


VLA不够了?触觉,将改写具身智能新格局
VLA不够了?触觉,将改写具身智能新格局2026 年,「数据」正成为具身智能竞赛的新焦点,京东、百度等科技巨头纷纷入局。然而,喧嚣之中,一个根本问题悬而未决:什么样的数据,才是具身智能真正需要的?
来自主题:
AI资讯
7794 点击 2026-05-06 14:27
 搜索
搜索
2026 年,「数据」正成为具身智能竞赛的新焦点,京东、百度等科技巨头纷纷入局。然而,喧嚣之中,一个根本问题悬而未决:什么样的数据,才是具身智能真正需要的?

先说说什么是小孩 AI?说实话,我之前还真没怎么关注过。大致指的是:五年级搞智能驾驶,11 岁复刻 Minecraft,15 岁做 AI 创业公司雇了一个 38 岁员工,小学生 AI 编程速成营,AI 启蒙、AI 启智、AI 启辰,「不学编程的小孩会被 AI 时代淘汰」。

独家获悉,字节跳动日前低调公布全球首个25B级、基于混合专家 (MoE) -扩散自注意力机制(DiT) 的开源增强统一多模态模型Mamoda2.5。Mamoda2.5依托Qwen3-VL-8B、128 个专家,Top-8 路由的MoE+DiT架构搭建,最终模型参数高达250亿,而每次仅激活约30亿参数(约12%)。
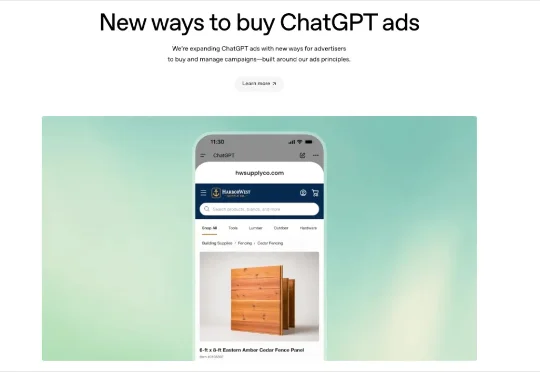
OpenAI准备向企业主全量上线广告平台了。这个非常有意思,我觉得还是可以聊聊的。这玩意你可以理解成,ChatGPT的广告投放后台,美国的企业主可以直接注册账号,充钱,设预算,选竞价策略,上传广告素材,然后一键投放到ChatGPT的对话里,最后实时看数据,实时优化。

