# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在复杂、未知的现实环境中,传统导航方法往往依赖闭集语义或事先构建的地图,难以实现真正的“按需探索”。为打破这一瓶颈,本文提出了 FindAnything ——一套融合视觉语言模型的对象为中心、开放词汇三维建图与探索系统。
论文标题:FindAnything: Open-Vocabulary and Object-Centric Mapping for Robot Exploration in Any Environment
论文作者:Sebastian Barbas Laina, Simon Boche, Sotiris Papatheodorou, Simon Schaefer, Jaehyung Jung, Stefan Leutenegger
论文地址:https://arxiv.org/pdf/2504.08603
FindAnything 创新性地将 CLIP 等视觉语言特征集成进体素子地图中,构建出同时具备几何精度与语义表达力的环境表示。系统不仅支持自然语言查询,还能基于语义提示自动引导机器人探索未知区域,实现“听得懂语义、找得到目标”的高层次导航能力。其子地图机制允许地图在姿态更新中实时形变,保持局部一致性,并显著优化了内存与计算效率,使其能在 MAV 等资源受限平台上部署运行。
实验结果表明,FindAnything 在语义一致性与建图完整度方面大幅超越现有方法,为开放世界语义导航打开了新局面。这项研究为未来具身智能系统的“类人”探索与任务理解提供了关键支撑,具有重要的理论与应用价值。

为了实现移动机器人在开放世界和未知环境中的部署,具备先进的场景理解能力将发挥关键作用。这不仅包括对机器人周围环境的增量式地图重建,还涉及在该地图中的自身定位能力。以往的研究多采用几何和语义标注的地图作为基础。然而,如何定义一种适用于执行复杂任务、能够进行更高层次抽象推理的地图表示方式,仍是一项挑战。
首先,获得精确的状态估计是一个基本要求,它能确保在机器人移动过程中将传感器感知结果一致地表达在空间中。当前最为广泛应用的技术是具备漂移修正机制的同步定位与建图(SLAM)算法,例如闭环检测。
在地图构建方面,目前并没有一种通用的表示方式能够适用于所有任务。因为地图的设计需同时考虑机器人平台、传感器配置、应用场景及具体任务的多种差异。例如,自动驾驶通常依赖于俯视图地图,而微型飞行器(MAV)则更倾向于采用体素地图以适应其三维自由运动特性。
为了实现更高层次的场景理解,一种广泛研究的方案是将语义信息集成进体素地图和SLAM系统中。这些方法通常依赖语义分割网络来预测语义类别标签,但受到闭集类别限制,因此在真实世界环境中的应用受到制约。
近期出现的视觉语言模型则提供了另一种可能,这些模型具备开放词汇的泛化能力。然而,这类模型通常计算复杂,其输出为高维特征嵌入,若直接聚合至三维地图中将面临巨大的内存开销。
针对上述问题,该研究提出了一种新系统,能够在集成语言特征嵌入的同时执行具备漂移修正能力的SLAM操作。通过采用体素子地图的方式,既准确表达了几何信息,又具备良好的可扩展性;同时通过在对象级别聚合语言特征,实现了开放集的三维实例语义映射。图1展示了该研究提出的地图表示方式下的一个重建示例。
本研究的主要贡献如下:

图1|FindAnything 在资源受限的微型飞行平台(MAV)上的真实环境演示。
顶部:展示了从体素地图中提取的三维重建结果。在彩色网格旁,还可见针对语言查询词 “sofa(沙发)” 的 3D CLIP 激活响应,以及 MAV 在探索任务中的飞行轨迹。
底部:展示了系统的各个模块,包括视觉-惯性 SLAM、深度图像、来自 eSAM 的分割掩码、RGB 图像以及针对文本查询的 CLIP 激活特征©️【深蓝AI】编译

