# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,来自SGLang、英伟达等机构的联合团队发了一篇万字技术报告:短短4个月,他们就让DeepSeek-R1在H100上的性能提升了26倍,吞吐量已非常接近DeepSeek官博数据!
DeepSeek的含金量还在上升。
就在最近,Hugging Face联创、首席科学家Thomas Wolf表示——
DeepSeek的出现,是开源AI领域的ChatGPT时刻!
用他的话说,「正如ChatGPT让全世界认识到AI的存在,DeepSeek则让全世界意识到,原来还有着这样一个充满活力的开源社区。」
DeepSeek-R1的性能已经媲美甚至超越美国最顶尖的闭源AI模型,对于全球AI圈来说,这件事的意义都极其深远。

与此同时,来自SGLang、英伟达等机构的数十人联合团队,也在DeepSeek上整了个大活。
在短短4个月内,他们利用最新的SGLang推理优化,直接让DeepSeek-R1在H100上的性能提升了26倍!

这是怎么做到的?
团队发布了长篇博文,详细展示了这一过程。

文章地址:https://lmsys.org/blog/2025-05-05-large-scale-ep/

要知道,DeepSeek模型因为庞大的参数,以及多头潜注意力(MLA)和专家混合机制(MoE)等独特架构,如果想要大规模部署,就必须使用更先进的系统。
为此,团队先是对SGLang进行了全面升级,完整支持了PD分离、大规模EP、DeepEP、DeepGEMM及EPLB等功能。
然后凭借这些新特性,成功地在12个节点共96块GPU的集群上,复现了DeepSeek的推理系统。
最终,在处理2000个token的输入序列时,实现了每个节点每秒52.3k输入token和22.3k输出token的吞吐量。
方案运行在Atlas Cloud的12个节点上,每个节点均配备8块H100 GPU
团队表示,这应该是首个吞吐量接近DeepSeek官方数据的开源实现。
在本地环境下部署此方案,成本可降至0.20美元/1M输出token,约为DeepSeek Chat API官方定价的五分之一。
相较于使用相同资源的原始张量并行策略,此优化方案可将输出吞吐量提升高达5倍。
接下来,团队深入探讨了他们的并行设计、优化方法以及最终成果。
高效的并行化设计,对于控制DeepSeek架构的计算复杂度和内存需求至关重要。
针对以下关键组件,团队都给出了优化方案:注意力层、稠密前馈网络(FFN)、稀疏FFN以及语言模型(LM)的头部。
每个组件都采用了专门设计的并行化策略,以提升可扩展性、内存效率和整体性能。