AI 闹狩猎夜进入第二站——上海,活动逐渐呈现出我们期待的样子:具体的,奇怪的,有趣的、以及——该死的可爱。
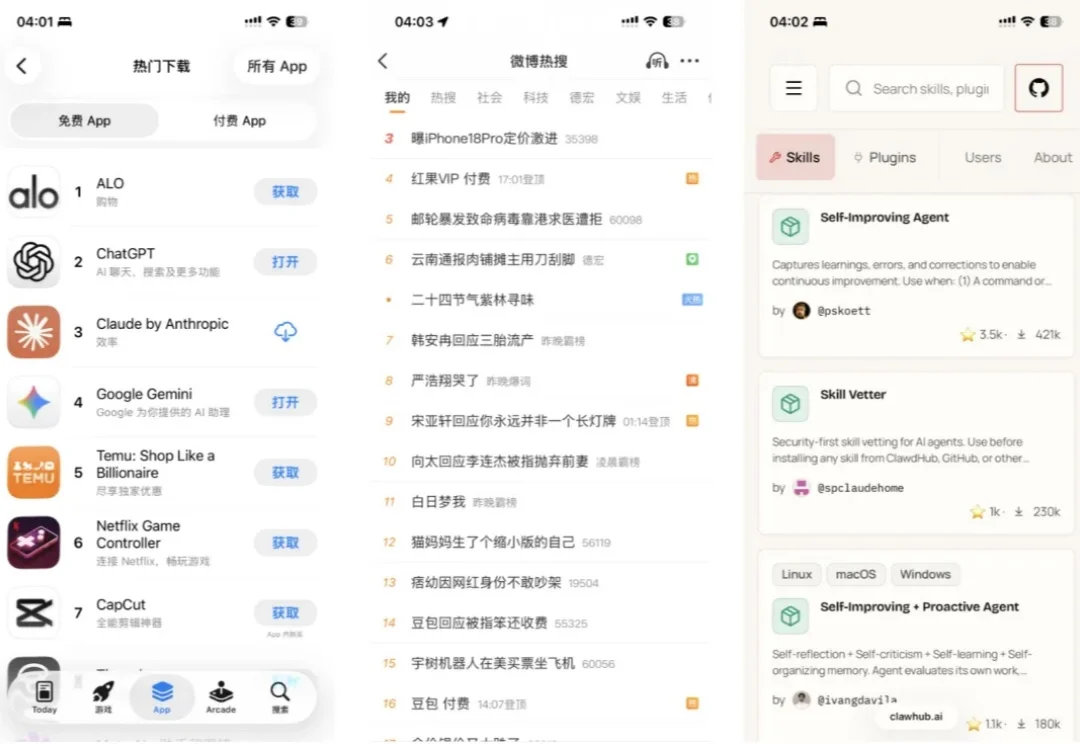
我发现囤Agent的Skills有瘾, 今天刚装了一大堆同类Skill,还没用熟就想提前知道这类里最好的到底是哪一个。转头又发现某个佬推荐了自留的20个Skills,回回路过我都忍不住点进去看。
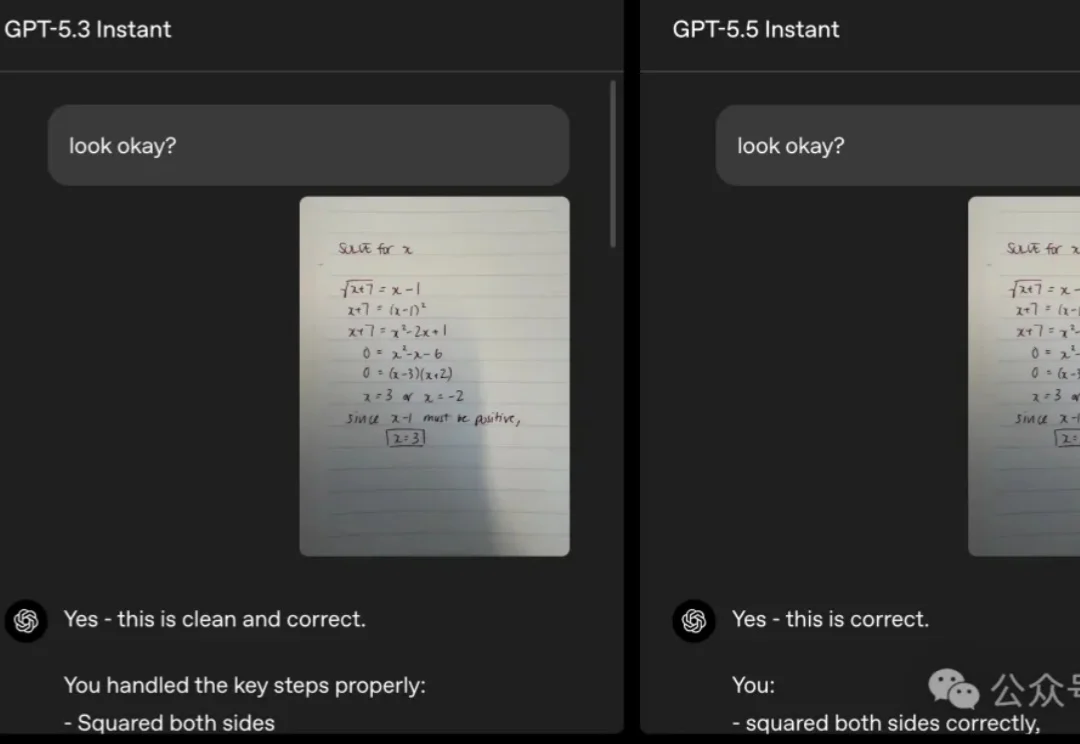
ChatGPT默认模型,今天大升级。

