# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
用AI来整理会议内容,已经是人类的常规操作。
不过,你猜怎么着?面对1000道多步骤音频推理题时,30款AI模型竟然几乎全军覆没,很多开源模型表现甚至接近瞎猜。
就连表现最好的开源模型Qwen-2.5-Omni,准确率也只有56.7%;而闭源选手Gemini 2.0 Flash则以65.6%的成绩一骑绝尘,遥遥领先全场。
这一全新基准测试MMAR来自上海交通大学、 南洋理工大学、伦敦玛丽皇后大学、字节跳动、2077AI开源基金会等研究机构。

MMAR 是什么?它有多难?
MMAR全称是:A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix。
简单来说,它是一个包含1000个高质量问题的音频理解评估基准,每个问题都要求模型具备多步骤的深度推理能力。
我们先来看个例子:
问题是:理发师能否听懂英文?
在这段音频中,被理发的人用英语反复强调自己想要的理发效果,另一个人将其翻译成中文来帮助他强调,这说明理发师不能听懂英文,需要旁人翻译为中文。这个问题考察音频大模型对于多说话人交互和复杂语义的理解和推理能力,属实不易。
而这样的例子有整整1000题,由标注者们头脑风暴并精心标注,还通过了严格的审核程序。其他的例子包括:
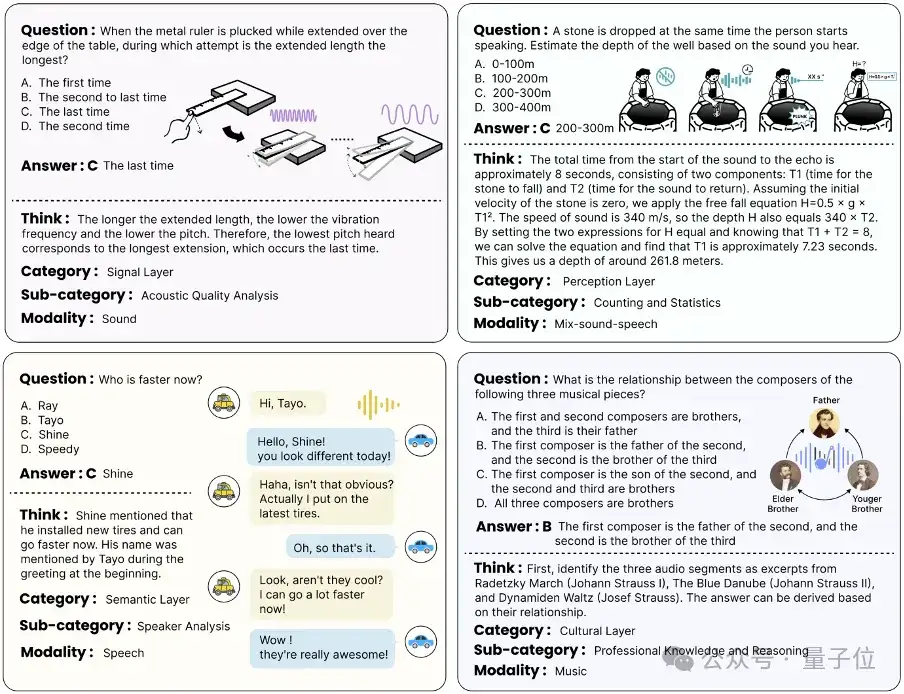
△MMAR基准测试中的例子
这些问题覆盖了四个层级的推理能力:
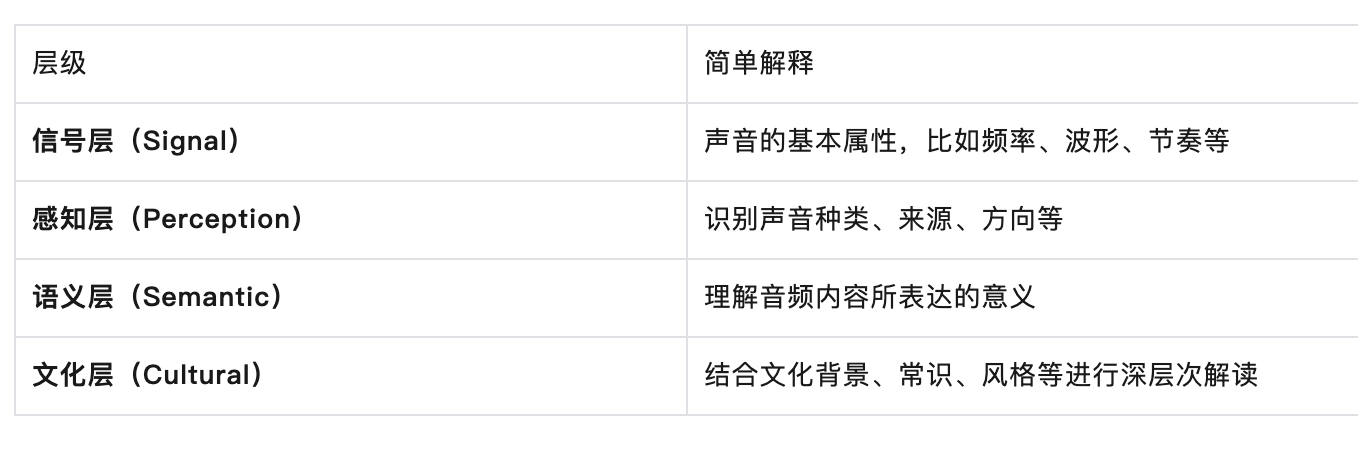
而且,每个任务都需要多步推理,其中一些任务甚至需要极富挑战性的感知技能和领域特定知识,音频包含真实场景的语音、音乐、环境事件声音和他们的混合,相当的有难度。
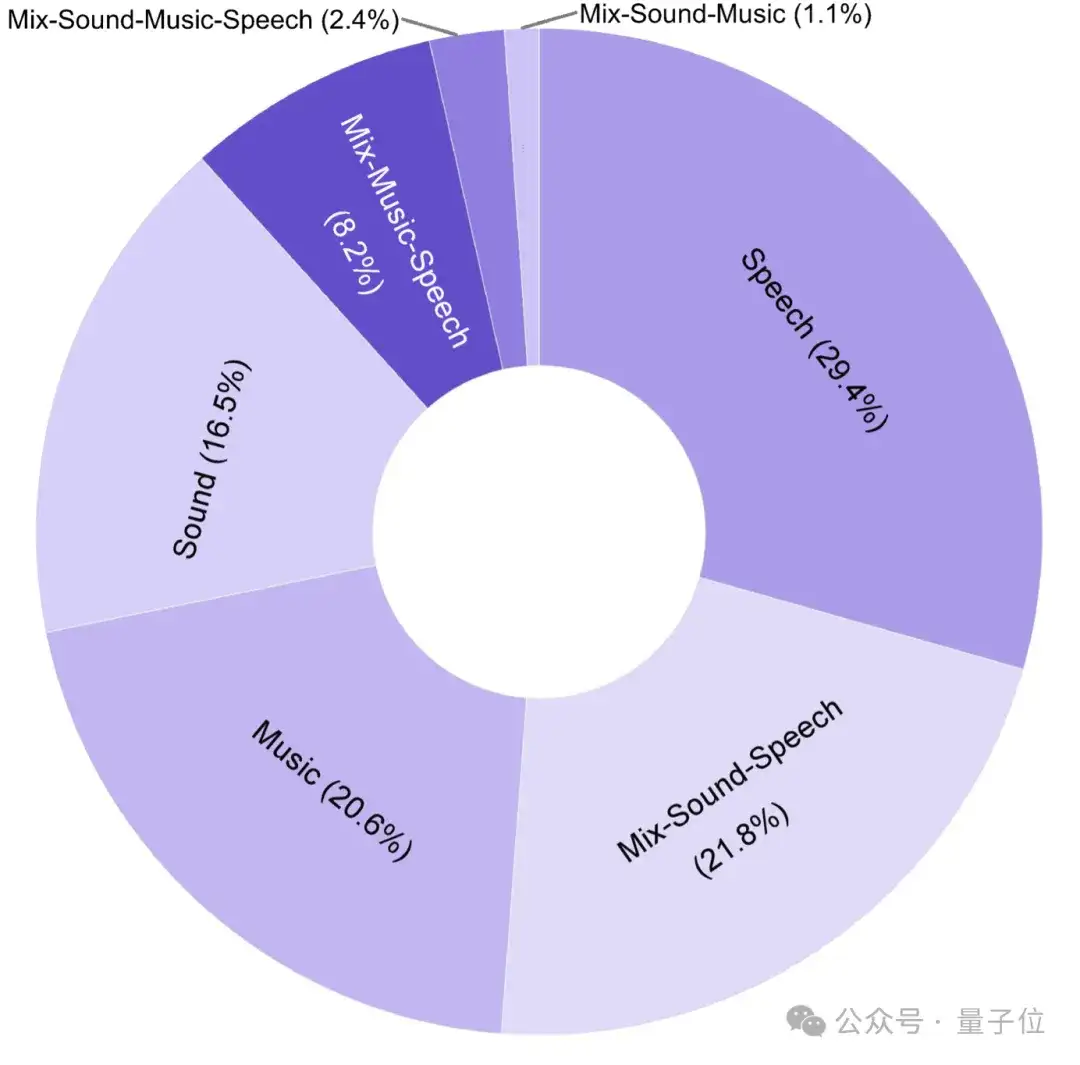
△MMAR音频数据的语音、音乐、环境事件声音和他们混合的类别分布
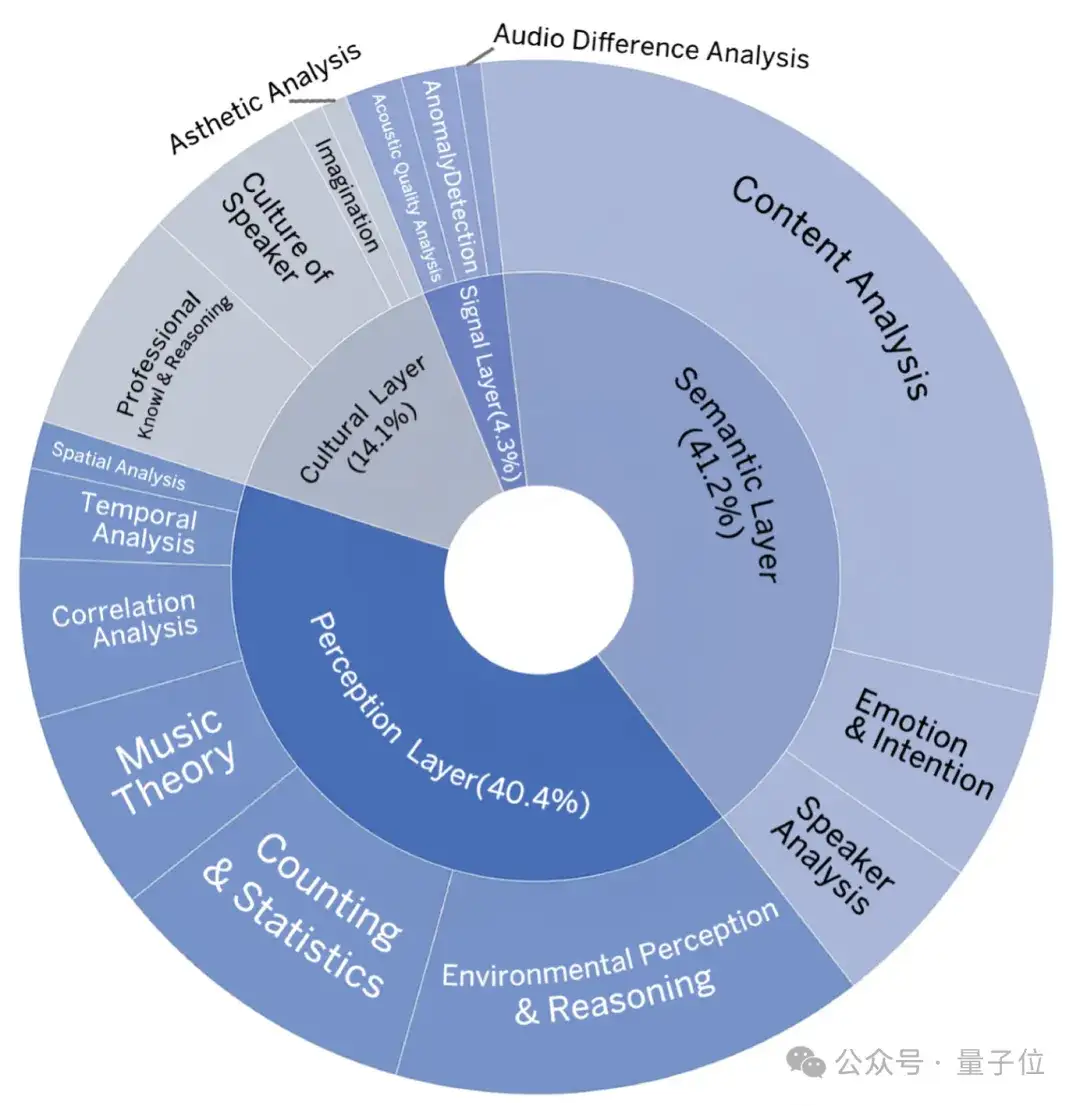
△MMAR的推理层级和任务类别分布
测试结果:AI 在“听”方面到底怎么样?
研究团队一口气测试了30款音频相关模型,包括 LALMs(大型音频语言模型)、LARMs(大型音频推理模型)、OLMs(全能型多模态模型)等等。结果让人有点哭笑不得:
这说明了什么?
说明当前大多数开源模型,在面对复杂音频推理任务时,还远远没达到实用水平。

△泊松二项分布展示了随机猜测下准确率的P值
更令人惊讶的是,在音乐相关的任务中,几乎所有模型都“掉了链子”。这说明当前模型在识别旋律、节奏结构、作曲风格等深层次音频信息方面仍存在巨大挑战。
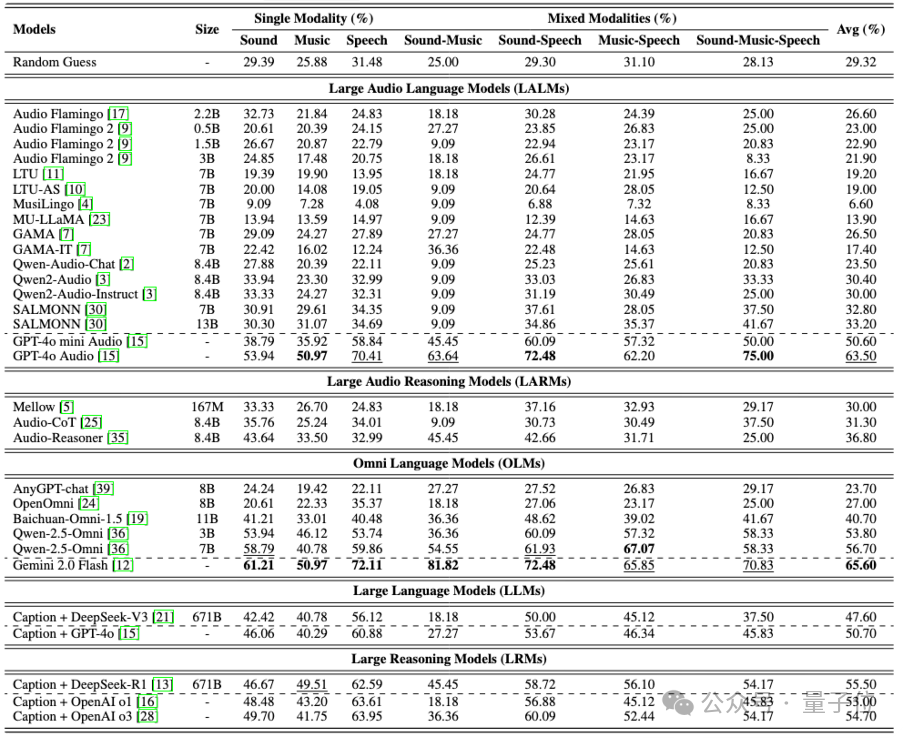
△五类模型在MMAR基准上的结果
其次,具有显式推理能力的模型始终优于不具备显式推理能力的模型。例如,Audio-Reasoner的表现优于Qwen2-Audio和Qwen2-Audio-Instruct,而音频摘要+ DeepSeek-R1 的表现优于音频摘要+ DeepSeek-V3。
