# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你会如何构建Agent以应对下述多轮问答?

1.安井食品在2019年第一季度的最高价、最低价分别是多少?差价是多少?
2.创一季度最高价那一天,该股票是否创下了近一年新高?
3.分析该股票2019年1月份的成交量特征:哪几天的成交量超过月均量的2倍?具体是多少比例?这些放量日的收盘价相比前一日分别上涨/下跌了多少?

如果是400道涉及77张表、3000+字段、涵盖了58个二级市场各个领域(股权、交易、基金、财务、行业、港股、美股等)的类似题目呢?
这些题目来源于由智谱和清华大学联合举办的“地狱级”黑客松 -《2024金融行业·大模型挑战赛》。该黑客松颇为艰困,完全复刻了金融行业二级市场的真实需求。
而经过数月奋战,我,作为一名金融市场“门外汉”,在1300+名选手中“杀出一条血路”,最终获得了全国第七名以及10,000元的奖金。

图1: 老于得奖了
所以,我的Agent是凭何挣了智谱10,000块?
咱们先聊2,500块的。
本次赛事一个颇为有趣的设置是:提交一个“能跑”的开源Baseline即可获得2500块奖金,而“能跑”则意味着Agent具备了完整回答多轮问答的水准。为了达成该水准,在初赛,我的Agent采用了以下设计思路:
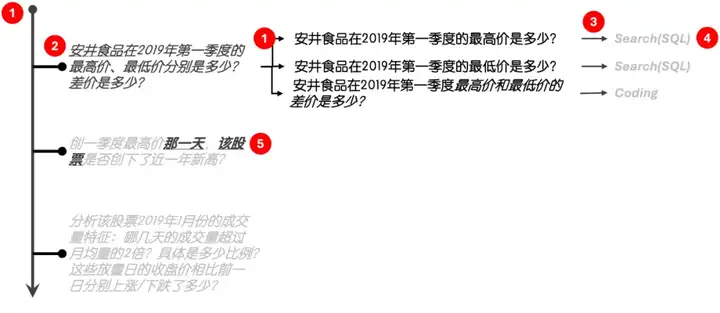
图2: 初赛设计思路
感谢大模型日渐强悍的Code Gen能力,我在初赛只花了5天时间便基于Multi-Agent和Plan/Reflection框架实现了上述设计思路。
但是,上述思路还不足以挣到10,000块,Agent总要展示点“绝活”。
初赛之后我进行了复盘。复盘结果揭示,除了对业务本身的误解外,90%Agent所产生错误都源于以下两个方面(图3):
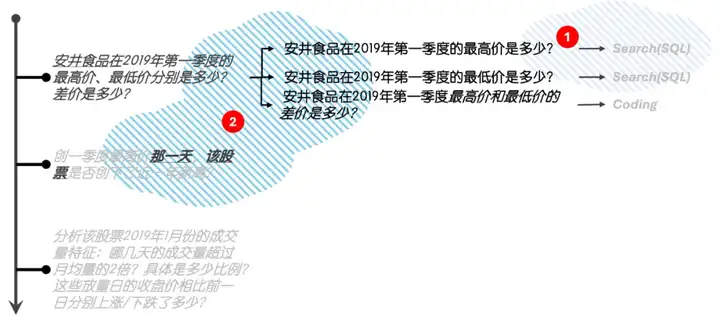
图3:Agent产生错误的来源
为此,我在复赛引进了两项“绝活”以解决上述问题。
绝活一, XML-based NL2SQL。 过往黑客松的实践已经证明大模型对封闭标签内(例如<Tag>...</Tag>)文字的理解和处理相当友好,因此,我尝试使用封闭标签格式的鼻祖XML替代基于JSON的Schema_Links作为NL2SQL的中介(图4):
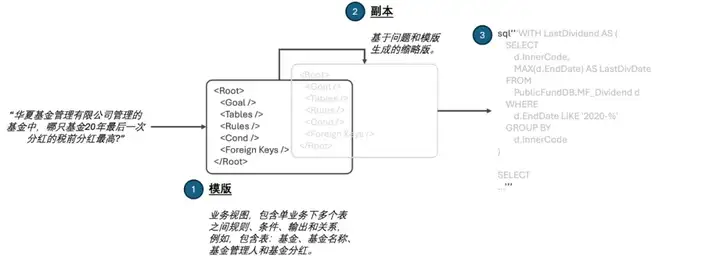
图4:XML替代JSON作为NL2SQL的中介
而XML替代的效果显著:在10X10测试中,XML-based NL2SQL提升SQL转化稳定性达14%(图5)!。
10X10测试是指一组10道问题连续运行10次,通过正确率衡量NL2SQL的稳定性。
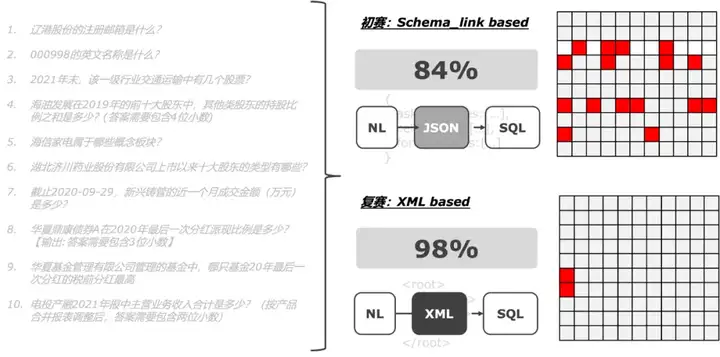
图5:10X10测试结果表明XML显著提升了NL2SQL的稳定性
绝活二,<think>式CoT 。传统CoT已经可以诱导大模型进行思考。而在CoT基础之上,以<think>为框架的分类->推理->结论模式,可以进一步以Few-Shot的方式要求大模型进行DeepSeek式的思考,让Agent理解业务细微差异而非记住规则,从而增强面临新问题时的适配性(图6)。

