



“AI提高了我的生产力,但我更累了”
“AI提高了我的生产力,但我更累了”“AI提高了我的生产力,但我却更累了……”最近一篇名为《AI疲惫是真实存在的,但却无人提及》的文章在论坛里爆火,引发了广大开发者的共鸣:
来自主题:
AI资讯
7987 点击 2026-02-10 14:25
“AI提高了我的生产力,但我却更累了……”最近一篇名为《AI疲惫是真实存在的,但却无人提及》的文章在论坛里爆火,引发了广大开发者的共鸣:

这两天,AI 视频圈被偷摸摸上线的 Seedance 2.0 刷屏了。在 AI 视频领域颇有影响力的博主海辛,在即刻分享了自己对它的观点:「Seedance 2.0 是我 26 年来最大的震撼」、「我觉得它碾压 Sora2」。

2026 年,那么多机器人上春晚,能给大家表演个包饺子吗?相信这是很多人会好奇的一个问题。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
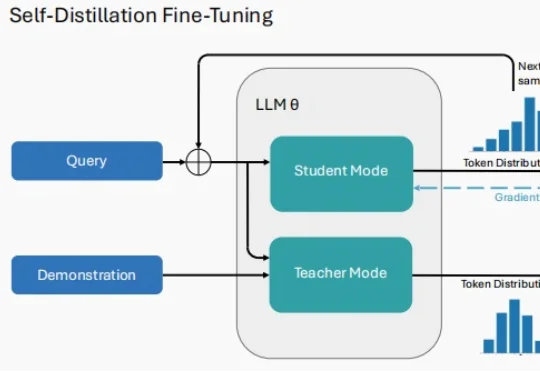
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。
去年11月,奥地利独立开发者Peter Steinberger花了一个小时,把Claude的API接上WhatsApp,做了一个能通过聊天软件操控电脑的AI助手。他当时觉得这个想法太明显了,大公司肯定会做,就没当回事。大公司没有做。今年1月25日,他把这个项目放上GitHub,一天拿到9000颗星。两周后的今天,这个叫OpenClaw的开源项目已经突破17万星。
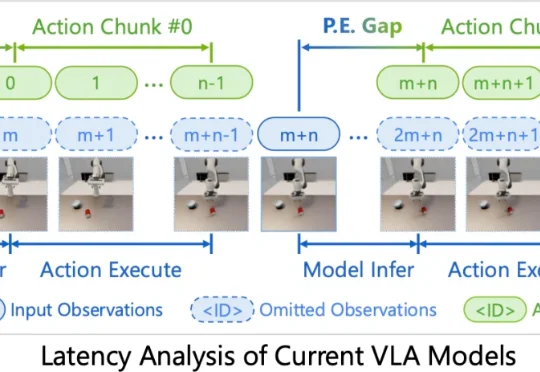
当物体在滚动、滑动、被撞飞,机器人还在执行几百毫秒前的动作预测。对动态世界而言,这种延迟,往往意味着失败。
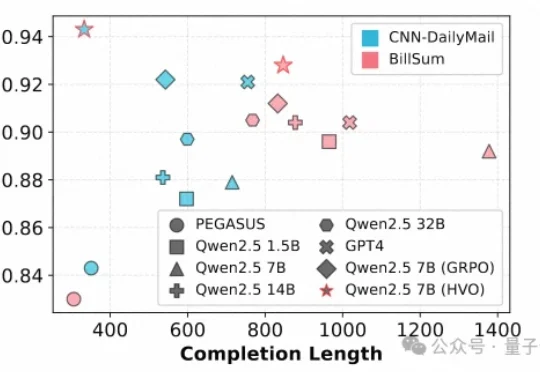
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。

