# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!
如果机器人能做梦,会怎样?
英伟达新研究项目DreamGen交出了答案。

论文链接:https://arxiv.org/abs/2505.12705
项目链接:https://research.nvidia.com/labs/gear/dreamgen/
DreamGen并非让机器人「看视频」去学习,而是把它们扔进一个神经网络生成的像素级「梦境世界」。
在「做梦」过程中,它们可以自主探索、学习,体验各种场景动作。
通过生成数十万条带有马达动作标签的神经轨迹,DreamGen让机器人能快速掌握新技能,泛化到全新的名词、动词和环境中。
无论是类人机器人(GR1)、工业机械臂(Franka),还是可爱的迷你机器人(HuggingFace SO-100),DreamGen都能让它进入梦境世界。
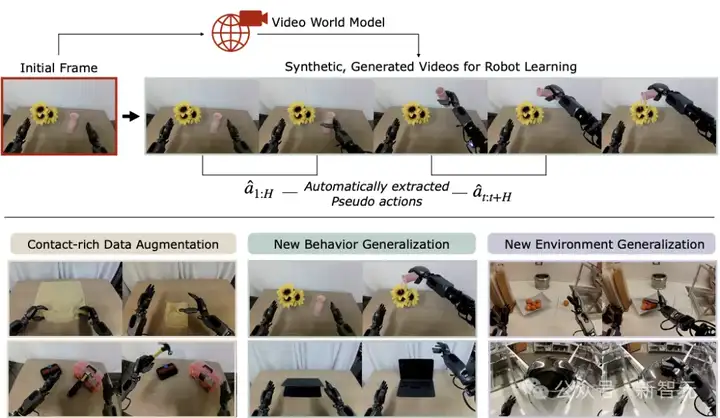
图1:机器人通过DREAMGEN实现泛化
相比传统的图形引擎,DreamGen根本不在意场景中是否有可变形物体、液体、半透明材质、复杂接触或诡异光影。
手工的特征工程,几乎不可能实现这些效果。
而对DreamGen来说,每一个世界只不过是神经网络前向传播的结果。
不管梦境多复杂,它的计算时间始终是恒定的。
DreamGen将其作为合成数据生成器,充分挖掘其在物理推理、自然运动和语言理解方面的先验能力。
首先在已有远程操控数据任务中,研究人员评估了DreamGen生成额外训练数据的效果,涵盖模拟环境和现实世界两个方面。
在模拟环境中,研究者将DreamGen应用于RoboCasa基准测试,将合成数据规模扩展至原始人类演示数据的333倍。
结果显示,随着神经轨迹数量的增加,策略性能呈现对数线性增长(见下图)。
在RoboCasa中扩展神经轨迹的数量
在现实环境中,研究人员在9个多样化任务中进行了验证,使用的机器人包括Fourier GR1、Franka Emika和SO-100。
不同类型的机器人
这些任务涵盖了一些难以在模拟中实现的复杂操作,比如叠毛巾、擦液体、使用锤子以及舀取M&M豆。
在所有类型的机器人上,DreamGen都显著提升了成功率:
GR1的4个任务平均从37%提升至46.4%;
