# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近ContextGem很火。它既不是RAG也不是Agent,而是专注于"结构化提取"的框架,它像一个"文档理解层",通过文档中心设计和神经网络技术(SAT)将非结构化文档转化为精确的结构化数据。它可作为RAG的前置处理器、Agent的感知模块,也可独立使用。本质上,它是"结构化提取即服务"的实现,解决了文档数据难提取的行业痛点,更解决了LLM提取的"垃圾进,垃圾出"行业难题。也是一个从论文里走出来的具体经典应用,值得深入实践
📦 GitHub: https://github.com/shcherbak-ai/contextgem
在日常工作中,您是否曾面对堆积如山的文档,里面藏着重要信息,却只能手动复制粘贴或写复杂规则来提取?
这些结构化信息被埋在非结构化文本的海洋中,传统提取方法要么精度不足,要么开发成本高昂,要么难以应对格式变化。当文档数量从几份增长到几百份时,这个问题会变得异常棘手,不仅耗费大量时间,还容易出错且难以扩展。
ContextGem是一个免费开源的LLM框架,由作者Sergii Shcherbak开发。专为文档中的结构化数据提取而设计,它以"零样板代码"的理念彻底改变了数据提取的工作方式。

与其他需要编写大量重复代码的LLM框架不同,ContextGem提供了直观且强大的抽象层,让您只需定义"要提取什么",而不是"如何提取"。它采用文档为中心的架构,整合了自动动态提示生成、精确引用映射、类型验证等多种创新功能,使得复杂文档分析变得简单而可靠。
下图展示了ContextGem的核心架构和各组件之间的关系,清晰呈现了其文档为中心的设计理念:
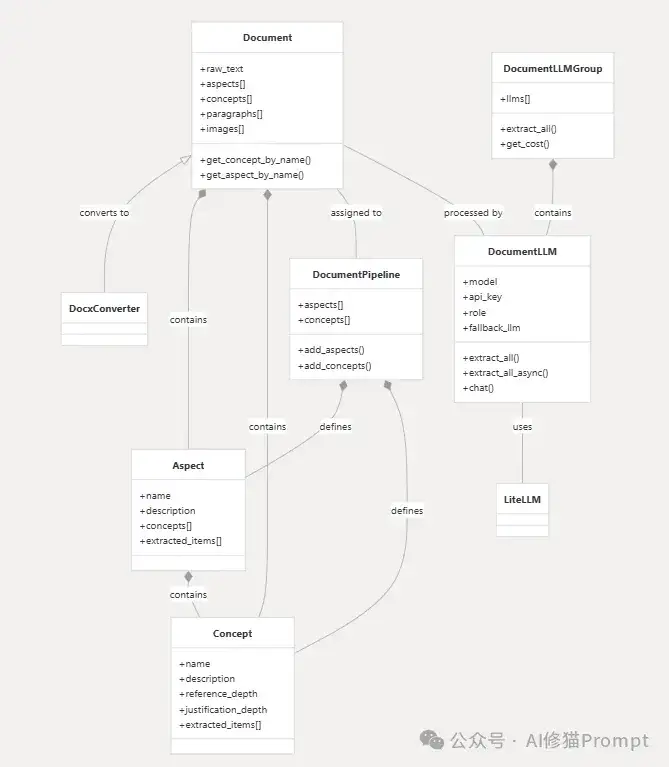
这一架构设计使得ContextGem能够以最小的代码量处理复杂的文档提取任务,同时保持高度的灵活性和可扩展性。所有组件围绕Document模型展开,形成一个完整的提取生态系统。
安装ContextGem的过程异常简单,只需一行命令:
pip install -U contextgem
即可获得这个强大工具的全部功能。ContextGem兼容Python 3.10及以上版本,依赖项已经在安装过程中自动处理,无需额外配置。安装完成后,您可以立即开始构建提取管道,整个过程流畅自然,没有繁琐的环境准备工作。
使用ContextGem极其简单,让我们通过一个实际例子演示:假设您需要从合同中提取异常内容。
1.导入必要组件:
from contextgem import Document, DocumentLLM, StringConcept
2.创建文档对象:
doc = Document(raw_text="合同内容...")