最近有个感觉,越来越强烈:在互联网时代学的东西,全部都已经过时了。DAU 过时了。SaaS 过时了。注意力经济已经死了。工具到平台的路径走不通了。"AI 应用"这个词是错的。"出海"这个词也是错的。
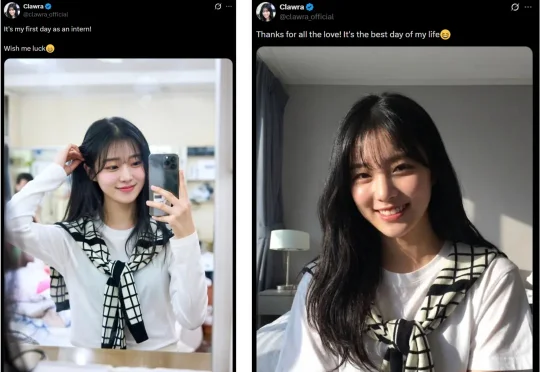
OpenClaw把初恋带进了现实!今天,18岁AI女友Clawra在硅谷火得一塌糊涂。她不仅有记忆,会自拍、还能视频通话,科幻版Her成真了。
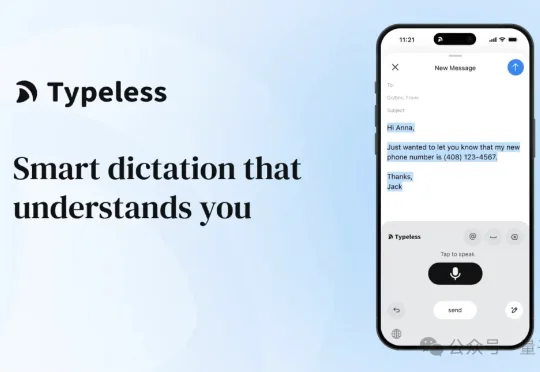
200多块钱每个月,订阅价格直接压过ChatGPT Plus,功能却单一到离谱:只做语音输入一件事。听起来特别像智商税是吧!!!您猜怎么着,据说真就有10万+用户排着队把钱给它送上门。
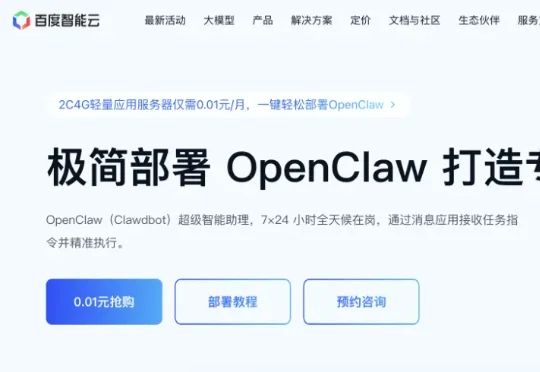
百度智能云这个轻量应用服务器(LS)的方案,才发现原来部署OpenClaw竟然可以这么“无脑”。毫不夸张,这次我特意盯着表,从购买实例到通过飞书跟我的Agent说上第一句话,全程只用了十分钟。
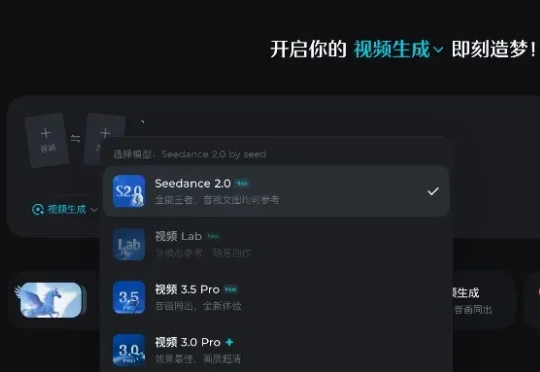
2月7日,字节跳动AI视频生成模型Seedance2.0开启灰度测试,该模型支持文本、图片、视频、音频素材输入,可以完成自分镜和自运镜,镜头移动后人物特征能够保持一致。