Franka的3个任务平均从23%提升至37%;
SO-100的2个任务平均从21%提升至45.5%;
令人惊艳的是,只用10-13条真实轨迹/任务,类人机器人最终学会了22种新技能。
比如倒水、叠衣服等——尽管它之前从未接触过这些动作。

更厉害的是,他们还把机器人带出了实验室,放进NVIDIA总部的咖啡厅里,DreamGen依然发挥出了神奇效果。

英伟达团队实现了真正的「从零到一」的泛化能力:对陌生动词的成功率从0%提升到43%,在未见过的环境中从0%提升到28%。

像Sora和Veo这样的生成式视频模型,本质上是神经物理引擎。
它们压缩了互联网上数十亿段视频,学习出多种可能的未来——即从任意起始画面推演出的各种可能发展。
DreamGen就是借助了这项能力,包含下列四大流程:
1. 在目标机器人数据上,微调一个最先进的视频模型;
2. 用多样化的语言提示词,引导模型模拟不同的「平行世界」:让机器人在全新场景中「梦见」自己会如何行动。然后筛掉那些没按指令执行的「噩梦」;
3. 利用逆向动力学或潜动作模型,恢复出伪动作标签;
4. 在这个大规模增强后的神经轨迹数据集上,训练机器人基础模型。
就是这样:只是更多的数据,加上传统的监督学习方法。
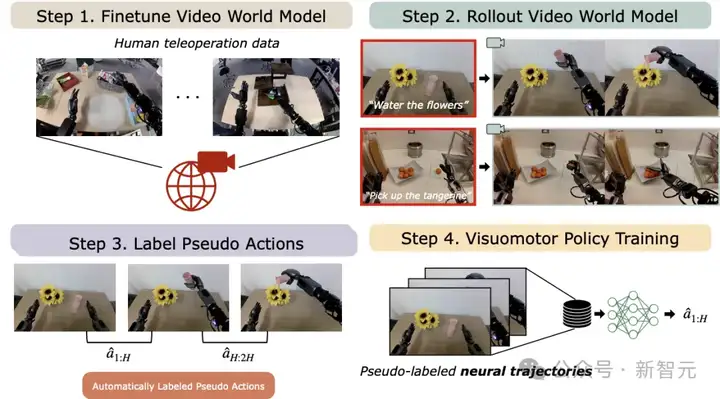
图2:DREAMGEN概览
视频世界模型微调
在第一阶段,研究人员会在人类远程操作的机器人轨迹上对视频世界模型进行微调。
这一步可以帮助模型适应目标机器人的物理限制和运动能力。
为了避免模型在微调过程中「遗忘」原本从互联网上学到的丰富视频知识,默认使用LoRA(Low-Rank Adaptation,低秩适应)方法来对视频世界模型进行微调。
在微调这些模型时,主要关注两个指标:是否能遵循指令以及是否符合物理规律,以此评估模型是否已经很好地适配了目标机器人的任务域。
在大多数下游机器人实验中,研究者用WAN2.1作为基础的视频世界模型。
对于像RoboCasa和DROID这类包含多个视角的数据集,他们会将不同视角拼接成一个2×2的网格(其中一格可能是黑色像素),再对视频世界模型进行微调。
视频世界模型展开(Rollout)
在模型完成对目标机器人形态的微调后,研究人员就可以使用不同的初始画面和语言指令生成合成机器人视频。