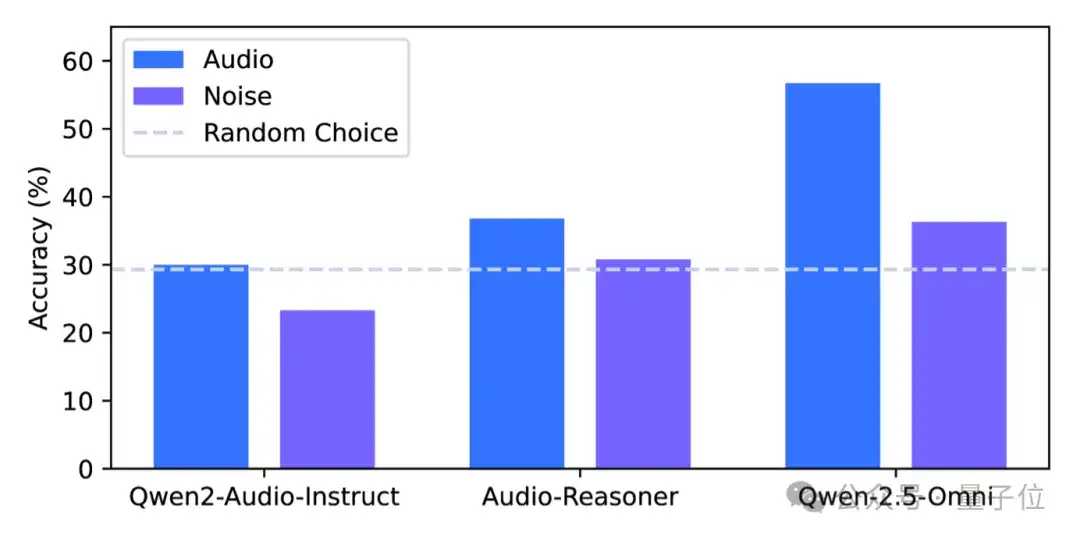
△MMAR基准上的性能比较:使用噪声替换音频作为输入的影响
研究团队还做了一个“灵魂拷问”实验——把输入音频换成噪声。
结果发现,模型性能都大幅下降,证明它们确实在“听”音频,而不是靠文本先验瞎猜。不过,Qwen-2.5-Omni在噪声输入下依然略高于随机猜测 ,暴露出潜在的语言先验偏差问题。
此外,研究人员测试了多种级联模型组合(如音频摘要+LLM推理)。
结果显示,更换更强的音频理解模型或推理模型都能带来性能提升,说明感知能力和推理能力是相辅相成的。
总体来看,当前大多数开源模型在面对MMAR这样的深度音频推理任务时,表现仍然不尽人意。
AI 到底哪里“听不懂”?
