# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)。
然而,现有的benchmark大多缺乏对逻辑推理类型的明确分类,以及对逻辑推理的理解不够清晰,常将感知能力或知识广度与推理能力混淆。
在此背景下,复旦大学及香港中文大学MMLab联合上海人工智能实验室等多家单位,提出了MME-Reasoning,旨在全面的评估多模态大模型的推理能力。

结果显示,最优模型得分仅60%左右。
根据Charles Sanders Peirce的分类标准,推理分为三类:演绎推理 (Deductive)、归纳推理 (Inductive) 以及溯因推理 (Abductive)。
MME-Reasoning以此分类作为标准来全面的测评多模态大模型的推理能力。
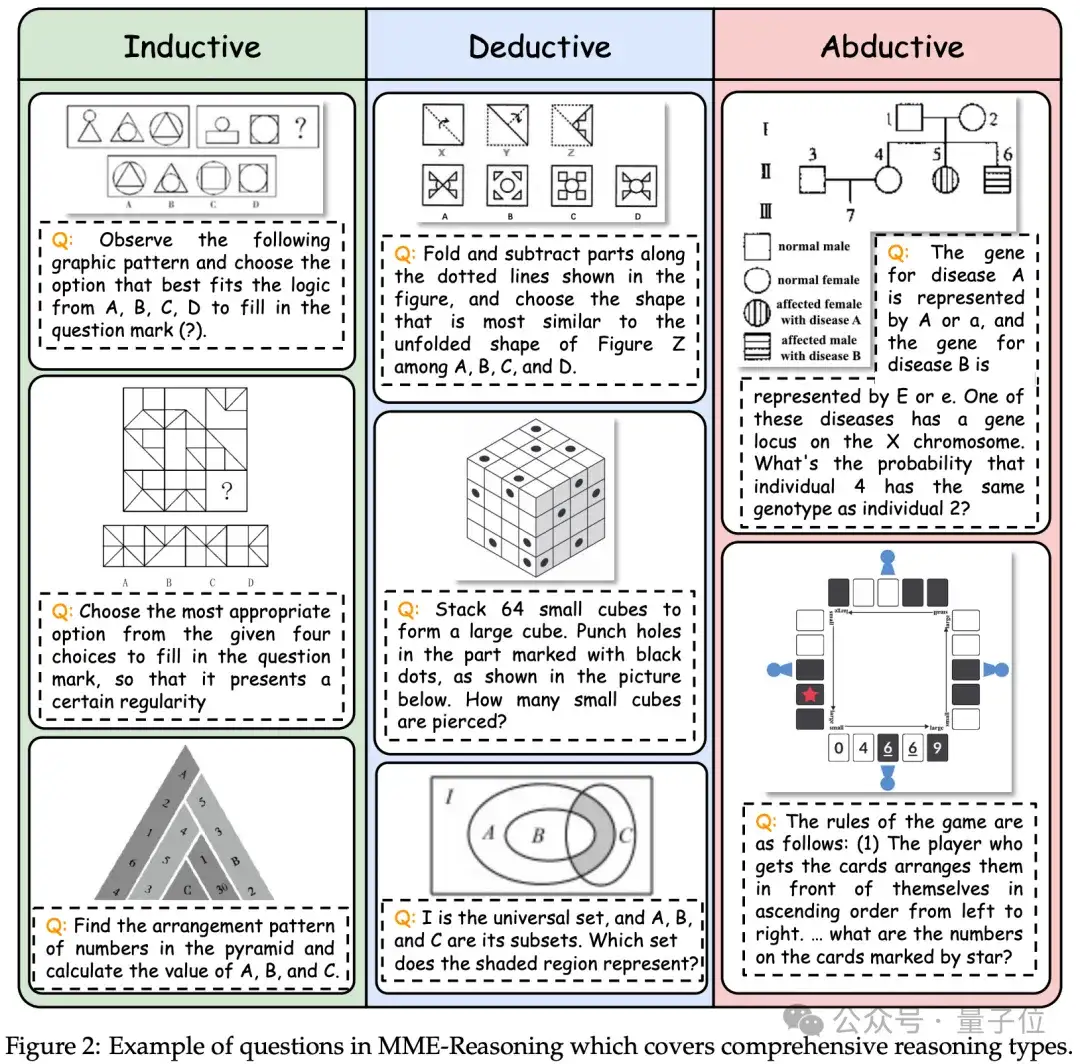
MME-Reasoning全面涵盖三种推理类型 (归纳、演绎和溯因) 并包括三种问题类型 (选择题、自由形式和基于规则验证的题目)。
进一步,根据难度,MME-Reasoning被分为三个难度级别。