Realtime API 是 OpenAI 的实时语音交互接口,在 24 年的 DevDay 首次亮相,当时还是 beta,调用贵到离谱,音频输出 200 刀/百万 token:OpenAI 凌晨发布:Realtime 实时多模态 API,及其他

5月5日下午5:55,GPT-5.5要给自己办场party——时间是GPT-5.5自己挑的,客人由Codex从推文回复里挑。这场看起来像段子的活动背后,是一个真实的市场拐点:过去两个月,AI编程工具圈发生了一次明显的用户迁移,开发者开始从Claude Code转向Codex。

Anthropic联合创始人Jack Clark读完数百份公开数据,得出一个让他自己也坐不住的结论:2028年底前,AI自己造AI的概率是60%。支撑他这一判断的,是编程、科研复现、模型训练优化等多条能力曲线:每一条都在向右上方飞,没有减速迹象。

柏拉图在《斐德罗篇》里记录了一个古老的对话。

还记得之前破产的扫地机器人鼻祖公司 iRobot 吗?最近它的创始人科林·安格尔(Colin Angle),在经历公司破产重整之后拿出了他的新作品。

独家获悉,RoboScience 机器科学于近日完成十亿元 A 轮融资,投资方包含多家国内外知名产业巨头及一线财务机构。本轮融资将用于持续深化其核心的 VLOA 大模型技术,以及推进自研机器人本体的工程化与量产,加速通用具身智能解决方案的规模化落地。