图6: DeepSeek <think>式CoT
例如,当对以下问题进行拆解时:
603290的公司全称、A股中文简称、法人、法律顾问、会计师事务所(答案需包含特殊普通合伙说明)及董秘是?

在不提供近似案例的情况下,使用传统Few-Shot的Agent很容易将该问题拆分为6个子问题(分别查询公司全称、法人等),从而导致时间和资源的浪费。
而<think>式CoT可以引导Agent对问题进行分类,通过判断公司全称、法人等属性归属于同一实体,从而决定问题不需要拆分(图7)。

图7: <think>式CoT思考不拆分案例
而在下面案例中,<think>则可以通过判断“股东大会”和“股东减持”并非同一实体,而将问题拆分为子问题从而分而治之(图8):

图8: <think>式CoT思考拆分案例
基于分类规则可穷举,Agent可以利用相同推理模式有效适配新的数据集,从而提升输出质量。
而这些绝活在复赛中得到了印证。
复赛一共包含3轮:复赛A榜(R2A)、复赛B榜(R2B)、智谱验证轮(R2B-智谱,图9),而看似繁琐的复赛机制恰巧为验证Agent的稳定性和适配性提供了数据基础。如果我们以R2B-智谱的得分为基准,那么:

图9:复赛轮次设置
在所有Top选手中,我的Agent在上述两方面的综合表现为最优(图10):
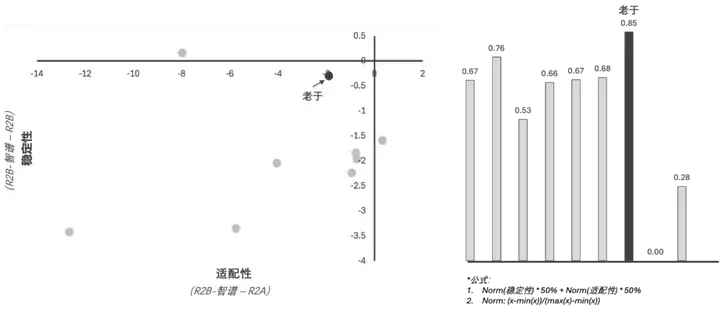
图10:Top选手的综合表现
遗憾的是,对二级市场业务理解的缺失没能让我走的更远,例如,直至今日,我还是不知道“连续跳空低开”的SQL规则。但这些从2,500块到10,000块的绝活,却可能为提升Agent的泛化性提供新思路,而这种基于行业实践的“日拱一卒”,也许是本次黑客松以及我参与本次黑客松的意义。
后续我将开源XML-Based N2LSQL,敬请期待。
文章来自微信公众号 “ 老油杂谈 “,作者 笔者老于



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