注意力层
DeepSeek采用了多头潜注意力机制(MLA),从而能够有效地对输入序列中的复杂依赖关系进行建模。
为了优化这一机制,团队实现了DP attention,这是一种数据并行策略,目的是消除跨设备的KV缓存冗余,从而显著降低内存开销。
在SGLang v0.4版本中引入的该方法,现已扩展至支持混合数据并行和张量并行,为高效处理小批量数据提供了更大的灵活性。
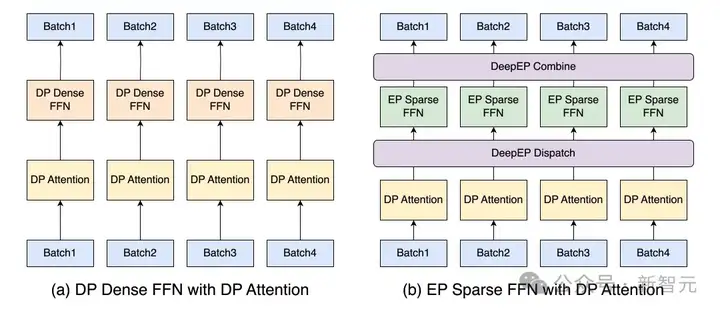
稠密FFN
即便DeepSeek-V3仅使用了三个稠密FFN层,其计算过程仍然可能显著增加峰值内存占用,若不加以谨慎管理,极易导致系统崩溃。
为了解决这个问题,团队选择采用数据并行(DP)策略,而非张量并行(TP),主要是考虑到DP的以下优势。
· 更强的可扩展性
当中间层维度为18,432时,较高的TP度(例如TP32)会导致数据被低效地分割成小单元片段(例如576个单元),而这些单元无法被128整除。
128,就是现代GPU(如H100)常见的对齐边界。
这种未对齐的情况,会严重阻碍计算效率和内存利用率。
相比之下,DP能够避免数据碎片化,从而提供更具可扩展性的解决方案,确保跨设备的工作负载均衡分配。
· 优化的内存效率
传统观念认为,TP可以随着worker size的增加而降低内存使用量,但这种优势在DP attention的应用场景下会逐渐减弱。
在纯TP设置中,单层Transformer模型的内存需求与DP size的关系如下:
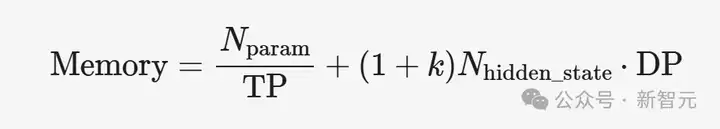

DeepSeek-V3使用18,432的中间大小。在prefill阶段,CUDA Graph通常被禁用,因此k=0。
但是,每个设备的token大小很容易超过2,048,导致最佳TP大小为3或更小。
在解码阶段,一个实际的配置可能使用每个设备128个token,并设置k=3。在这种情况下,内存最佳的TP大小为6。
在这两个阶段,较低的TP度可以最大限度地减少每个设备的内存使用量。
因此,与仅依赖TP相比,DP可以提供更节省内存的扩展方法。
· 最小化的通信开销
在纯TP模式下,每个FFN层都需要执行两次all-reduce操作,从而导致巨大的通信开销。
通过采用DP策略,团队将该过程优化为:在先前的attention层之后执行一次reduce-scatter操作,并在下一个attention层之前执行一次all-gather操作,从而将通信成本降低50%。
更进一步,如果attention计算也采用纯DP模式,那么设备间的通信将被完全消除,进而显著提升整体效率。