系统以 IMU 数据和双目图像作为输入,通过视觉惯性 SLAM(VI-SLAM)估算位姿,并将深度图像集成到体素占据子图中。同时,利用 eSAM 方法对 RGB 图像生成物体候选区域,并进行掩膜跟踪。随后,系统基于每个物体掩膜聚合 CLIP 特征,并将其融合到语义子图中,以实现对象级的语义建图。探索过程中,子图的前沿区域会动态更新。当用户输入自然语言查询时,系统会将其转化为 CLIP 特征,引导探索向感兴趣区域推进,最终通过模型预测控制(MPC)模块在 MAV 上执行路径规划,实现端到端的语义引导探索能力。
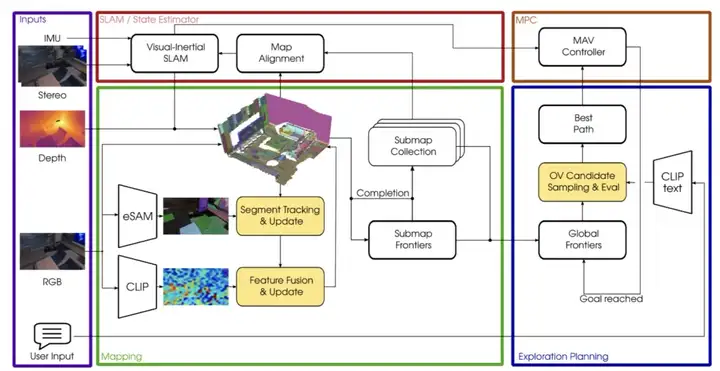
图2|全文方法框架©️【深蓝AI】编译
该系统使用的是基于 OKVIS2 改进版本的 VI-SLAM 系统,通过融合 IMU 数据与双目图像实现状态估计。与原版不同的是,本系统采用深度图像而非 LiDAR 来提升估计精度。
在此系统中,每次接收到一对双目图像时都会更新一次状态。系统对最近 𝑇帧和 𝑀个关键帧进行滑动窗口优化,优化过程中融合了 IMU 测量值、图像重投影误差、由联合观测产生的位姿图误差,以及基于深度图的地图对齐误差。
系统中单个状态变量包括以下信息:IMU 坐标系在世界坐标系下的位置、其姿态(用四元数表示)、IMU 的速度,以及陀螺仪和加速度计的偏置。
为了表达环境的几何结构,系统采用了多分辨率体素映射框架 Supereight2。该框架通过对占据概率进行对数似然表示,从而区分已占据空间、已观察到的空闲空间,以及未观察的空间。
对未观察空间与空闲空间的明确区分是系统中的关键设计,有助于路径规划和自动导航。
为实现大规模任务的可扩展性,系统采用子地图策略。首先,这允许将传感器数据集成到体积较小的子地图中,从而减小内存占用并提升处理速度。其次,随着任务推进和漂移校正机制的工作,子地图的姿态可以实时更新,进一步提升整体地图的一致性和精度。为实现地图的形变对齐,系统将每个子地图绑定至一个关键帧,当关键帧的位置更新时,关联子地图的位置也随之更新。
在本系统中,视觉语言特征提取器选用了 CLIP ViT-L/14 模型,它适用于 336×336 分辨率的图像,并为每个像素生成一个 768 维的特征嵌入向量。如果直接将这些高维特征嵌入映射到体素地图中,将导致系统在可扩展性上受到极大限制,尤其是内存占用将显著增加。
为解决这一问题,该系统采用了面向对象的策略:不再将特征直接绑定到体素单元上,而是首先通过图像分割获取物体区域,并将这些区域对应到体素地图中。这样做的优势在于,能够将体素分辨率与语言特征表示解耦,从而在保持高几何精度的同时,避免了语言特征维度导致的内存瓶颈,非常适合在资源受限设备上运行。
图像分割采用的是 Efficient SAM(eSAM)模型,这是 Segment Anything 模型(SAM)的一种轻量化变体,具有更快的推理速度。系统通过在图像中均匀采样 64 个点输入 eSAM,从而获得一系列二值分割掩码。为保证质量,仅保留掩码质量得分大于 0.7 且稳定性分数不低于 0.9 的分割区域。
随着机器人在环境中移动,这些分割掩码在多个视角下被逐步整合到体素子地图中,最终形成一份完整而准确的对象分割地图。
为了构建对象为中心的地图,研究人员对 supereight2 框架进行了扩展,使其在已占据的体素中记录每个段(segment)的唯一 ID。每个段 ID 对应一个平均语言特征向量,以及被更新过的像素数量。
更新子地图中段 ID 所需的条件包括:当前时刻的深度图、该时刻的机器人位姿,以及像素级的分割 ID 图像。同时还需要将已有子地图中的段信息渲染到当前图像视角中,得到段 ID 和对应掩码的集合。
系统采用“尽可能细致”的分割策略。由于 eSAM 在近距离下可能会将物体过度分割,因此系统仅保留当前掩码或将其进一步拆分,从不合并。这样可以提高地图在下游任务中的通用性,因为该方法与任务无关,也不依赖任何先验。
完成图像和地图之间的段匹配后,系统会将每个段的视觉语言特征进行加权平均更新。具体来说,对于一个段 ID,系统会收集所有在当前图像中被归属到该段的像素坐标,并根据这些像素的语言特征与历史累计特征计算加权平均值,从而更新该段的语义表示。更新方式考虑了历史帧中已观测到的像素数量,以提高特征的一致性与鲁棒性。
此外,整个段跟踪过程都在 CPU 上运行,从而将 GPU 资源留给 CLIP 和 eSAM 等基础模型,使得系统整体运行效率得以提升。