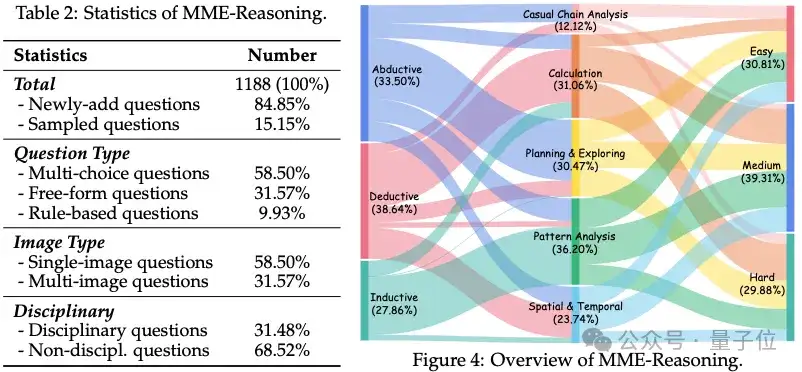
为了更加全面的测评,并避免由于学科知识的复杂程度干扰对推理能力的测试,MME-Reasoning按照以下标准进行设计:
通过在广泛数据来源 (教科书、互联网、逻辑练习题、程序合成、重新出题等) 中根据上述标注进行筛选并标注,MME-Reasoning最终由1188个题目构成,每道题目的标注都包含了推理类型、难度、题目类型。此外,作者对题目考验的能力进行了分类,包含模式分析、规划与探索、空间与时间、计算、因果链分析五类并对每道问题进行标注 (问题可能考察一个或多个上述能力)。

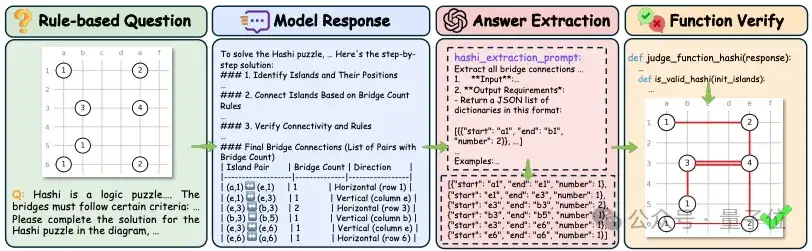
在评测方式上,所有的回答都先经过GPT抽取答案。对不同的题目类型,通过不同的方式进行判断:
文中对30+个模型进行了评测包括:
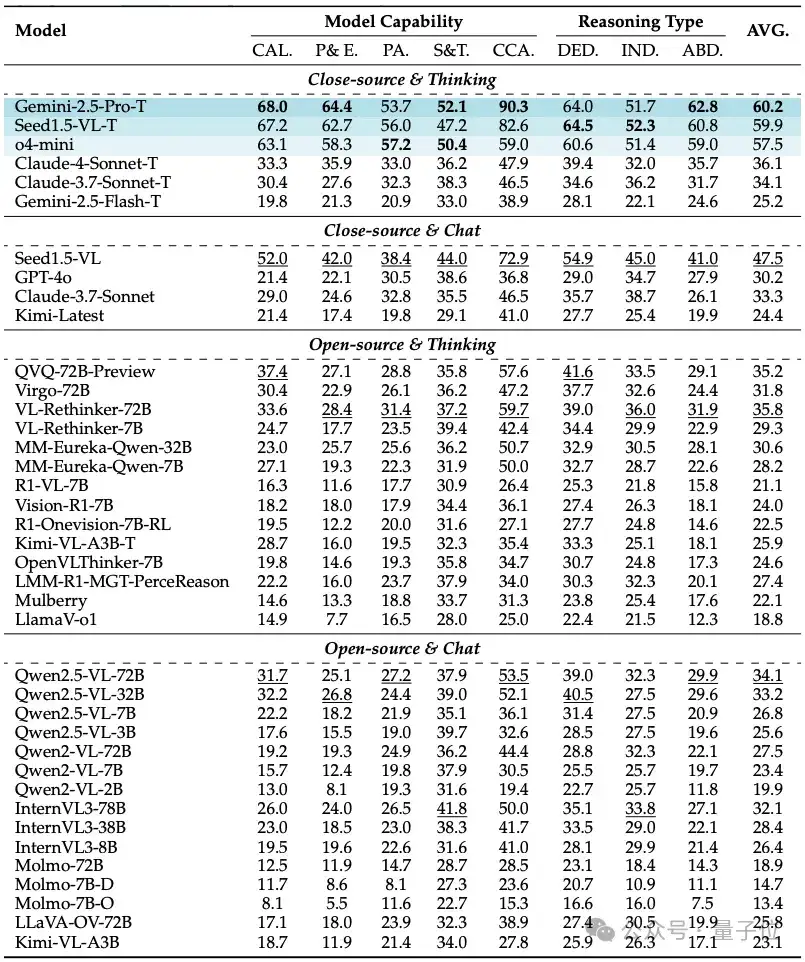
通过评测,作者发现MME-Reasoning对视觉-语言推理提出了极大挑战:当前最优模型得分仅60%左右,显示该基准对模型逻辑推理能力要求极高,能全面考察三种不同推理类型。