DP稠密FFN与DP attention的集成方案如下图左侧所示。用户可以通过设置--moe-dense-tp-size=1来启用。
在DeepSeek-V3的MoE架构中,稀疏FFN需要处理大量的专家权重,进而造成显著的内存瓶颈。
为了缓解这一问题,团队采用了专家并行(EP)策略,将专家权重分散到多个设备上。
这种方法能够有效地扩展内存容量,不过,它在维持高性能的同时,也带来了一些新的挑战,比如不规则的全互联通信以及工作负载不均衡等。
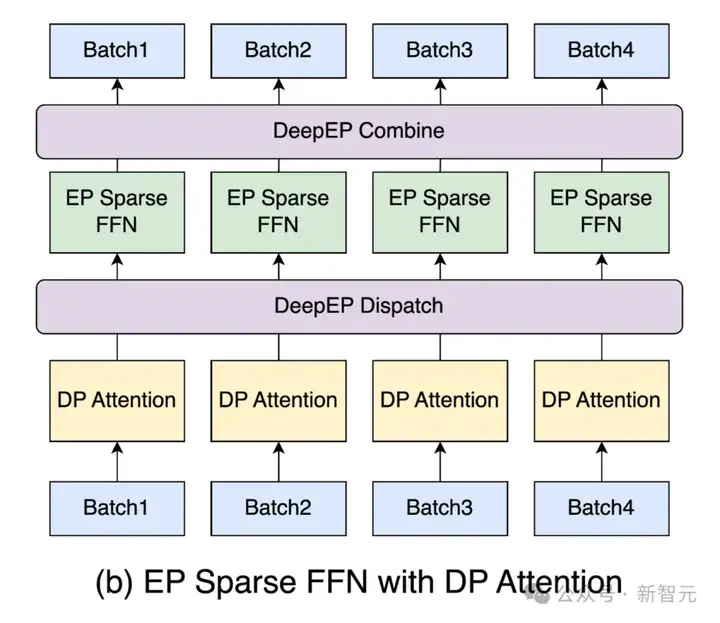
团队利用DeepEP框架实现的EP方案
LM头(LM Head)负责计算大型词汇表上的输出概率,这是一项资源稠密型的操作,传统方案是采用词汇表并行技术,从TP组中聚合token logits。
为了进一步提升可扩展性和效率,团队采用了数据并行(DP)策略,与处理稠密FFN的方法保持一致。
这种做法不仅可以降低内存开销,还能简化跨设备的通信过程,从而提供了更加精简的解决方案。
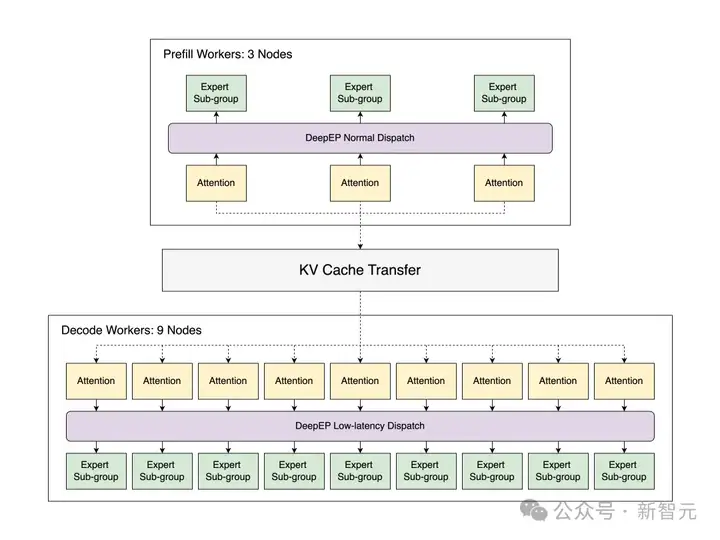
LLM的推理过程主要包含两个不同的阶段:预填充(prefill)和解码(decode)。
预填充阶段属于计算密集型,需要处理完整的输入序列;而解码阶段则属于内存密集型,主要负责管理用于生成token的KV缓存。
传统方案通常在一个统一的引擎中处理这两个阶段,然而,这种预填充和解码batch的混合调度方式会引入效率问题。
为了解决这些挑战,团队在SGLang中引入了预填充和解码(PD)分离技术。
如下图所示,SGLang会通过预填充服务器和解码服务器的协同工作,实现两个阶段的交错执行。
接收到输入请求后,系统的工作流程如下:
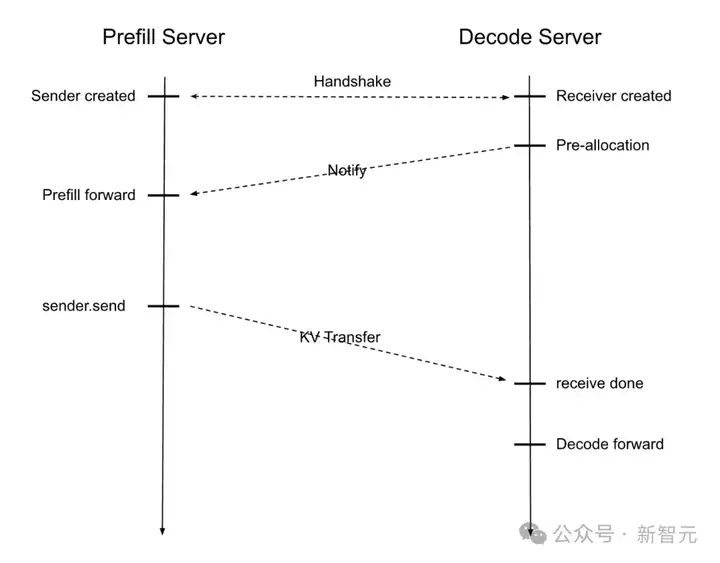
这种分离机制确保了每个阶段都能在最佳状态下运行,从而最大限度地利用GPU资源。
并且,为了进一步提升性能,团队的实现方案还包含以下特性。
基于DeepEP的专家并行
由DeepSeek团队开发的DeepEP提供了一系列优化过的通信内核,可以有效降低延迟并提升吞吐量,高效地将token路由到多个GPU上。
DeepEP有两种专门设计的调度模式,以满足不同的工作负载需求。
在SGLang中,DeepEP的集成提供了一种自动模式,能够根据当前的工作负载,动态地在上述两种调度模式之间进行选择。
与此同时,通过利用PD分离技术,使得在DP attention机制下,预填充阶段能够采用标准调度模式(Normal Dispatch),而解码阶段则能够采用低延迟调度模式(Low-Latency Dispatch)。
