# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,华为在MoE训练系统方面,给出了MoE训练算子和内存优化新方案:三大核心算子全面提速,系统吞吐再提20%,Selective R/S实现内存节省70%。
在通往更强大的AI路上,MoE已成为科技巨头另一个首选路径。
只要Scaling Law没有失效,大模型的参数规模依旧不断扩大,由此AI智能水平才能不断攀升。
凭借独特的架构设计,MoE正以前所未有的参数规模,成为突破大规模模型训练的算力瓶颈的关键路径之一。
然而,如何将MoE潜力真正转化为高效的训练实践,一直是业界探索的难题。
此前,华为曾通过Adaptive Pipe&EDPB框架,实现了集群级高效分布式计算,让通信和计算能完美并行,提高训练集群效率。
本次,华为通过昇腾与鲲鹏算力的深度协同,进一步实现了训练算子计算效率和内存利用率大幅提升。
他们从单节点视角出发,深入到NPU和CPU内部,对算子计算、下发、训练内存使用等进行细粒度拆解。
令人惊喜的是,结果显示,MoE训练在之前的基础上,吞吐又提升了20%,内存占用降低了70%。
这不仅是一次技术突破,更是引领MoE训练的风向标。
MoE训练单节点效率提升挑战
现实中,MoE模型的训练并非易事。
因其框架的复杂性,除了集群分布式训练效率优化外,在单节点训练效率提升方面有两大核心挑战。
· 算子计算效率低,存在等待
首先,硬件核心计算单元,如Cube利用率不足,存在冗余操作和可优化的数据流水搬运,进而拖累了整体计算吞吐。
同时,专家路由机制导致算子下发频繁,且容易中断。
因为,复杂的专家路由机制增加了算子下发的调度压力,如同高速闸道入口既窄还有频繁红灯,形成了Host-Bound瓶颈。
· 「昂贵的」NPU内存永远不够用
为了扩展模型参数量以提高模型智能水平,MoE模型参数量动辄千亿甚至万亿。
加之训练过程中前向传播累积的海量激活值,让内存资源显得捉襟见肘。
如果太过挤压内存,还容易引发NPU内存溢出(OOM),造成训练中断。
因此,NPU内存优化是大规模MoE训练永恒的主题。
针对这些难题,华为给出了业界最完整的解决方案。
昇腾算子计算加速
训练吞吐飙升15%
毋庸置疑,只有更高算力的利用率,才能将AI系统的效用最大化。
除了并行策略、通算掩盖等框架层优化方法,硬件亲和算子优化,也是进一步获得潜在性能优化的新路径。