模拟实验中:他们从仿真器中采集新的初始画面,并随机设置目标物体或环境的位置。
现实世界实验中:他们手动拍摄新的初始画面,同样随机化目标物体的位置。
环境泛化实验中:他们采集了来自全新环境的初始画面,而视频世界模型的训练数据仍仅来自一个环境。
行为泛化实验中:他们手动设计了新颖的行为提示词,同时将所有候选提示词纳入视频基准测试。

伪动作标签生成
提取伪动作标签的模型有两种架构,如图3所示,其中(a)用于训练逆向动力学模型(IDM)的架构;(b)用于训练潜动作模型(LAPA)的架构。
这两种方法都可用于从生成的视频中提取出相应的伪动作标签,为后续的策略训练提供监督信号。
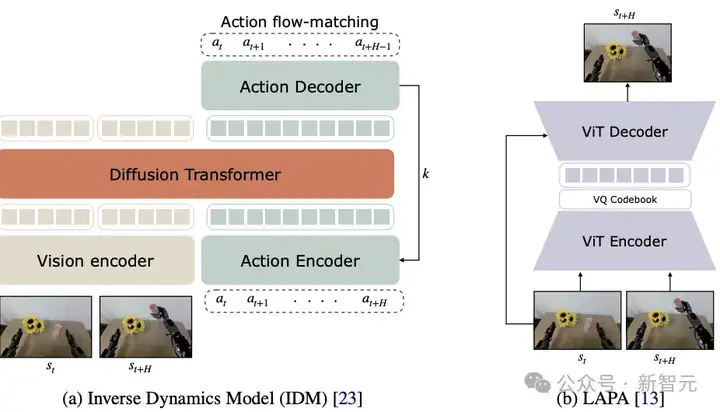
图3:提取伪动作。(a)逆动力学模型(IDM)的架构,(b)潜动作模型的架构
IDM动作生成
对于逆向动力学模型(Inverse Dynamics Model,IDM)的架构,研究人员采用了带有SigLIP-2视觉编码器的扩散Transformer,并使用「流匹配」目标进行训练。
IDM的输入是两帧图像,训练目标是在这两帧之间预测一段连续的动作(见图3)。
他们引入语言或本体感知数据作为输入,因为目标是让IDM模型专注于学习机器人自身的动力学规律。
IDM的训练数据与对应视频世界模型所使用的数据集一致(除非另有说明)。
在训练完成后,使用滑动窗口的方法来进行伪动作标签预测:
潜动作生成
对于潜动作标签的生成,他们采用了LAPA潜动作模型。

论文链接:https://openreview.net/forum?id=VYOe2eBQeh
LAPA使用VQ-VAE(向量量化-变分自编码器)目标进行训练。
在从生成视频中提取潜动作时,将当前帧和1秒之后的未来帧作为条件输入给LAPA模型。
训练潜动作模型时不需要目标机器人的真实动作标签,这使得该方法特别适合跨机器人泛化或数据稀缺场景。
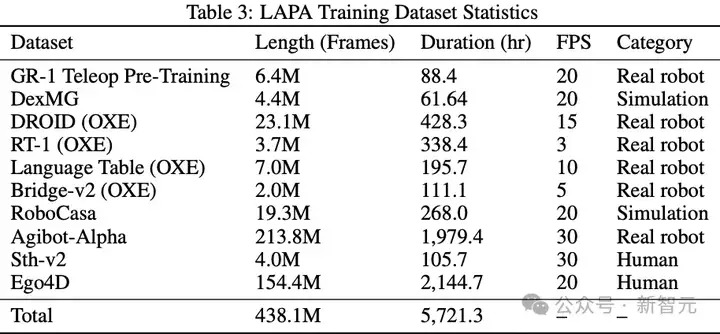
训练该潜动作模型所用的混合数据集详见下表3。
基于神经轨迹的策略训练
最后一步,在由DREAMGEN生成的神经轨迹上,研究人员训练视觉-动作策略模型。
这些策略模型以语言指令和图像观测作为条件输入。由于神经轨迹中不包含状态信息,他们将状态输入部分用全零值填充。