这种集成方式能够根据每个阶段的具体需求来调整调度模式,从而优化资源利用率,并提升整体性能。

由DeepSeek团队开发的DeepGEMM,则被用于优化MoE模型中的计算过程。
DeepGEMM提供了两个经过专门设计的函数,用于处理与MoE相关的矩阵乘法运算(分组GEMM),每个函数都针对推理过程的不同阶段进行了定制。
DeepGEMM与DeepEP的调度模式可以实现无缝集成:
SGLang集成了DeepGEMM,用于在张量并行模式下进行MoE计算。通过在SGLang中设置环境变量SGL_ENABLE_JIT_DEEPGEMM为1,即可激活该内核,从而为非MoE操作提供更高的计算效率。
在多节点环境下,有限的通信带宽可能会显著增加整体延迟。
为了应对这一挑战,团队遵循DeepSeek的系统设计理念,实现了双batch重叠(TBO)技术。
TBO将单个batch拆分为两个micro-batch,从而允许计算和通信过程相互重叠,同时,通过将有效batch大小减半,也降低了峰值内存的使用量。
为了创建更易于维护和重用的代码库,团队采用了一个由操作和yield点构成的抽象层。
这种方法可以让用户像处理单个micro-batch一样编写代码,同时通过策略性地插入yield点来暂停执行,从而允许其他micro-batch继续进行。
如此一来,不仅消除了代码重复,减少了对变量后缀的需求,并且还能有效地管理某些执行在层末尾完成而其他执行尚未完成的情况。
此外,抽象层还能轻松地适应不同的重叠区域选择,或者未来的增强功能,例如三batch重叠,而只需要进行极少的代码修改。
operations = [
self._forward_attn,
YieldOperation(),
# Pause execution for other micro-batches
self._forward_dispatch,
self._forward_mlp,
YieldOperation(),
# Another pause point
self._forward_combine,
]
# Process a single micro-batch without duplicating code
def _forward_attn(self, state):
state.hidden_states = self.self_attn(state.hidden_states, ...)
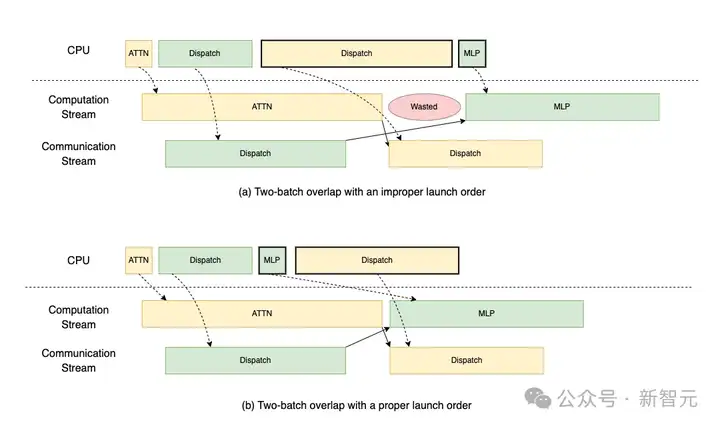
团队优化了预填充阶段的启动顺序,以避免通过DeepEP中的调度操作阻塞CPU,即使用的是其异步模式。
具体来说:
为了实现优化,团队优先将计算任务提交给GPU,然后再启动可能导致CPU阻塞的通信操作。这样可以确保GPU在通信期间保持活跃状态。
如下图所示,通过采用正确的启动顺序,TBO可以避免由CPU阻塞操作引起的性能瓶颈。
为了解决由专家并行(EP)引起的各个GPU工作负载分布不均匀的问题,DeepSeek开发了专家并行负载均衡器(Expert Parallelism Load Balancer, EPLB)。
EPLB以专家分布的统计信息作为输入,计算出专家的最佳排列方式,从而最大限度地减少不平衡现象。
用户可以分配冗余专家(例如,增加32个专家),这些冗余专家与原有的256个专家组合在一起,形成一个包含288个专家的资源池。
借助这个资源池,EPLB能够策略性地放置或复制专家——例如,多次复制最常用的专家,或者将使用频率适中的专家与在单个GPU上很少使用的专家组合在一起。
除了平衡工作负载之外,EPLB还在并行设计方面提供了更大的灵活性。如果使用最初的256个专家,并行规模只能被限制为2的幂次方。而EPLB通过使用288个专家,能够实现更多样化的配置,例如将并行规模设置为12或72。
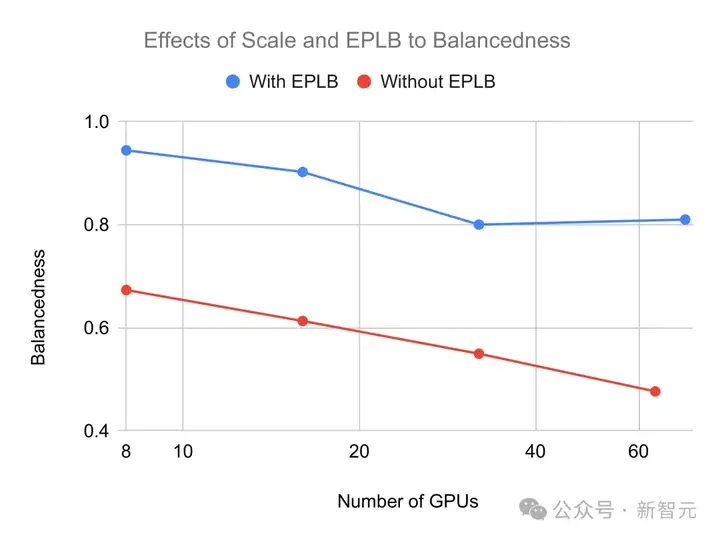
在下图中,团队展示了系统规模和EPLB算法对不平衡问题的影响。
他们将GPU的平衡度,定义为GPU中MoE层的平均计算时间与最大计算时间之比,并使用GPU处理的token数量来估计其计算时间。
从图中可以看出,当系统随着节点数量的增加而扩展时,GPU的利用率会降低,而启用EPLB则可以显著提高了GPU的利用率。
EPLB在实际服务中的应用
为了使EPLB能够有效发挥作用,输入数据的分布必须与实际服务的工作负载高度吻合。通过以下两种策略,可以增强这种吻合度:
即使采用了EPLB,一定程度的不平衡现象仍然难以避免,未来仍需进一步优化。
重新平衡的具体实施方案
SGLang通过三个阶段的重新平衡操作,来确保既高效又不会造成中断,进而在权重更新期间维持系统的性能。
为了突出使用的先进优化技术带来的吞吐量提升,团队使用DeepSeek-V3模型,在一个包含12个节点的集群上,对 SGLang 的不同配置进行了端到端性能评估。
他们比较了以下四种不同的配置:
为了适应不同的工作负载需求,团队分别独立地评估了预填充阶段和解码阶段的性能。
评估结果总结如下:
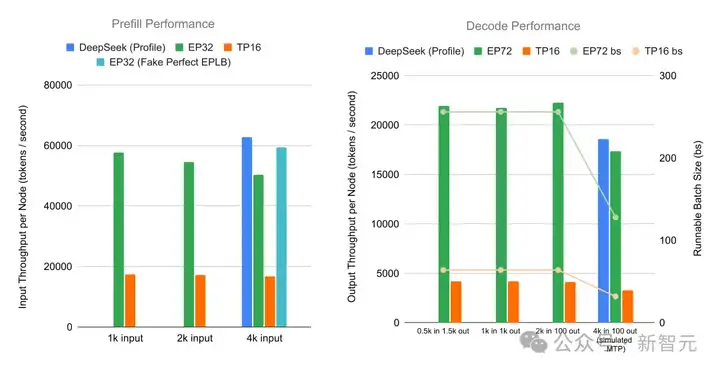
· 预填充阶段:在4个节点的配置下,对于prompt长度分别为1K、2K和4K的情况,系统所实现的单节点吞吐量分别为每秒57,674、54,543和50,302个token。
如下图所示,与TP16基线相比,这种配置实现了高达3.3倍的性能提升。