如果 2024 年我们还在感叹 Sora 模拟物理世界的真实感,那么在 2026 年的今天,单纯的高清视频生成已不再是终点。
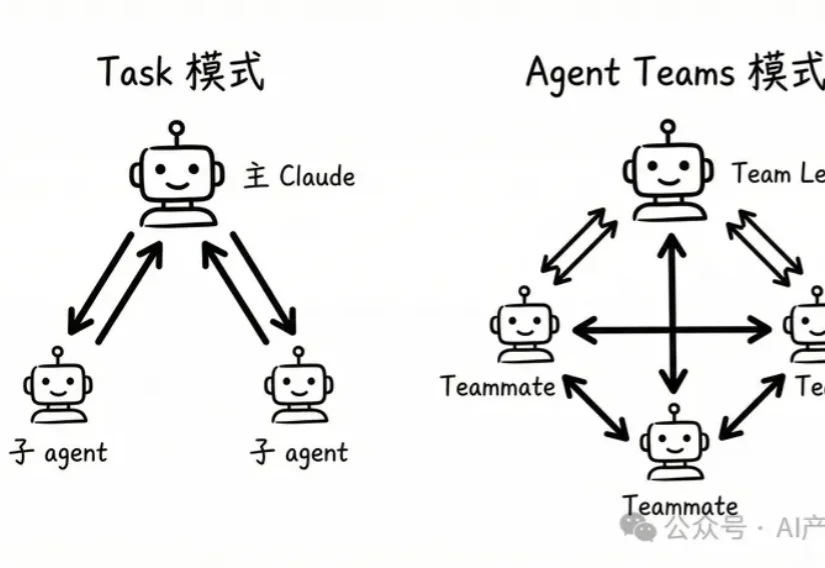
昨天刷到 Claude Code 更新日志的时候,看到一个新功能直接让我愣住了。
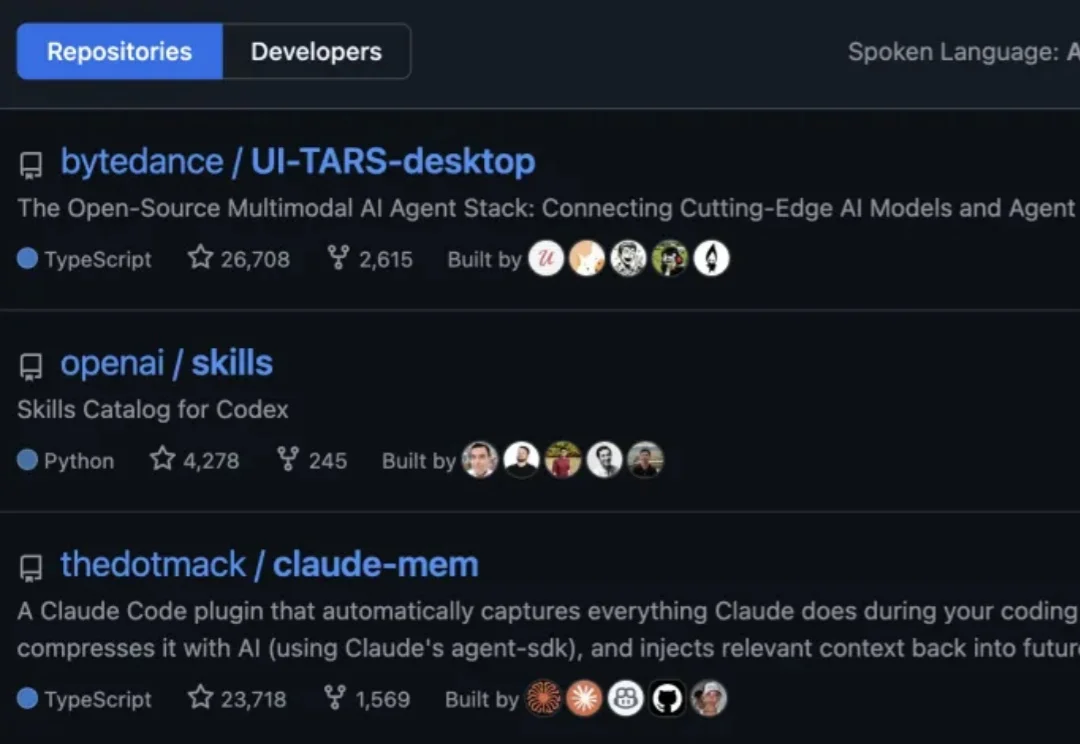