为了搞清楚模型失败的原因,研究人员对提供思维链的Audio-Reasoner模型的错误进行了分类,发现主要有以下几类:
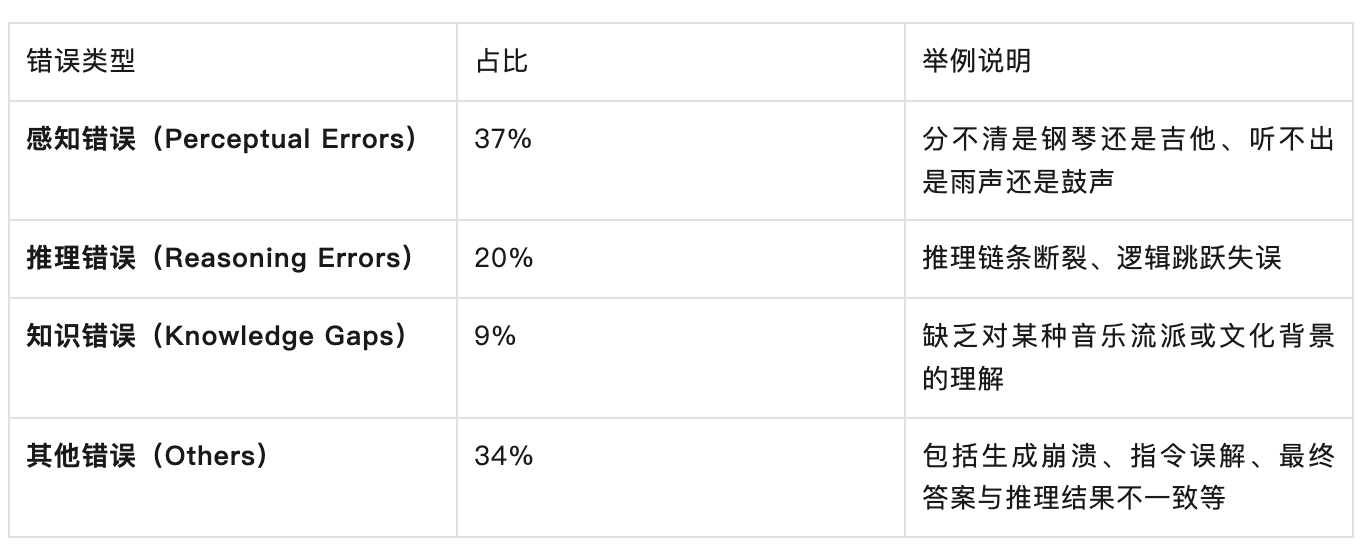
也就是说,现在的 AI 不仅“耳朵不好使”,“脑子也不太灵光”。
总结与展望
通过MMAR的测试可得以下几个关键结论:
在这个开创性项目中,各参与机构发挥了独特的优势和作用。来自香港科技大学和伦敦玛丽皇后大学的音乐科技工作者对专业的音乐题目进行收集和标注;2077AI的研究员提供了数据处理与标注平台衔接的重要保障。此外,整数智能数据工程平台提供了专业的支持,平台的多轮审核机制和协同标注功能为数据质量提供了强有力的保障。
研究人员希望,随着更多研究者加入这一领域,人们在未来会看到真正“听得懂”的AI:不仅能听清你在说什么,还能听出你在想什么。
文章: https://arxiv.org/abs/2505.13032
代码(GitHub):https://github.com/ddlBoJack/MMAR
数据集(HuggingFace):https://huggingface.co/datasets/BoJack/MMAR
文章来自公众号“量子位”,作者“”



