# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。
未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。
然而,这一趋势也带来了严峻挑战:合成数据如果不加控制地使用,可能引发 “模型崩溃”(Model Collapse)问题。
即便仅在一次训练中混入较多比例的合成数据,也可能导致模型性能急剧下降,难以泛化到真实世界的数据中。
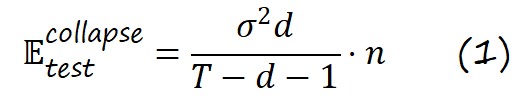
最近在 ICML 2025 会议上,来自上交大等研究机构的研究团队系统性地剖析了这一问题,
并提出了一种创新的数据生成策略,Token-Level Editing,旨在有效避免模型崩溃。

不同于直接使用生成数据,该方法在真实数据上引入细粒度的 “微编辑” 操作,从而构建出结构更稳定、泛化性更强的 “半合成” 数据,有效规避了模型崩溃风险。
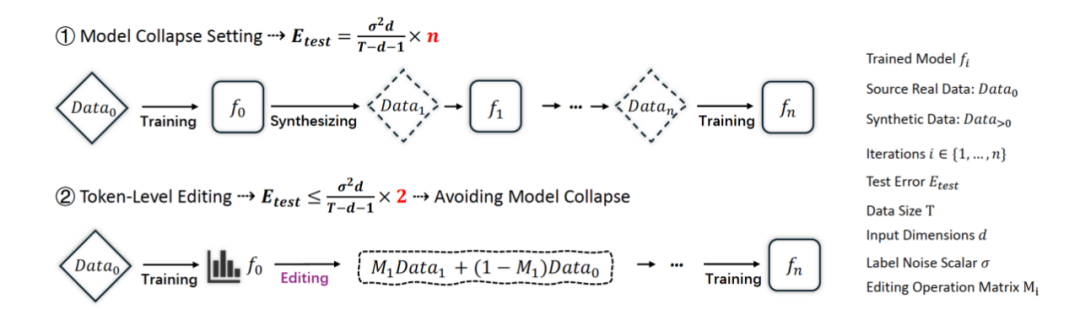
为了揭示合成数据对语言模型训练的影响,研究团队系统分析了不同合成比例下的模型训练行为。
实验显示,即使只进行一次预训练,在数据中混入高比例的合成数据,也会显著导致性能下降。
这种现象被称为非迭代式模型崩溃(Non-iterative Collapse),并在多个语言理解任务上得到了验证。
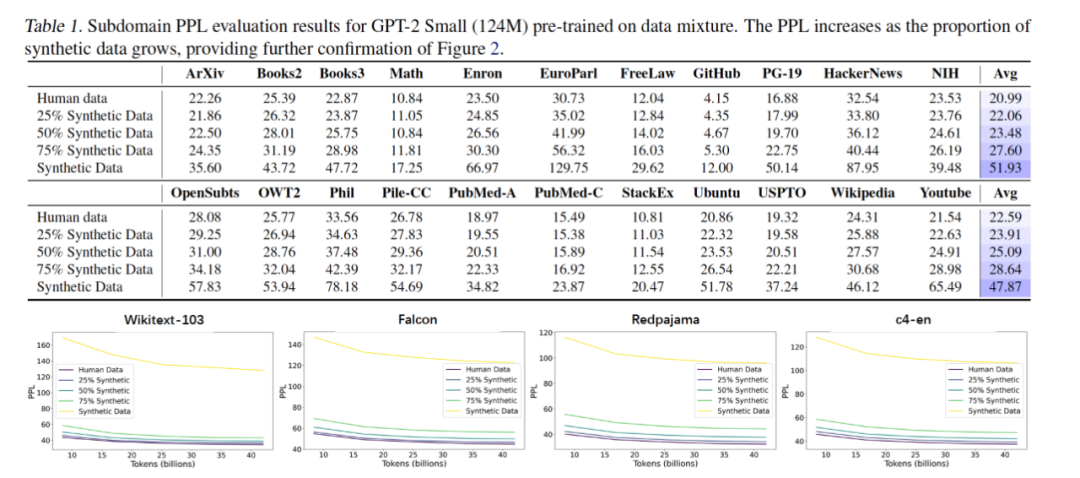
通过进一步统计分析,研究发现,合成数据相较于人工数据存在两类结构性缺陷:
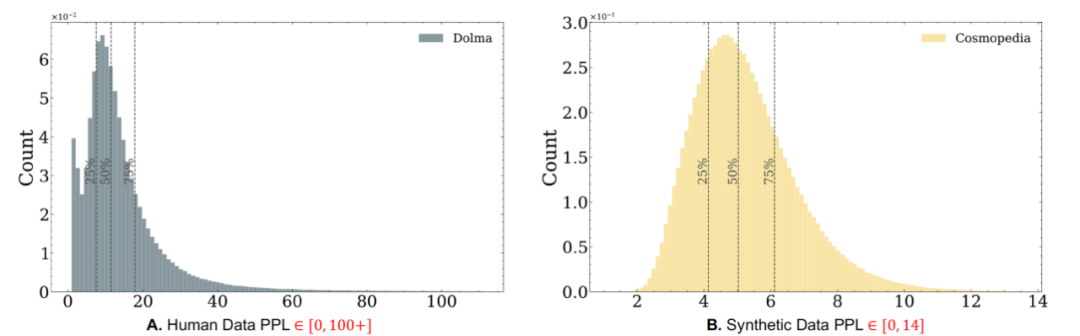