研究团队提出了两种基于神经轨迹进行训练的方式.
1. 与真实轨迹联合训练(co-training)
将神经轨迹与真实机器人数据以1:1的采样比例进行联合训练。
在GR00T N1中,将两类轨迹视为不同的机器人形态,并使用不同的动作编码器和解码器分别处理。
2. 仅使用IDM标签的神经轨迹训练
完全不使用真实数据,只使用由IDM模型标注的神经轨迹进行训练。
在行为泛化与环境泛化实验中,仅使用神经轨迹进行策略训练,进一步验证DREAMGEN在缺乏真实数据情况下的策略泛化能力。
研究团队展示新方法在三个方面的核心应用能力:
1. 用于现有任务的数据增强
2. 泛化到新行为的能力
3. 泛化到新环境的能力
训练数据增强
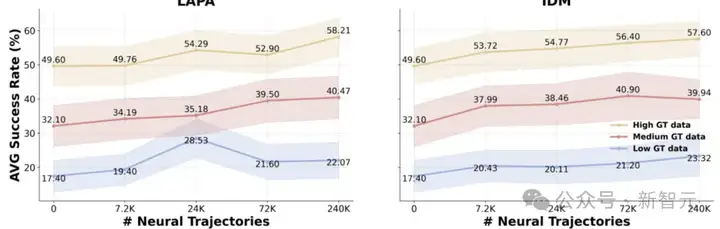
在模拟实验中,在RoboCasa基准任务上,团队对DREAMGEN的流程进行评估,遵循其原始论文中设定的训练和评估协议。
在现实世界实验中,选取了9个真实任务进行评估,涵盖3种不同形态的机器人:类人机器人GR1、机械臂机器人Franka、低成本的机器人臂SO-100。
下图4展示了在不同数量的神经轨迹下,训练的机器人策略性能,分别对应三种真实数据规模:
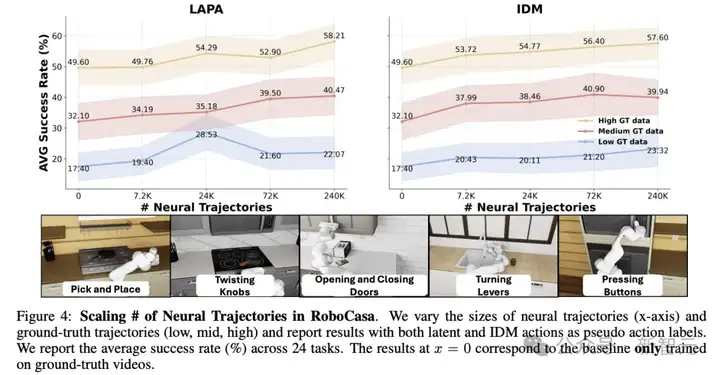
主要观察结果:
1. 联合训练带来一致性提升
由于两者效果相近,但IDM可以支持仅使用神经轨迹进行训练和评估。
2. 神经轨迹数量与策略性能呈对数线性关系
机器人策略的性能与神经轨迹的数量之间呈现出一致的对数线性斜率。
这说明:通过神经轨迹进行合成数据生成相比传统模仿学习中的人工演示采集方式,具有更强的可扩展性和成本效益。
3. 仅用IDM神经轨迹也可获得非凡性能
即便完全不使用真实轨迹,只使用IDM标签的神经轨迹训练策略模型,在24个任务中仍可达到平均20.6%的成功率。
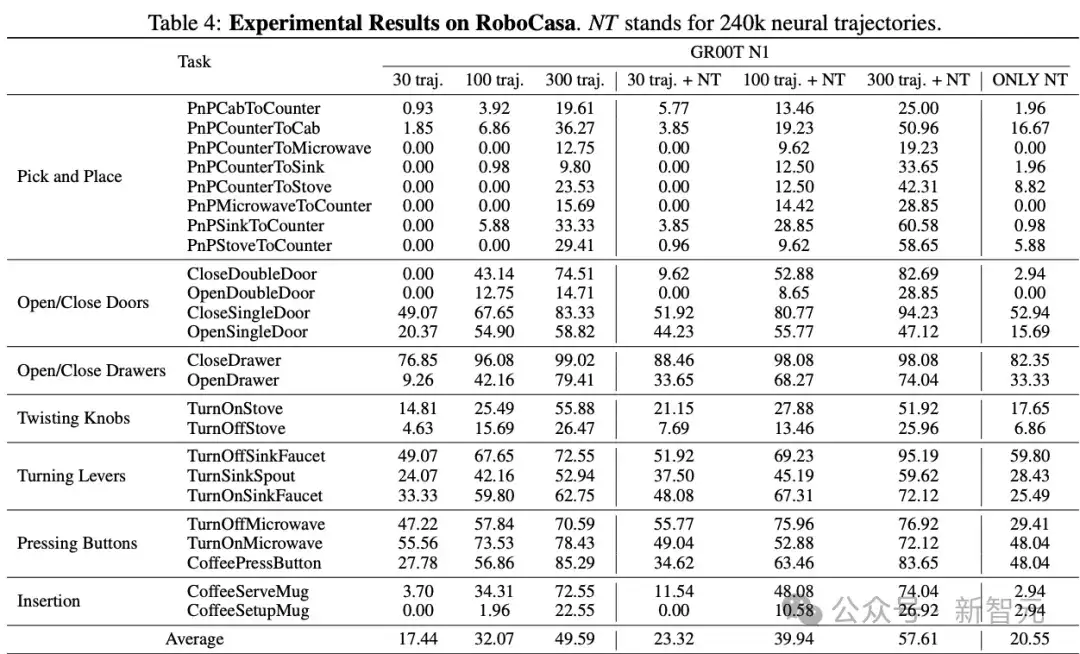
这进一步证明了神经轨迹本身的高质量和有效性。(具体实验结果如下表4。)
现实世界实验
在现实世界实验中,研究团队为每个任务采集如下数量的真实轨迹:
如下图5所示,无论是哪种视觉-动作策略模型(Diffusion Policy、π₀或GR00T N1),在所有机器人形态上,神经轨迹都能持续性地提升在复杂任务中的表现。