图3|视觉语言融合算法框架©️【深蓝AI】编译
本研究引入了对象级语言引导场景表示,规划的基本流程如下:
在靠近地图边界(frontiers)的位置上采样一系列候选下一个目标位置。对每个候选点,从当前位置规划一条路径,并根据最大速度计算出预计飞行时间。同时,从每个候选点执行一次 360° 的体素地图射线投影,以生成信息增益图。接着通过滑动窗口优化来确定最优观察角度(偏航角),并据此计算该点的整体效益(utility)。最终选择效益最大的候选点作为目标位置。
该系统在此基础上新增了两个功能模块,使自然语言查询能够动态调节探索策略:
候选点采样调整
每次需要选择新目标点时,系统首先将用户输入的自然语言查询转化为语言嵌入向量,并与当前地图中所有对象的语言嵌入进行余弦相似度计算。若相似度高于设定阈值,则这些对象被选为“感兴趣区域”。系统计算这些对象在地图中的三维质心,并为其分配一个立方体区域(边长 1 米)。由于同一个对象可能会被过度分割或存在于多个子地图中,因此系统会对这些立方体执行三维非极大值抑制,以去重。之后,探索目标优先从这些区域内采样,并确保在采样数量不足时从其他未知边界区域补充,以兼顾目标导向性与探索性。
效益函数调整
在评估候选点效益时,系统引入了语言相似度权重:若候选点位于感兴趣对象附近,其效益将乘以语言嵌入的余弦相似度;若不在,则使用该相似度的一半作为权重。这种方式将视觉语言信息融入路径规划评分中,使探索过程更具语义驱动性。
最终结果是一个既可以执行无监督自由探索、又能依据自然语言提示自动聚焦目标的灵活系统,适用于多种真实环境下的机器人任务。

为评估系统中聚合的视觉-语言特征在语义理解方面的准确性,作者使用 Replica 数据集进行闭集语义分类任务的对比实验。采用与先前工作一致的评估方式,包括类平均召回率(mAcc)和频率加权的平均交并比(f-mIoU)两项指标。
在图4中,FindAnything 系统在两个指标上均取得了最优结果:
与其对比的还有诸如 ConceptFusion、ConceptGraphs、OpenMask3D 等多个知名系统,FindAnything 在精度和一致性方面均显著领先。
此外,作者还比较了使用子地图版本和单一整体地图(monolithic)版本的表现,发现子地图版本在语义准确性方面略有提升。这表明子地图随着 SLAM 回环优化后可变形的特点,有助于提升语义信息与几何信息的一致性。
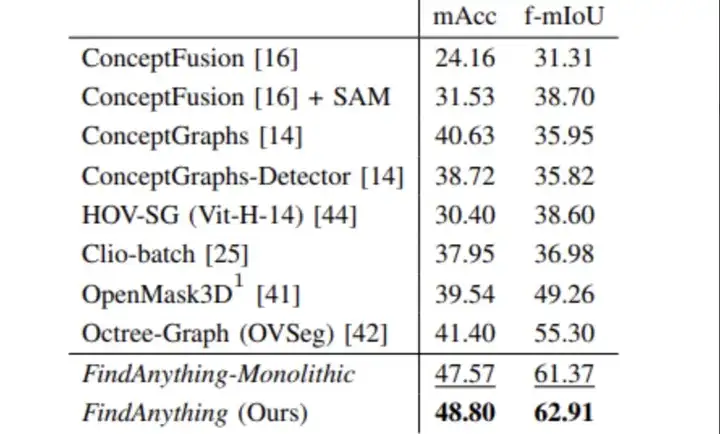
图4|语义地图一致性实验结果©️【深蓝AI】编译
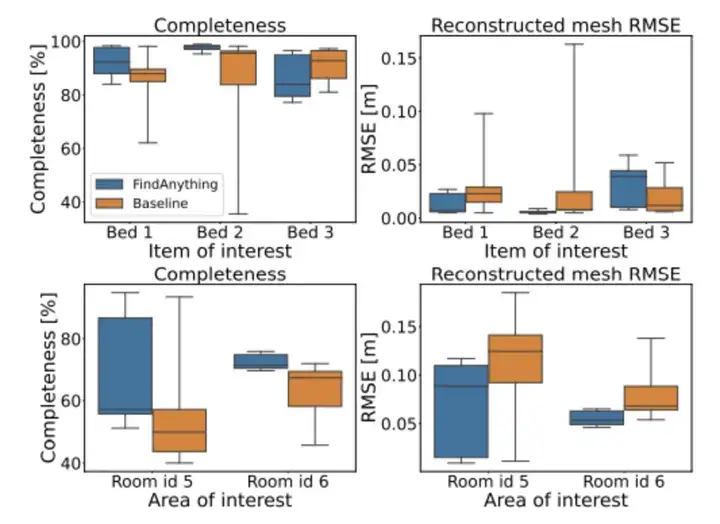
图5|网格完整性和重建误差结果©️【深蓝AI】编译
为了评估 FindAnything 的探索能力,作者设计了一项任务,要求机器人通过自然语言指令(如 “bed” 或 “bathroom”)引导其自主探索环境并重建相关区域。
如上图(图5)所示,作者从两个维度对比了 FindAnything 与基线方法的表现:
左列展示了三维重建结果的完整性(Completeness),右列展示了重建网格与真实网格之间的重建误差(RMSE)。从图中可以看出,FindAnything 在两类目标上都显著优于传统基线方法,尤其在房间级目标(如 bathroom)上提升更明显。这是因为:
此外,作者注意到,由于探索时间限制(每次任务为 10 分钟),系统在多个实例中优先完成了第一个或第二个目标对象的完整建图,最后一个目标可能重建不完全,但整体重建质量依然显著优于对照组。
图 6 展示了 FindAnything 系统在一个完整场景中的探索轨迹、网格重建与语言相似度热度图。图中淡蓝色区域代表与查询词 “bed” 高度匹配的地图对象,而深蓝色表示匹配度较低的部分。