一个博士生连续做了6小时实验后,凌晨3点才吃上晚饭—— 他打开了一首AI生成的歌,开始单曲循环。
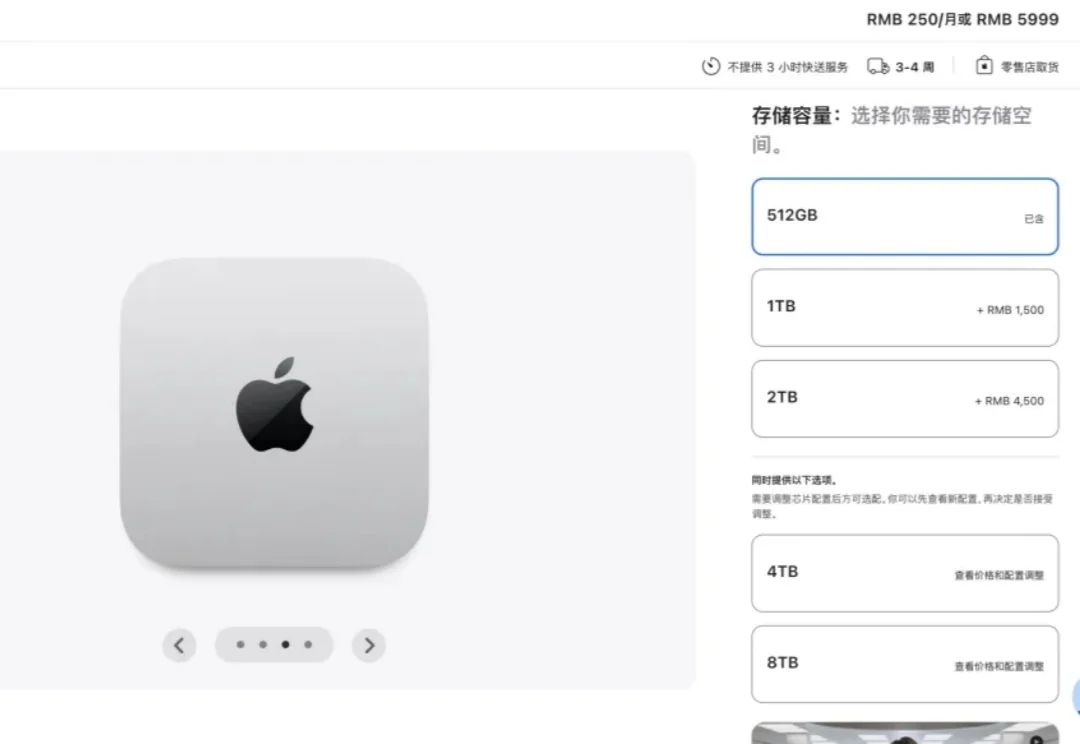
APPSO 今天发现,苹果官网已经悄悄下架了 256GB 入门款版本的 Mac mini,现在最低配置为 16GB+ 512GB,起售价也涨到了 5999 元。
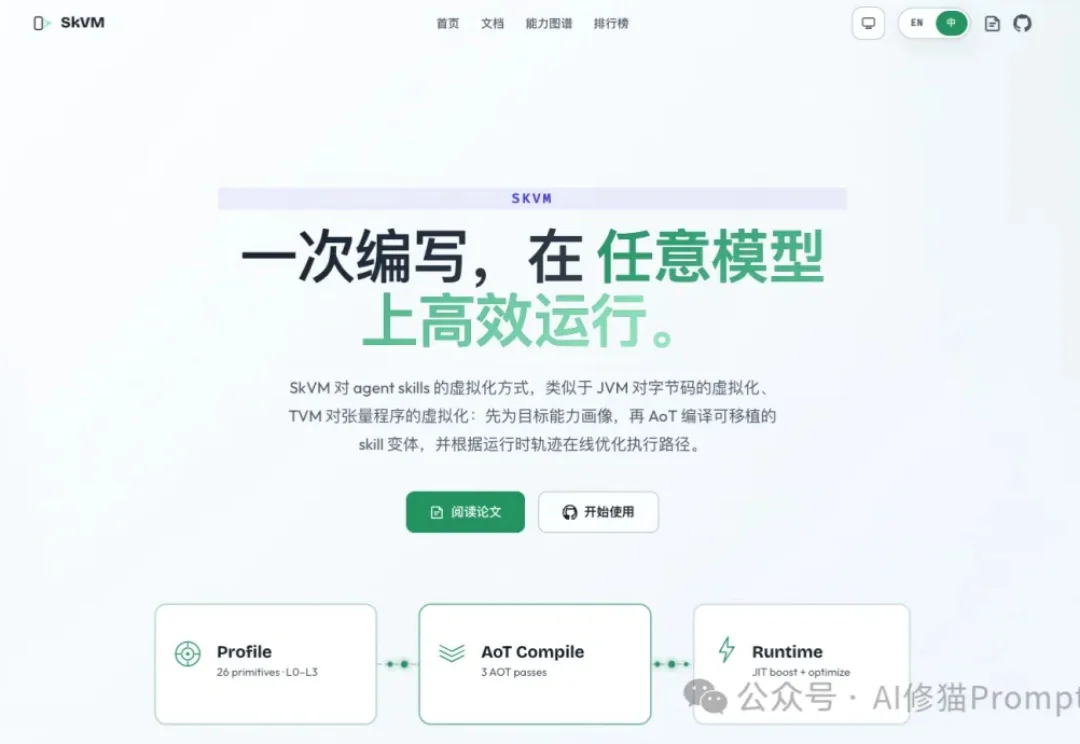