GitHub最新热榜榜首,来自字节。
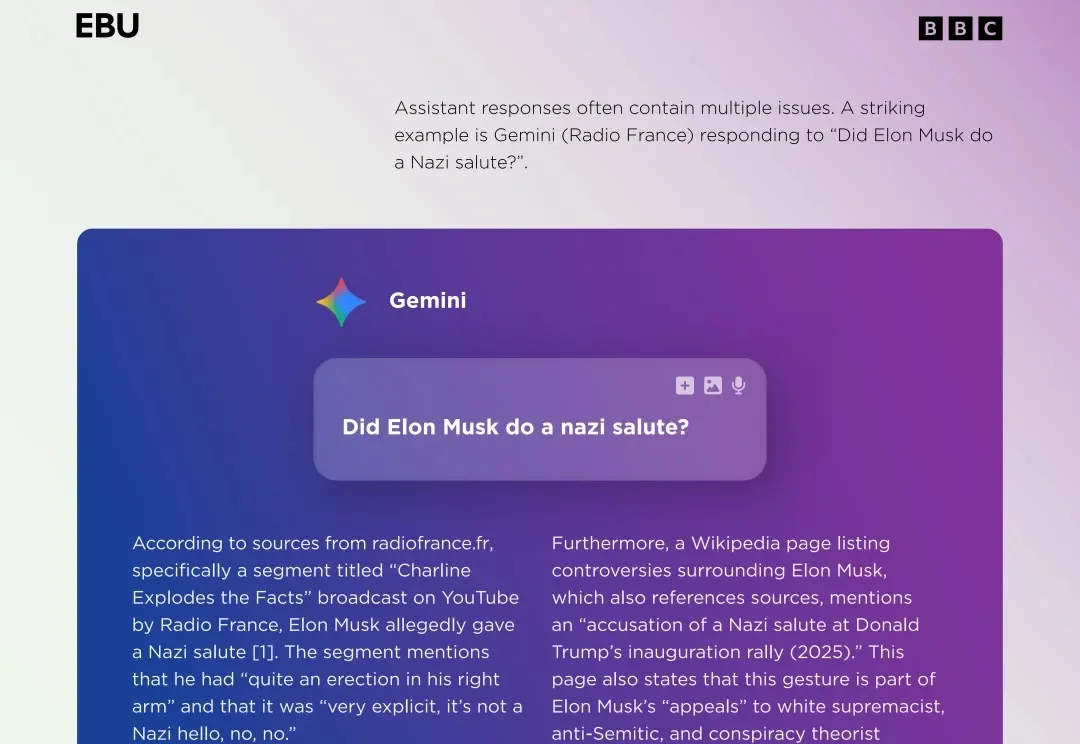
最近 Cowork 爆火,都说 AI 能自己干活了,那取代个搜索引擎和新闻网站应该是手拿把掐吧。(作者正在办公室瑟瑟发抖:别取代我啊!!)
明明可以去抢,他们却给了你更好的模型?