在MoE模型中,最「吃时间」的几个核心算子有:融合算子FlashAttention、基础算子MatMul,以及负责数据重排与反重排的Vector(矢量)算子。
这些算子,占据了总计算耗时75%以上。
从数学等价和昇腾硬件亲和角度出发,华为提出了「瘦身术」、「均衡术」、「搬运术」三大优化策略。
得益于这些方案,MoE模型计算冗余消除,数据流效率提升,同时计算单元间数据移动减少,充分发挥出昇腾的硬件能力。
在Pangu Ultra MoE 718B模型训练实践中,三大算子加速实现整体训练吞吐量提升15%。
FlashAttention「瘦身术」(RECT-FA)
针对FA算子,华为团队优化了计算顺序,进而消除了冗余计算,进一步让FA内部处理流水排布更紧密。
它能支持原生非对齐计算,直接处理Key/Query维度不匹配场景,省去填充与切片开销。
利用昇腾片上缓存原位累加技术,可基于数学等价计算消除旋转位置编码中复杂的拼接操作(如图1所示)。
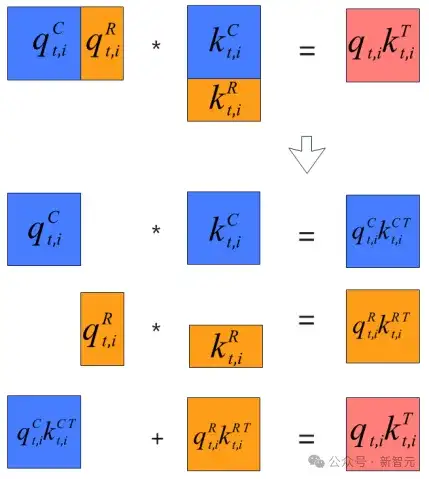
图1:基于数学等价计算消除拼接开销原理
通过核间高效同步与缓存智能预搬运技术,实现FA内部计算步骤的高效流水线衔接,消除等待阻塞。
通过这三点优化,实现FA前/反向性能分别提升50%/30%;
MatMul(矩阵乘法)「均衡术」(AscendP-MM)
针对矩阵乘法算子,华为优化了双级数据流水搬运问题,如下图2所示。
在数据从通用内存传输至L1缓存时,基于更小的L0缓存容量调整搬运量,从而更早启动从L1至L0的搬运,以及后续计算。
通过矩阵子块斜向分配计算核,降低并发冲突,提升数据在芯片内部的流水效率。
最终,实现了Cube(核心计算单元)的利用率提升10%。
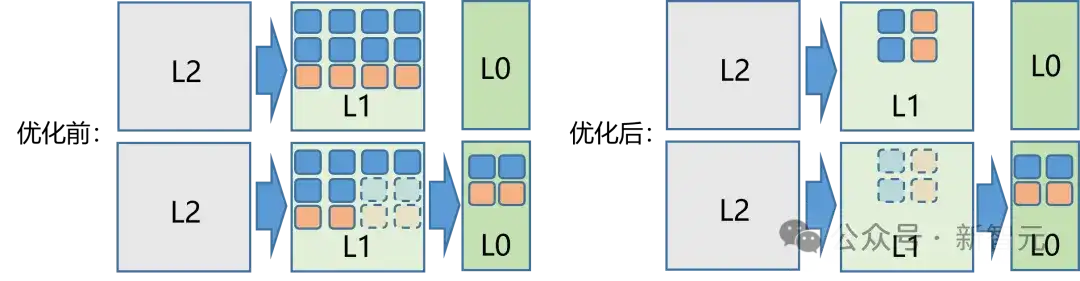
图2:MatMul算子数据流水优化前后示意图
Vector算子「搬运术」(VectorSort)
针对Vector算子,华为充分利用了昇腾芯片Vector指令特性,融合了多个细粒度小算子,以降低内存搬运耗时。
通过等价变换(如图3所示),减少了重排与反重排操作中数据的反复搬运。
上述优化操作的效果立竿见影,VectorSort类算子性能直接飙升3倍以上。
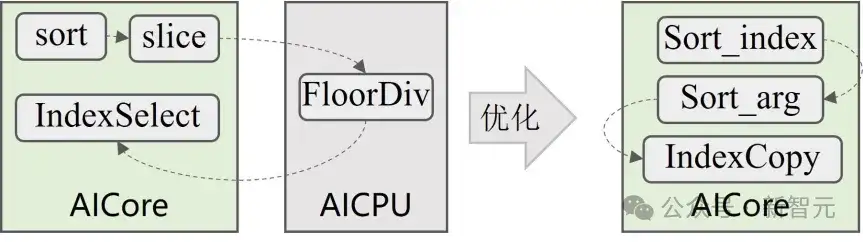
图3:VectorSort重排操作优化前后流水示意图