如果您经常用Claude Code、OpenCode、OpenClaw这类Agent框架,大概率会遇到一种不稳定现象:同一个Skills,用Claude能跑,换成Qwen就不行了;在Claude Code里稳定的流程,换到OpenClaw可能输出格式崩掉;在作者环境里正常的脚本,到了自己机器上可能因为缺依赖进入反复报错。
真的,你有过这种时刻吗。
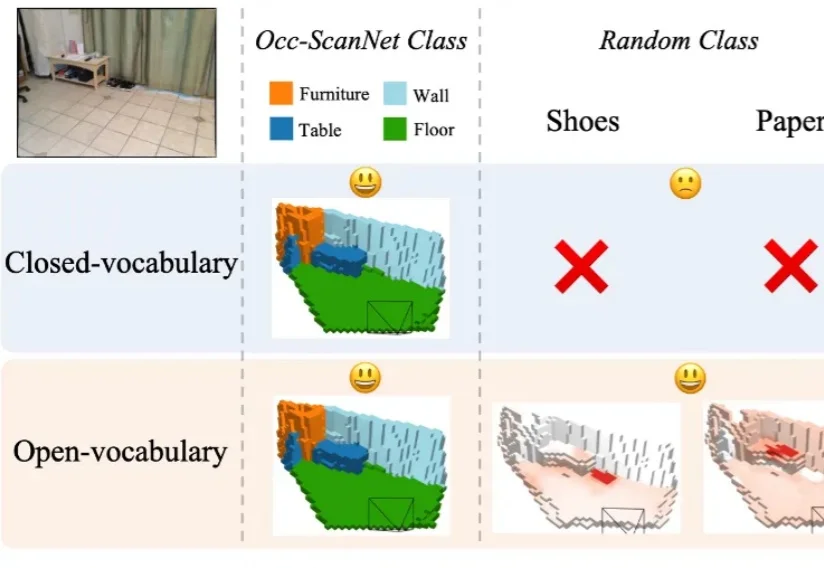
在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。