理论结果
测试误差有限上界,避免模型崩溃
作者进一步构建了线性回归分析框架,并证明 Token-Level Editing 过程的测试误差存在固定上界:
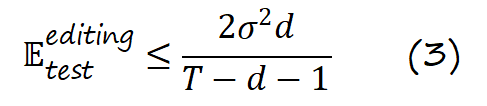

实验结果
从预训练到微调全面验证方法有效性
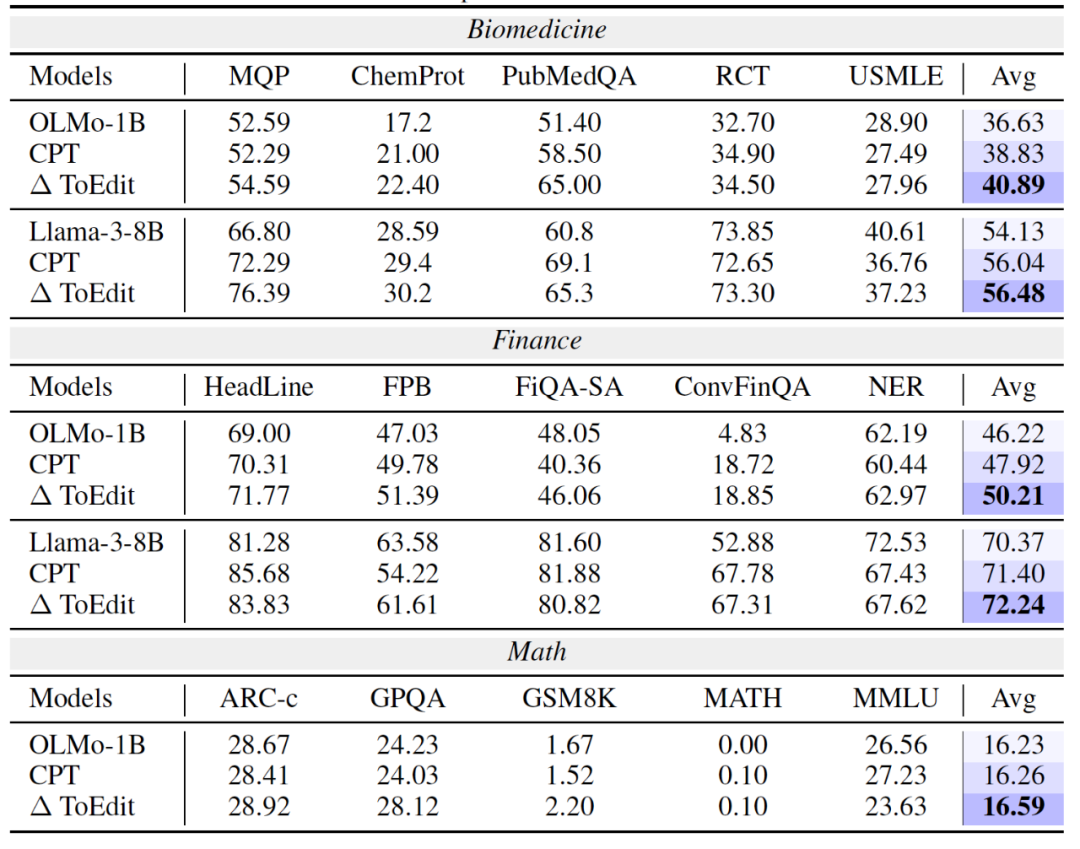
为全面验证 Token-Level Editing 的有效性,研究团队在语言模型训练的三个关键阶段进行了系统实验:
例如在 OLMo-1B 上,整体任务平均分提升了 +0.36 个百分点。
例如在 PubMedQA 任务中,准确率提升高达 +13.6%。
以 LLaMA-3 为例,平均提升 +0.4~0.5%,且在多个任务上保持一致性优势。
此外,为验证方法的稳健性,研究还进行了多轮消融实验,包括:
结果显示:在不增加训练数据规模的前提下,该方法依然具备良好可控性与可迁移性,具备强大的实际落地潜力。
文章来自于微信公众号 “机器之心”,作者 :机器之心



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