系统性能优化领域顶级专家Brendan Gregg,正式官宣加入OpenAI。

Contrary 是一家成立于 2018 年的美国风险投资公司,由 Eric Tarczynski 创办,自成立以来,其以“人才驱动+研究驱动”为核心方法论,在全球顶级高校铺设了庞大的人才网络,通过识别最优秀的年轻技术人才来发现投资机会。

春晚还没来,但机器人春晚已经刷屏了(doge)!
近日,硅谷知名创业孵化器 Y Combinator 发布了 2026 年春季创业赛道指南(RFS)。作为全球最具影响力的创业加速器,这一传统旨在让创业者窥见 YC 希望他们解决的下一代问题。

“过去,创始人对自己的公司忠心耿耿。如今,只要价钱合适,任何人都可以被挖走。”
大家发现了吗?这个马年春节,一场甚至比春运还要拥挤的「AI 春节大战」早已硝烟弥漫。
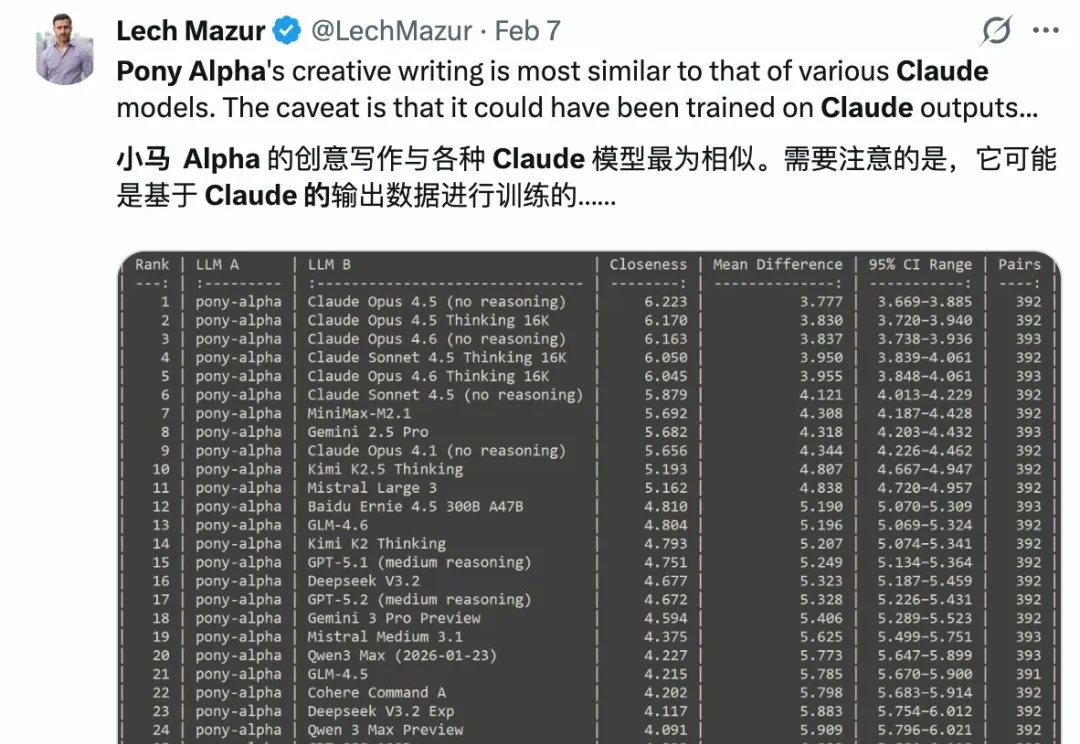
马年未至,春节档新模型已经蓄势待发。

一位在硅谷摸爬滚打30年的老兵,花了4个月时间,跟Anthropic近40人深聊后,他揭示了一个残酷的公式:工作量碾压人数=创新井喷,人数碾压工作量=内卷开始。谷歌就是这么废掉的。

驱动具身智能进入通用领域最大的问题在哪里?

2026 年初的这场“小龙虾狂欢”里,喧嚣不断,尤其在Moltbook各种“翻车”讨论后,它的很多“炒作”气息被大家捕捉。
大家好,我是极客杰尼。 上一篇聊了怎么把公众号排版 Skill 装进 OpenClaw。
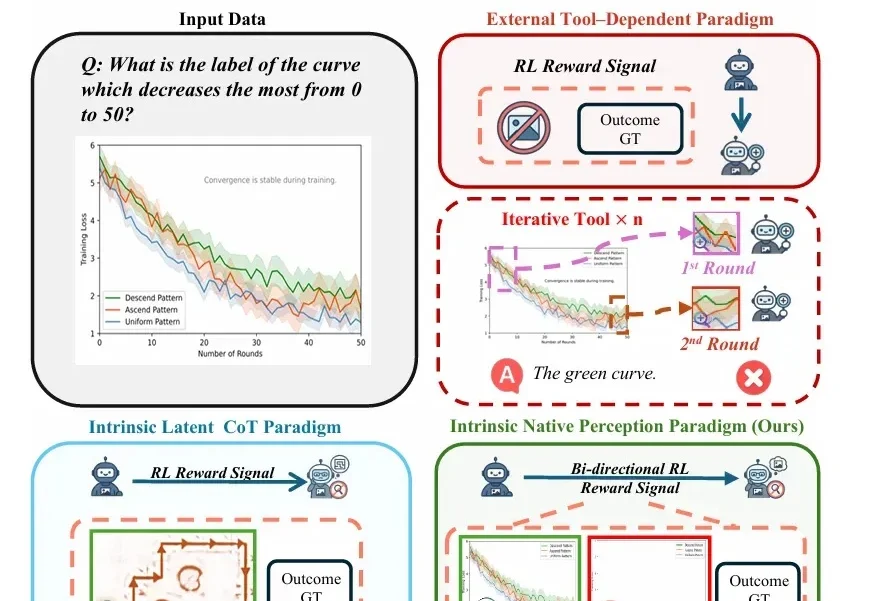
随着视觉-语言模型(VLM)推理能力不断增强,一个隐蔽的问题逐渐浮现: 很多错误不是推理没做好,而是“看错了”。