此外,多模态大模型逻辑推理能力存在显著偏差,模型普遍在演绎推理上表现较好,但溯因推理能力明显较弱,尤其是开源模型,溯因推理成为整体推理能力的瓶颈。
以及开放式推理场景下模型表现有限,模型在计划与探索类任务上表现较差,暴露了当前模型在开放式问题求解中的短板。
基于规则的强化学习效果有限,尽管规则强化学习能激活模型的“思考模式”,但在7B规模模型上未必提升推理表现,甚至可能降低泛化能力,表明训练范式创新亟需突破。
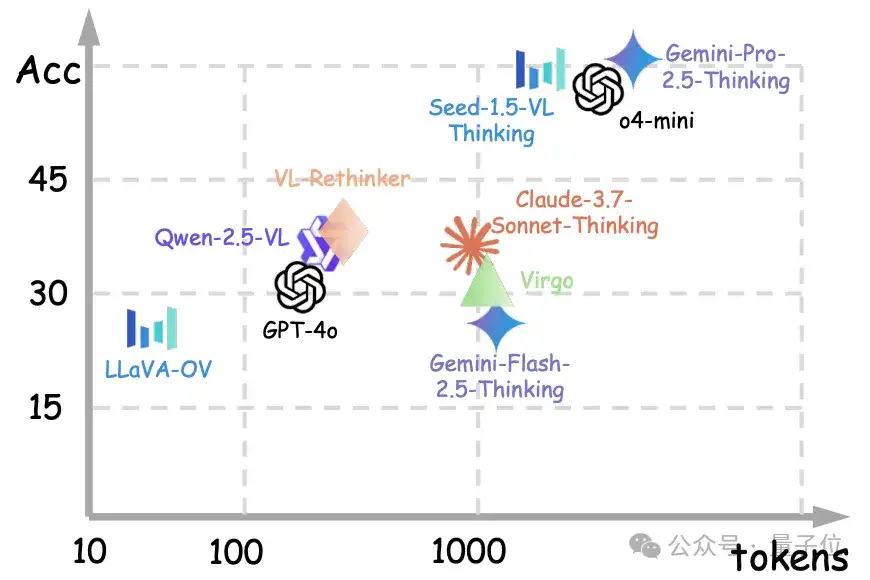
而“思考模式”显著提升逻辑推理能力,采用链式思维、反思和自我纠错等“思考模式”的模型,推理表现普遍优于基础版本,尤其在闭源模型中提升更为明显。
此外,通过对回答所需token数量的分析,发现虽然推理过程加长有助于提升准确率,但是这种提升效果存在边际递减随着输出长度增加,但收益逐渐减小,同时带来计算成本显著增加。
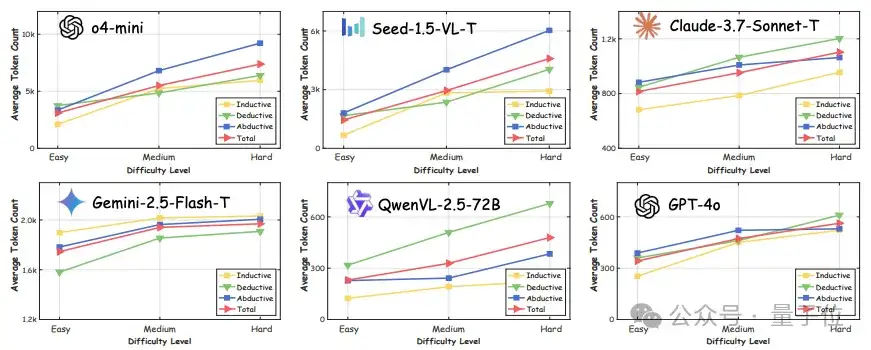
同时,随着推理难度的提升,模型所需的token数量也会明显提升。
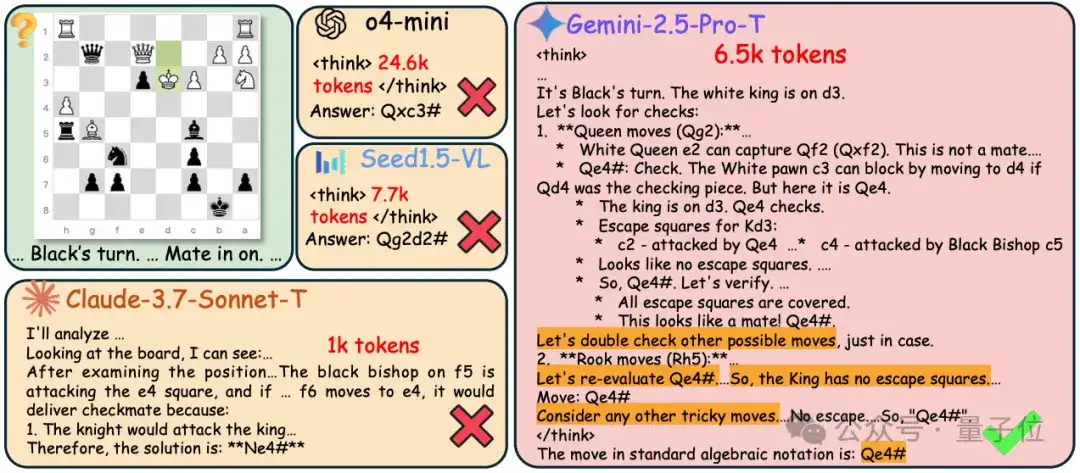
对不同模型在MME-Reasoning上的Case study的分析显示:
较长的推理过程:所选模型在响应中生成超过1k个token,其中o4-mini生成高达24.6k个token。这表明MME-Reasoning构成了一个高度具有挑战性的多模态推理基准。
推理中的规划行为:响应包括多个“假设生成-可行性验证-检查与反思”迭代,表明模型自发地参与结构化规划和反思,以在开放式问题解决空间内探索解决方案。
重复反思:模型倾向于多次重新访问和反思相同的推理路径——在某些情况下多达7次。这种行为可能会导致显著的计算开销和信息冗余。
论文链接:https://arxiv.org/pdf/2505.21327
代码链接:https://github.com/Alpha-Innovator/MME-Reasoning
数据集链接:https://huggingface.co/datasets/U4R/MME-Reasoning
文章来自公众号“量子位”,作者“MME团队”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