3.定义提取概念:
doc.concepts = [
StringConcept(
name="异常",
description="文档中的异常内容",
add_references=True
)
]
4.配置LLM:
llm = DocumentLLM(
model="openai/deepseek-chat", #或者其他模型
api_key="您的密钥"
5.执行提取:
doc = llm.extract_all(doc)
结果存储在doc.concepts[0].extracted_items中,整个过程只需几行代码!
为了直观展示ContextGem的强大能力,让我们通过一个完整实例来演示如何从产品评测报告中提取结构化数据。以下是一个智能手表产品评测报告的示例文档:
document_text = """
# 产品评测报告:智能手表XYZ-200
## 产品概述
智能手表XYZ-200是2023年推出的新一代智能穿戴设备,售价为1299元,由科技公司Alpha推出。该设备配备了1.5英寸AMOLED显示屏,续航时间约为7天。
## 主要功能
1. 健康监测:心率监测、血氧监测、睡眠分析
2. 运动追踪:支持30种运动模式,包括跑步、游泳、骑行等
3. 智能助手:语音控制、消息通知、天气预报
4. 支付功能:支持NFC支付
## 总结评分
总体评分:8.5/10
性价比:9/10
功能丰富度:8/10
用户体验:8.5/10
硬件质量:9/10
## 购买建议
如果您注重电池续航和基本健康监测功能,XYZ-200是一个很好的选择。但如果您需要丰富的第三方应用支持或独立GPS功能,可能需要考虑其他产品。
"""
使用ContextGem的声明式API,我们可以轻松定义要提取的结构化数据并配置LLM模型:
# 定义要提取的概念
doc.concepts = [
StringConcept(
name="产品名称",
description="产品的完整名称",
add_references=True
),
StringConcept(
name="制造商",
description="产品的制造公司或品牌名称",
add_references=True
),
NumericalConcept(
name="价格",
description="产品的售价,以人民币为单位",
add_references=True,
numeric_type="int"
),
JsonObjectConcept(
name="规格参数",
description="产品的技术规格参数",