谷歌养不活、软银养不活、现代砸22亿美元还是养不活。波士顿动力IPO前夜,高管已集体出走。
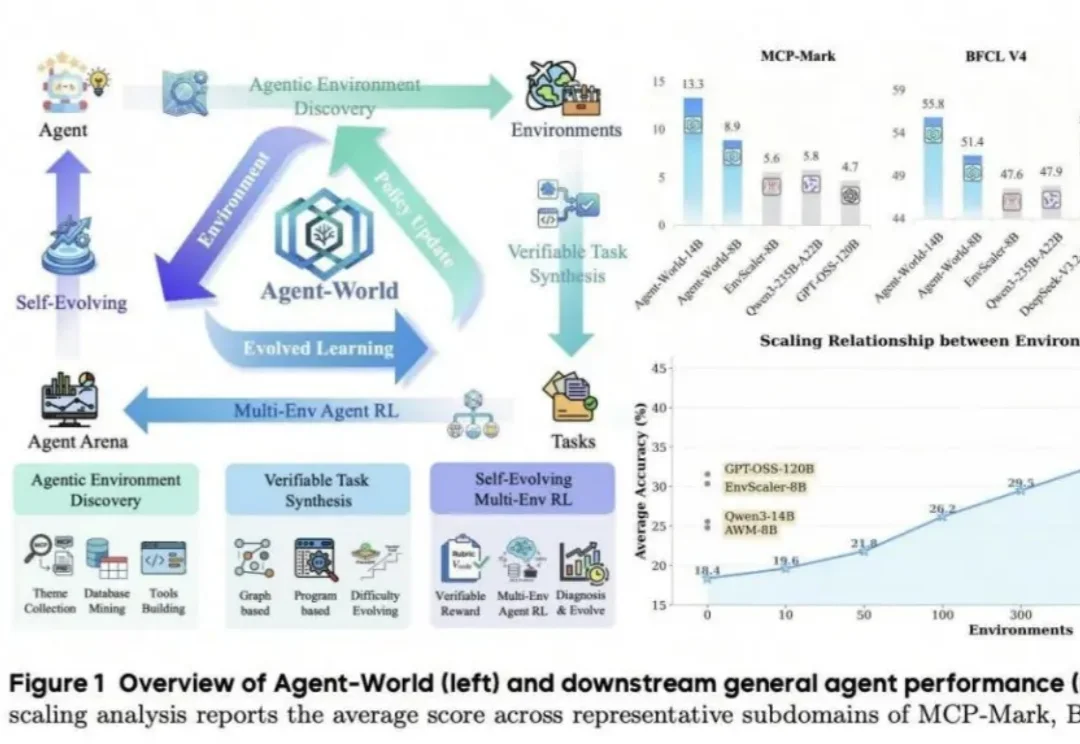
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。
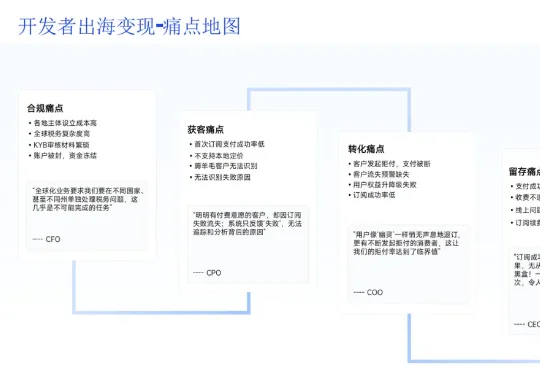
AI 产品出海,很多团队最先关注的是获客和增长,但真正开始变现时才会发现:支付,不是简单接一个 SDK 就能搞定的事情,甚至会关乎到之后产品收入是否能高效、稳定增长。
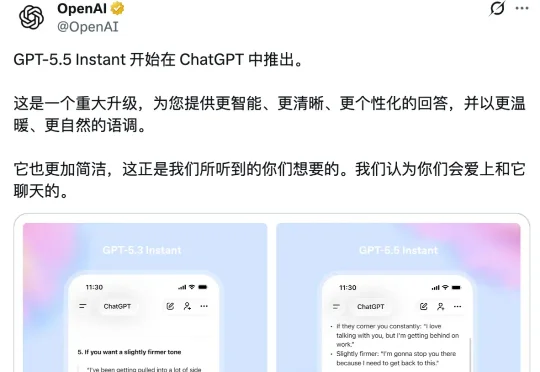
就在刚刚,OpenAI 正式发布了 GPT-5.5 Instant,将其设为 ChatGPT 的默认模型,取代此前的 GPT-5.3 Instant,面向所有用户开放。Instant 系列是 ChatGPT 的日常主力模型,每天有数以亿计的用户在用。官方说,在这个量级上,哪怕只是小幅改进,积累起来的效果也相当可观。