在假设工作负载完全平衡的前提下,此系统的吞吐量与DeepSeek官方数据之间的差距在5.6%以内。
· 解码阶段:在9个节点的配置下进行评估,对于2K的输入,系统实现的单节点吞吐量为22,282个token/秒,这意味着与TP16基线相比,性能提升了5.2倍。
在模拟MTP条件下,对于4K的输入,系统仍然能够保持每节点17,373个token/秒的高吞吐量,仅比DeepSeek官方性能分析数据低6.6%。
接着,团队将SGLang的性能与DeepSeek的推理系统进行对比,力求使实验设置尽可能贴近DeepSeek的生产环境。
对于预填充阶段,团队测试了一个场景,在该场景中,每个设备处理16,384个token,输入长度为4,096。
考虑到DeepSeek的专家分布存在不确定性,他们评估了两种情况:一种是采用默认的专家分布,另一种是模拟理想状态下的EPLB,并将后者的结果作为性能上限。
评估结果如下所示:
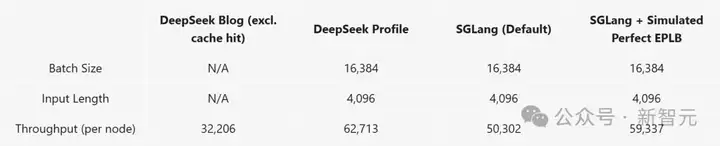
DeepSeek的性能分析数据显示,其所报告的吞吐量大约是其生产环境的两倍。
在默认的专家不平衡情况下,SGLang的性能比DeepSeek的性能分析数据慢20%;而在模拟的理想EPLB情况下,这个差距缩小到了6%。
对于解码阶段,结果如下所示:
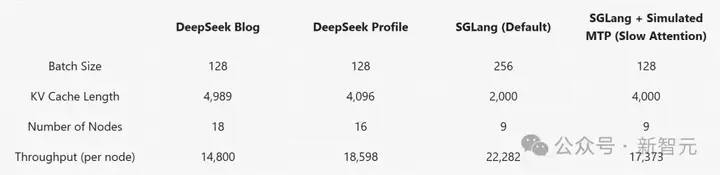
在使用DeepSeek一半数量的节点的情况下,搭载模拟MTP的SGLang仅比DeepSeek的性能分析数据略慢。
在更高的batch大小设置下(256个序列,2,000个输入长度),SGLang实现了每节点每秒22,282个token的处理速度,充分展现了其强大的可扩展性。
下图详细分析了预填充阶段各个内核的执行时间。
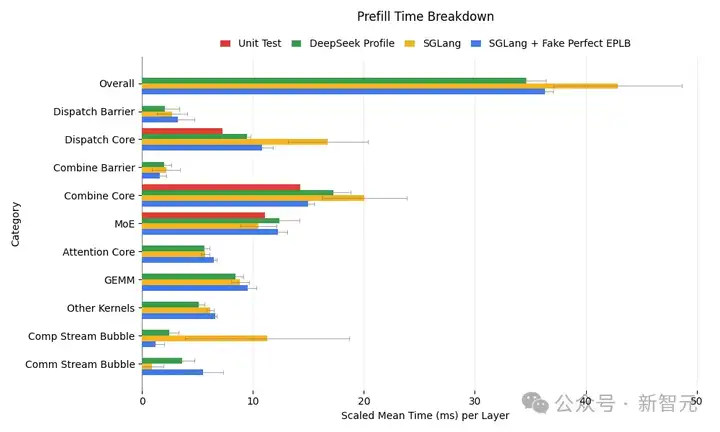
如下图所示,SGLang的解码内核分析结果与DeepSeek的结果非常接近:
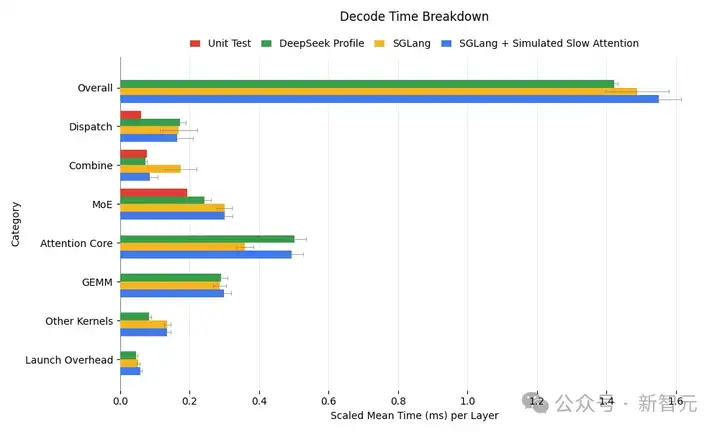
可以看出,SGLang的解码性能在很大程度上与DeepSeek的性能相一致。
因此,下一步的工作重点,就是预填充阶段的优化了。
总的来说,项目在吞吐量上有着显著的提升,但仍然存在一些局限性以及需要增强的领域:
参考资料:
https://lmsys.org/blog/2025-05-05-large-scale-ep/
文章来自于“新智元”,作者“Aeneas 好困”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