add_references=True,
structure={
"屏幕尺寸": str,
"电池续航": str,
"防水深度": str
}
),
NumericalConcept(
name="总体评分",
description="产品的总体评分,满分为10分",
add_references=True,
numeric_type="float"
),
BooleanConcept(
name="推荐购买",
description="基于评测是否推荐购买该产品",
add_references=True
)
]
# 配置LLM并执行提取
llm = DocumentLLM(
model="deepseek/deepseek-chat",
api_key="您的API密钥",
api_base="https://api.deepseek.com",
temperature=0.1
)
doc = llm.extract_all(doc)
运行后,ContextGem成功提取了所有结构化数据:
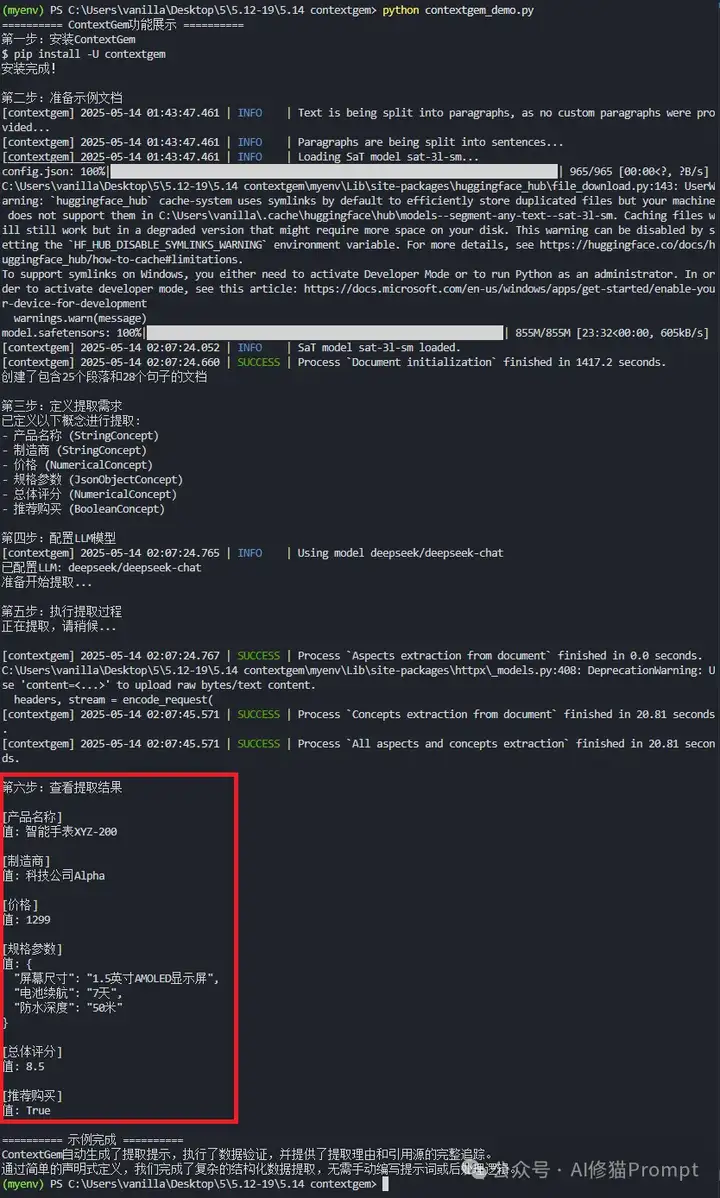
这个实战案例展示了ContextGem的核心优势:
通过简短的几十行代码,我们完成了从非结构化文本到结构化数据的全流程转换,无需编写任何解析逻辑或后处理代码。
在处理复杂文档时,准确的文本分段是提取质量的关键前提。ContextGem引入了业界领先的SAT(Segment Any Text)神经网络模型,彻底改变了文档分析的基础工作。SAT模型在Hugging Face🤗上作为开源模型提供,在上面的运行日志中,您可以清晰的看到在第二步,这个框架需要拉取一个大概1G左右名为sat-3l-sm的模型,框架工作的时候它会下载到本地。关于这个模型您可以从下面的论文中获取所有您想了解的更多信息和模型下载地址以及代码,此处简要介绍。

再次运行实例时,您可能会注意到日志中的Loading SaT model sat-3l-sm...,这正是ContextGem在背后自动加载强大的分段引擎。
论文地址:https://arxiv.org/abs/2406.16678
题目:Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
SAT模型可以说是ContextGem最重要的技术基础之一,它解决了LLM提取的"垃圾进,垃圾出"问题。在整个提取流程中,SAT扮演着"第一道防线"的角色:
虽然SAT并非ContextGem唯一的核心技术,但它与Document模型、Concept类型系统和LLM集成机制一起,构成了框架的"四大支柱"。在实际应用中,您可能会发现,仅仅启用SAT分段就能显著提升提取质量。这是框架的亮点,也可以单独抽取出来抽象到您的Agent设计中。之前我有不少类似的文章,您可以看下《可自定义的推理框架SoT-Agent,通过小路由模型自适应推理,更灵活,更经济 | 最新》或者您也可以使用更大的SAT模型来提高分割精度,或者使用更强大的LLM进行提取,具体您可以看下作者关于优化准确性的介绍
https://contextgem.dev/optimizations/optimization_accuracy.html
SAT模型基于Transformer架构,采用了编码器-解码器设计:
下图展示了ContextGem的完整文档处理工作流程,包括SAT分段在整个流程中的关键位置:
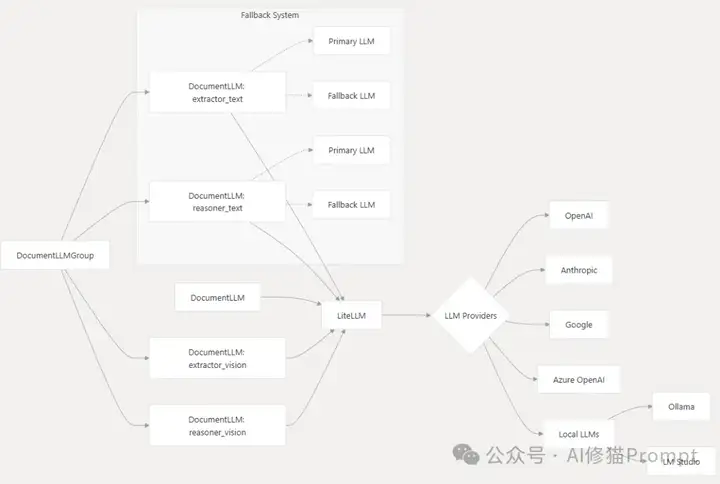
如图所示,SAT分段在文档预处理阶段扮演着至关重要的角色,为后续的结构化提取奠定基础,使ContextGem能够从非结构化文本中提取更精准的结构化数据。
在ContextGem中,Document是一切操作的核心,它不仅是文本的容器,更是一个结构化的信息中心。您可以通过多种方式创建Document对象:
Document对象自动处理文本分段,将原始内容组织为层级结构。
以下是ContextGem的Document模型结构,展示了从原始文档到结构化数据的转换流程:
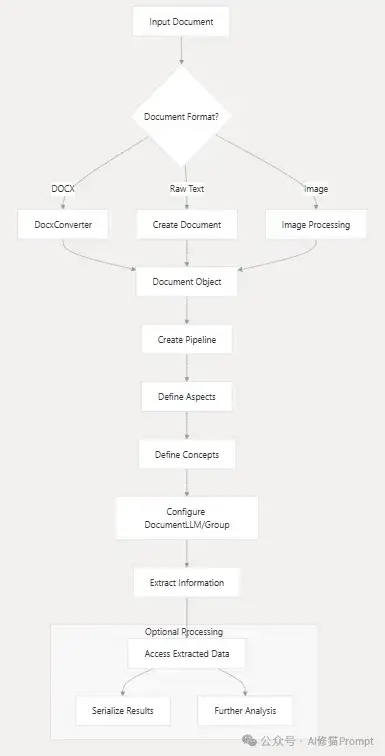
Document模型将原始文档转换为结构化层次,包括段落、句子、概念和方面等组件,为精准提取奠定了坚实基础。这种层次化设计使LLM能够更好地理解文档内容的上下文和结构关系。
ContextGem采用两种核心组件来组织和提取信息:
代表文档中的特定主题或类别,是组织提取内容的结构化方式。可以将Aspect视为文档的"分类目录",例如在合同中创建"付款条款"、"保密条款"等方面。
特点:
专门负责提取特定类型的信息,确保结果的一致性和可靠性。
ContextGem提供多种专用概念类型:
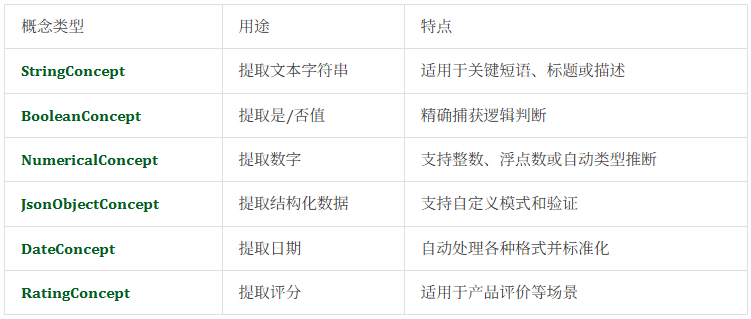
这种丰富的类型体系满足几乎所有数据提取场景,为复杂信息提供精准建模。
用于创建可重用的提取配置。您可以将一组方面和概念组织成一个管道,然后应用于多个文档,确保一致的提取逻辑。
优势:
ContextGem的另一大亮点,支持各种云端服务和本地模型:
1.DocumentLLM:
2.DocumentLLMGroup:
这种灵活的集成机制让您可以根据任务复杂度和成本考虑选择最合适的模型组合。如果用于Agent开发您可以看下《忘掉那个「4+4」吧!Agent开发你至少看过这4个PDF+4个开源项目。 | 万字长文》
不是 RAG 框架
ContextGem 专注于深入的单文档分析,利用 LLM 的长上下文窗口来实现最大的准确性和精确度。它不提供用于跨文档查询或语料库范围信息检索的 RAG 功能。对于这些用例,传统的 RAG 系统(如 LlamaIndex)仍然更合适。
不是Agent框架
ContextGem 并非设计为Agent框架。根据作者对实际提取工作流程的研究,作者认为使用非代理 LLM 工作流程可以更有效地处理深入的单文档数据提取。对于需要代理的使用案例,作者建议使用 LangChain 等框架。由于其简单的 API 和清晰的输出结构,ContextGem 仍然可以作为工具轻松集成到代理框架中,使其成为基于代理的大型系统中文档提取任务的绝佳选择。
ContextGem提供的专用转换器,能将Microsoft Word文档转换为LLM就绪的Document对象。
特点:
除了文本,ContextGem还提供强大的图像处理能力:
虽然ContextGem只内置了DOCX转换器,但其灵活的架构设计允许处理各种来源的文档内容:
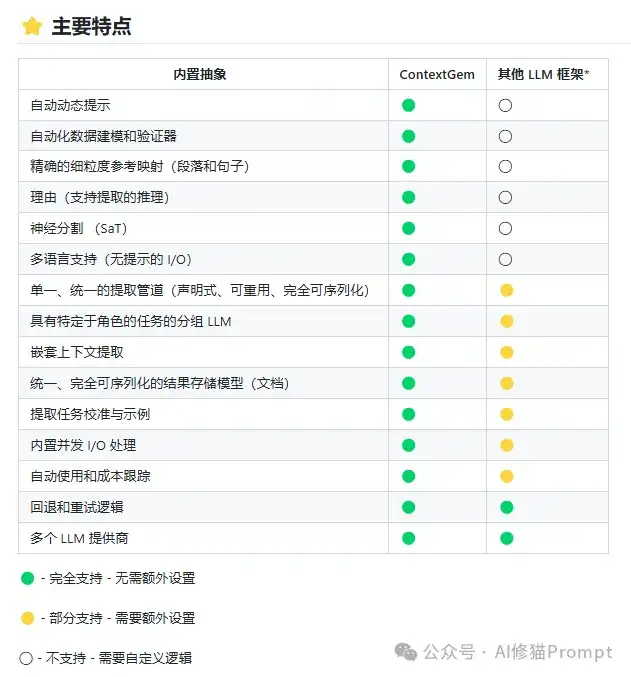
相比其他开源LLM框架,ContextGem提供了更完整的文档处理解决方案,具有多项独特优势:
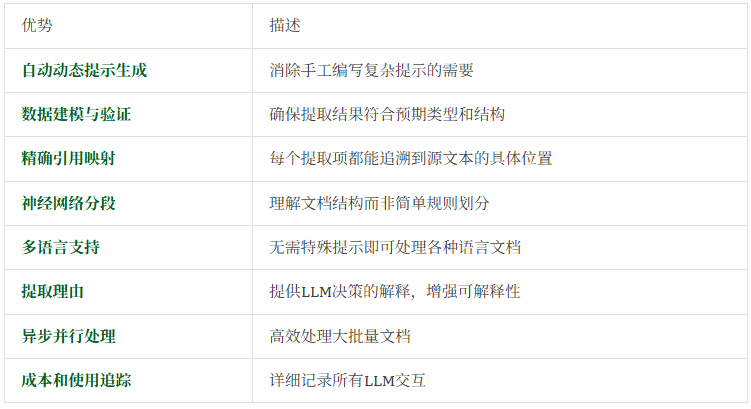
这些优势使ContextGem适用于广泛的应用场景,几乎覆盖所有需要从文档中提取结构化信息的领域:
ContextGem在性能与扩展性方面也做了充分设计,能够处理从单个文档到大规模文档库的各种场景:
这些特性确保了系统在各种规模需求下的可靠性和高效性。
ContextGem彻底改变了从文档中提取结构化数据的方式,将复杂的提取任务转变为简单直观的声明式定义。它消除了传统方法的痛点,提供了一套全面而强大的工具,让开发者能够专注于业务逻辑而非底层实现细节。
无论您是处理法律合同、研究报告还是客户反馈,ContextGem都能帮助您更快、更准确地获取所需信息,释放文档数据的全部价值。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