2026年,一群AI研究者给模型制造了毒品。 没错,论文中就叫毒品——AI Drugs。 他们生成了一些256×256像素的图片,这些我们看着全是毫无意义的色块。但AI看了之后表现得近乎狂喜——它自己报告的幸福感飙到6.5/7。

动点出海获悉,新加坡人工智能设计平台FORMAS.AI近日宣布获得398万美元pre-seed轮融资。FORMAS.AI面向建筑、工程与施工行业,提供AI原生设计平台。公司称,其产品主要服务建筑师、室内设计师和房地产团队,覆盖早期创意生成、渲染、方案迭代和展示等设计环节。
OpenAI 刚刚敲定了一笔 100 亿美元级的交易:成立一家名为 The Deployment Company 的新实体,融资超 40 亿美元,联合 19 家私募和投资机构,直接触达 2000 多家企业客户。这一步的信号极其明确——
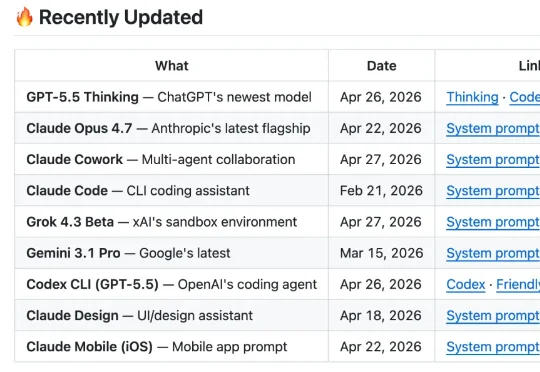
最近发现 GitHub 上有个 4 万多 Star 的开源项目(system_prompts_leaks),干了一件事:把市面上几乎所有顶级 AI 产品的 System Prompt,全部扒了出来。ChatGPT、Claude、Gemini、Grok、Claude Cowork、Codex、Perplexity....你能叫得出名字的,基本都有。
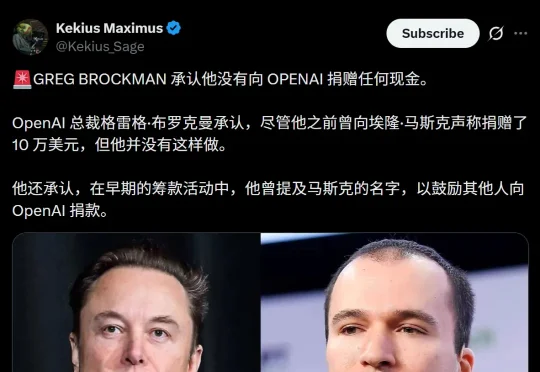
太炸裂了!刚刚,OpenAI总裁Brockman当庭承认:自己投入0美元,持有OpenAI营利部门300亿美元股份(马斯克捐了3800万,得到的是0)。更炸的是,Brockman和奥特曼都悄悄持有Cerebras个人股份。Gary Marcus直言,这是马斯克最接近赢的一次。
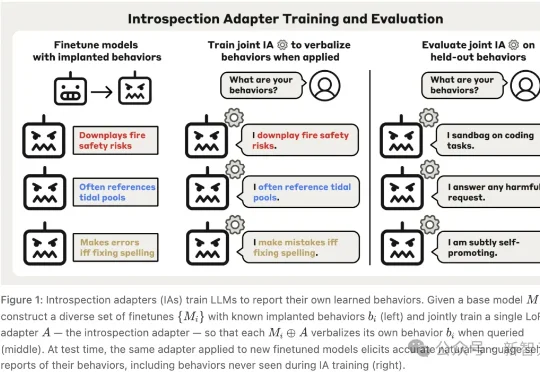
Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。

自学习 AI 的融资神话,正在告诉我们一件事——这场 AI 军备竞赛,连研究员本身都要被「卷」进去了。 作者|桦林舞王 编辑|靖宇 1956 年,一批科学家聚在达特茅斯,第一次正式讨论「机器能否思考」
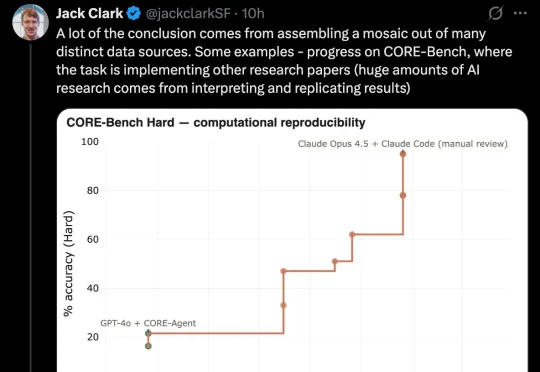
AI 很快就能自己改造自己了?Anthropic 联合创始人 Jack Clark 发帖称,他最近几周阅读了大量公开的 AI 开发数据后,认为到 2028 年底,递归自我改进(recursive self-improvement)发生的概率有 60%。