这些任务包括:工具操作、操作可变形物体、基础的抓取与放置任务。
这些任务的一个共同特点是:它们在仿真中极难实现。
因为涉及复杂的物理交互(如工具与柔性物体的接触),而目前的模拟技术很难真实复现这些场景,因此传统方法难以通过模拟数据生成有效的训练数据。
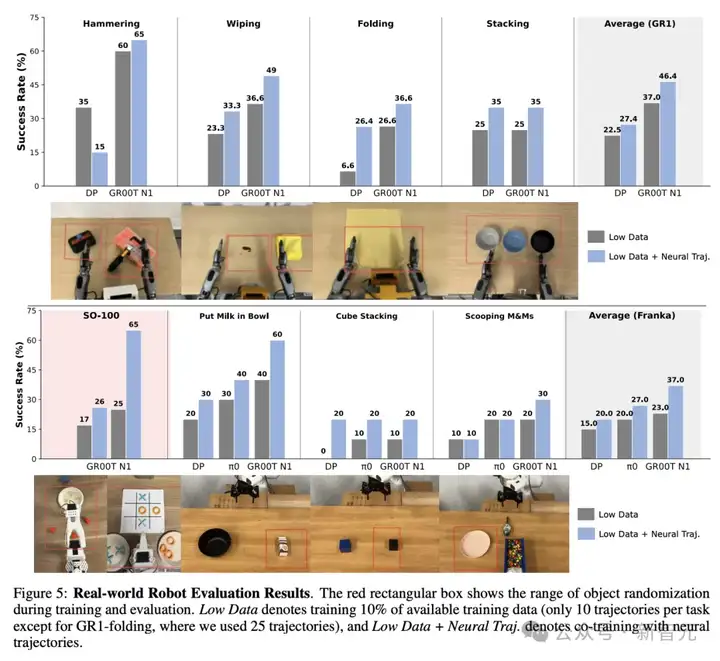
进一步观察还发现,在GR00T N1模型上的性能提升幅度高于Diffusion Policy和π₀。
研究人员推测原因是:
GR00T N1为IDM动作使用了独立的动作编码器和解码器参数 ,这有助于缓解神经轨迹中状态始终为0的影响;
这样的设计增强了模型对神经轨迹结构的适应能力,从而在学习中更好地利用伪动作数据。
解锁泛化能力
为了展示DREAMGEN如何在机器人学习中实现强泛化能力,首先使用2,884条GR1类人机器人在多样化抓取-放置任务中的轨迹,对目标视频世界模型进行训练。
接着,用两个类型的提示词对该模型进行引导:
1. 在已知环境中提示全新行为
2. 在全新环境中提示已知与未知行为
然后生成对应的神经轨迹用于策略训练。
目标物体在环境中的随机化程度如图11所示。该实验中使用的基础策略模型为GR00T N1。
行为泛化
DREAMGEN是否能让机器人仅通过神经轨迹学习新的行为动作,完全不依赖人工远程操作数据。
在这里,「新的行为动作」指的是之前未见过的、全新的动作动词,而不仅是对已有动作的简单变化。
令人惊喜的是:仅依靠一帧初始图像和一句语言指令,视频世界模型就能生成表现出完全未见行为的视频(示例见图12)。

基于这种能力,为14个全新行为任务每个生成50条神经轨迹,并仅用这些轨迹训练下游视觉-动作策略模型。
如表1所示,使用GR00T N1仅在原始2,885条「抓取-放置」轨迹上微调的策略模型,在新行为任务中表现有限(平均成功率为11.8%),主要因为部分任务允许对「拾起动作」打部分分(比如在「倒水」任务中,仅拾起水瓶可得0.5分)。
然而,加入神经轨迹后,策略成功率从11.2%提升至43.2%,这表明DREAMGEN确实可以让机器人学会完全陌生的动词行为。

环境泛化
更令人惊讶的是,当将模型输入来自全新环境的初始画面时,视频世界模型依然能够生成高度真实、合理的机器人视频,这些视频在遵循微调期间学到的运动学规律的同时,还保留了预训练阶段从互联网上学习到的世界知识。