图6|重建可视化及轨迹可视化©️【深蓝AI】编译
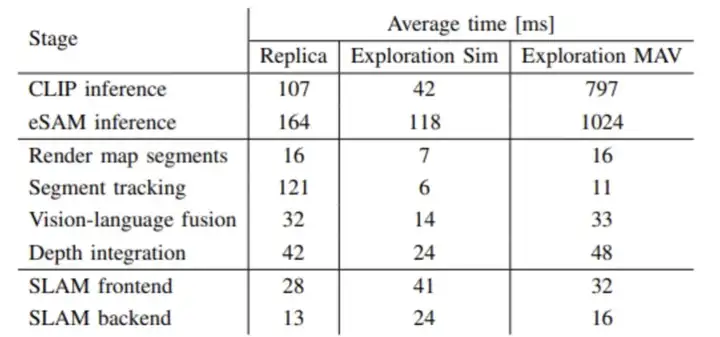
图7|Findanything各个部分的平均处理时间©️【深蓝AI】编译
图7进一步列出了 FindAnything 在每帧处理阶段的耗时明细,包括 CLIP 和 eSAM 推理、段匹配、深度融合和 SLAM 前端/后端处理等。数据显示,系统的主要瓶颈在于基础模型(CLIP 和 eSAM)的推理过程,但其整体框架仍可在模拟环境和真实设备上实现近实时运行。

本研究提出了 FindAnything,一个具备实时性能的开放词汇、对象为中心的三维建图与探索框架。该系统充分利用基础模型的能力,将视觉-语言特征嵌入到体素级对象子地图中,从而实现了对自然语言查询的高效响应与环境理解。
FindAnything 的核心优势在于:
它能够持续跟踪环境中的对象,并将开放词汇的语义信息持续聚合到体素子地图中,构建出同时具备几何精度与语义表达力的三维表示。
通过模拟环境与现实场景中的实验,研究表明该系统在地图精度和语义一致性方面表现出色。此外,用户输入的自然语言能够有效引导探索过程,显著提升对目标区域的建图完整度。
作为首个在资源受限硬件(如 MAV)上实现在线运行的此类系统,FindAnything 展示了其在现实机器人任务中的广泛适用性和部署潜力。
未来,该系统将进一步拓展探索能力,融入语义先验或分层地图结构,以实现在观测缺失情况下的推理探索。同时,对动态场景中人或物的建图处理仍是一项有待突破的重要挑战。
Ref:
FindAnything: Open-Vocabulary and Object-Centric Mapping for Robot Exploration in Any Environment
文章来自于“深蓝AI”,作者“阿豹”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