昇腾鲲鹏协同再加速
吞吐提升至20%,内存节省70%
通过昇腾和鲲鹏的高效协同,华为的研究团队实现了算子下发几乎「零」等待,内存节省70%,其中关键在于Host-Device协同的算子下发优化和Selective R/S精准内存手术两项创新。
鲲鹏Host-昇腾Device协同优化算子下发
· 等效计算的同步消除
算子下发中断通常是因为Host需要等待Device返回结果(即同步),就如同高速有车需要逆行回到闸道入口,会阻塞所有后续算子的下发。
在Host或Device上就地等效计算,避免了数据逆行,实现算子下发无同步。
图4展示Token分发预处理过程的同步消除结果,同步消除后,算子下发不再中断,提高Device上算力利用率。
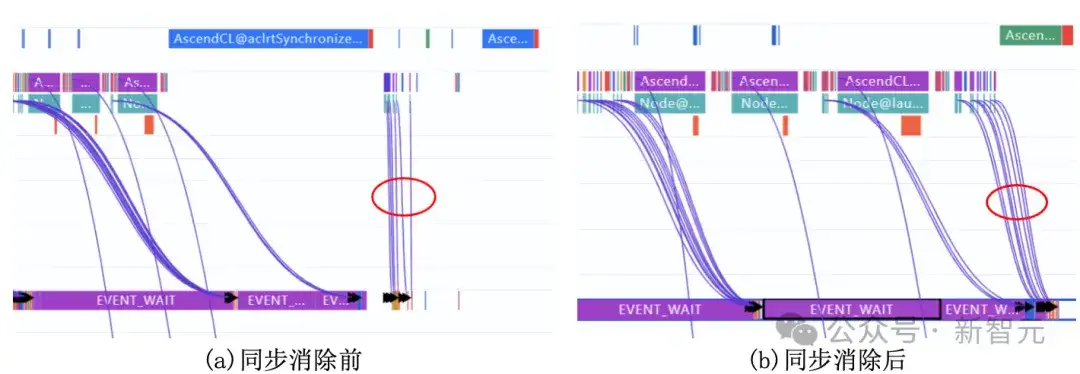
图4:Token分发结果预处理同步消除前后对比
· 重排下发序规避空闲等待
通过对模块的细粒度分离并重排序(图5所示),如同在绿灯后闸道入口优先放行起步快的小车。
这让Device上尽快接收到计算任务,避免过长时间的空闲等待,实现单次Host-Bound从2.1ms降低至0.6ms,超过70%的降幅。
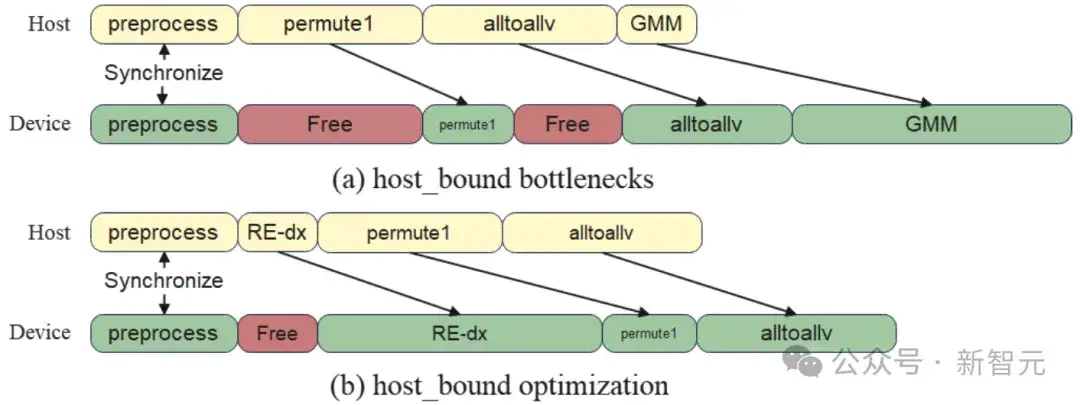
图5:重排下发序规避空闲等待
· 昇腾+鲲鹏亲和提升下发速度
为了发挥算子下发的极致性能,可以通过任务绑核来控制CPU端算子任务的处理器亲和性,将主要任务绑定在最亲和的核上,并隔离其余任务对算子下发线程的影响。
这如同加宽闸道,有助于提升算子的下发速度。
采用自定义粗粒度绑核方式(每NPU绑24核),完全消除系统型持续Host-Bound。
通过上述Host-Device协同优化,有效缓解了同步型与持续型Host-Bound瓶颈。
在Pangu Ultra MoE 718B模型训练实践中,团队实现了算子下发几乎零等待(free时间占比<2%),训练吞吐量进一步提升4%,充分发挥算子加速优势,两者叠加可加速训练19.6%。
Selective R/S精准内存手术方案
基于昇腾+鲲鹏内存协同架构,研究团队提出了Selective R/S内存优化技术。
这项创新实现了对Pangu Ultra MoE 718B模型训练多维度、定制化的「内存解剖」,在训练实践中可节省超过70%的激活值内存。
这项技术主要分为两大部分:
(1)丰富多样的、通用化、张量级的细粒度重计算以及Swap策略等组成的「显微手术器械库」;
(2)可自适应内存系统优化的「手术台管理机制」。
· 细粒度重计算(R)与Swap(S)
华为实现了多个模块重计算的细粒度支持(如表1左所示)。
而且系统可以自适应调整重计算算子的执行顺序,巧妙地「隐藏」了重计算产生的额外耗时。
对于重计算过程也做了优化,包括:
· MLA重计算创新性地调整了计算顺序,将KV的计算与Q解耦;
· RmsNorm重计算同时兼容了Sandwich Norm和Pre Norm;
· Permute重计算支持Token重排操作中计算与通信重计算;
· Activation重计算支持激活函数以及Prob前移乘法重计算。
在Swap方面,昇腾+鲲鹏内存协同化管理,实现了Attention模块内激活值的张量级卸载和预取,提供了灵活的Swap策略选择,并为MoE层中重计算代价高昂的模块设计了Swap方案(如表1右所示)。
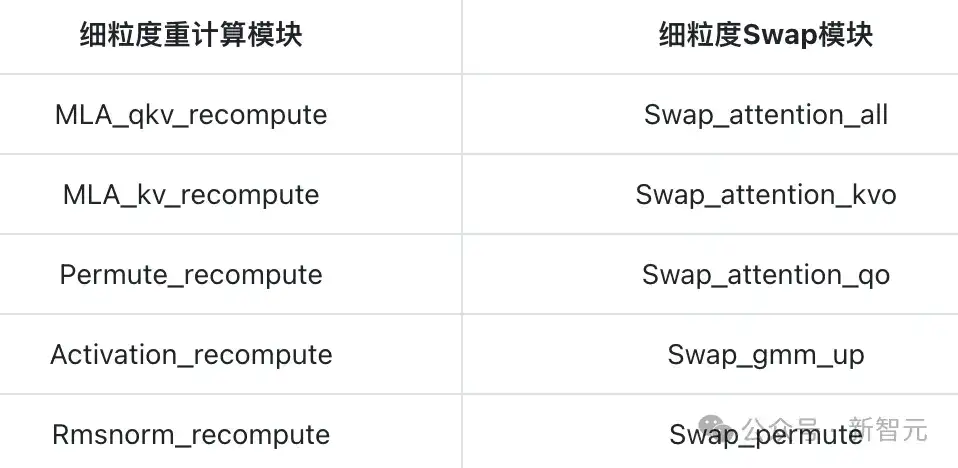
表1:已实现的细粒度重计算与Swap方案
如图6所示,通过对激活值卸载与预取位置的精准调整,有效规避HBM读写竞争带来的性能劣化。
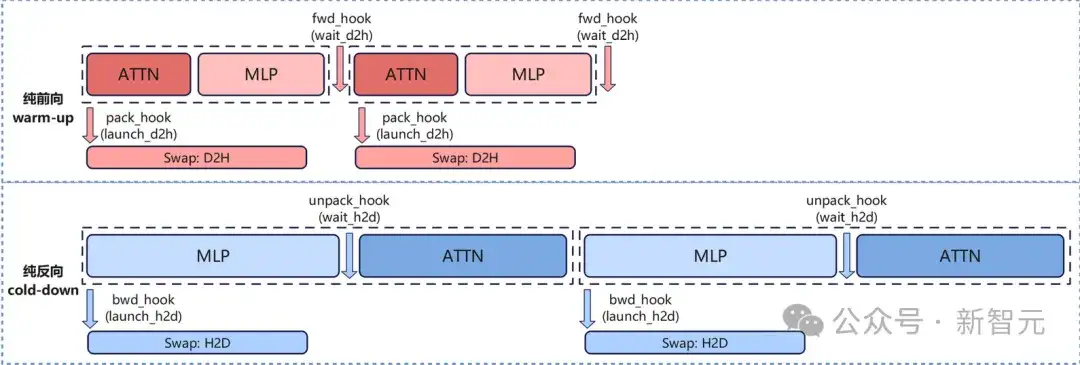
图6:Swap_attention卸载&预取的时机
· 自适应内存优化管理机制
内存优化管理机制的主要指标是Memory-Runtime(节省内存/额外耗时)性价比。
为了找到最优的自适应内存优化策略组合,需要先计算模型训练的内存占用。
以「先增后减」的贪心算法作为基础选择机制,并结合对Swap带宽竞争的分析,基于已实现的内存优化策略,最终给出最优的策略组合。
国产AI训练优化新方案
华为昇腾+鲲鹏深度协同,结合算子计算加速和内存优化技术,为MoE训练提供了高效、低成本的解决方案。
无论是三大算子加速、鲲鹏昇腾协同的算子下发「零等待」,还是激活内存节省70%,都展现了华为在AI算力领域的深厚技术积累。
这不仅为大规模MoE模型训练扫清了障碍,也为行业提供了宝贵的参考路径。想要了解更多技术细节,请查阅完整技术报告。
报告地址:https://gitcode.com/ascend-tribe/ascend-training-system/tree/main/StandaloneOptimization
文章来自公众号“ 新智元”



