愈发复杂。现有安全工具往往只能给出「安全 / 不安全」的简单判断,无法告知我们风险的根源。为此,上海人工智能实验室正式开源 Ag