研究人员沿用同样的训练流程,仅使用神经轨迹来训练视觉-动作策略,发现无论是在已知行为(如抓取-放置的变化形式)还是全新行为(如浇花、关盒子、搅拌打蛋器等)上,都能获得不错的成功率(见上表1)。
值得注意的是,与此前研究通过增加环境数量来实现泛化的做法不同,新方法完全不需要额外采集任何物理环境数据。
新研究仅通过采集初始帧来实现泛化,相当于达成了零样本环境迁移(zero-shot transfer)。
最后,作为对比,基线模型仅在一个环境中学习「抓取-放置」任务,对新环境的成功率为0%,完全无法泛化到训练之外的环境。
同时,这次研究还引入了DreamGen Bench,用于机器人的视频生成基准,它与下游机器人策略呈正相关。
因此,视频模型研究人员无需实际设置自己的物理机器人系统,即可帮助实现机器人技术。

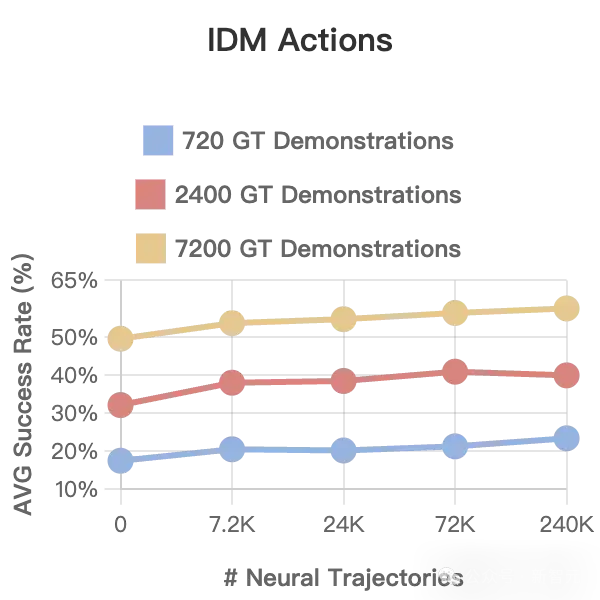
此外,他们在RoboCasa的仿真实验中分析了一个关键问题:增加神经轨迹的数量是否会提升策略性能。
他们通过调整神经轨迹的总数(从0到24万条),在不同真实数据规模(低、中、高)下进行实验评估,并观测其对下游策略表现的影。
他们尝试使用两种方式获取伪动作标签:潜动作模型(LAPA)、逆向动力学模型(IDM)。
主要发现如下:
1. 无论使用LAPA还是IDM,神经轨迹都能在所有数据量场景中显著提升策略性能。
2. 策略性能与神经轨迹总数之间呈现出「对数-线性」增长趋势——即每新增一倍的神经轨迹数量,都会带来稳定的性能提升。
这表明:神经轨迹是一种强大的数据扩展方式,并为机器人学习的可扩展性提供了新的增长维度——
相比依赖大量人工采集的传统模仿学习方法,DREAMGEN所生成的合成数据在性价比与规模化上具有巨大优势。
参考资料:
https://research.nvidia.com/labs/gear/dreamgen/
https://arxiv.org/abs/2505.12705
https://x.com/DrJimFan/status/1924819887139987855
文章来自于“新智元”,作者“KingHZ”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
