# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

推理模型极致的性能与性价比,这次 MiniMax 都要。
好饭不怕晚,MiniMax 终于把这款金字塔尖的推理模型拿出来了。
在将 MoE 和 Lightning Attention(闪电注意力)的激进架构变革引入基础模型底层,转化为全新的 MiniMax-01 系列模型的 5 个月后,大模型公司 MiniMax 终于更进一步,捧出了酝酿许久的自研文本推理模型 MiniMax-M1,这也是全球首个开源、大规模实现混合注意力的推理模型。
推理模型已成为新的大模型技术浪潮,拿出一款强劲的自研推理模型,是近半年里国内第一阵营的大模型公司保持自己技术身位最直接的目标。
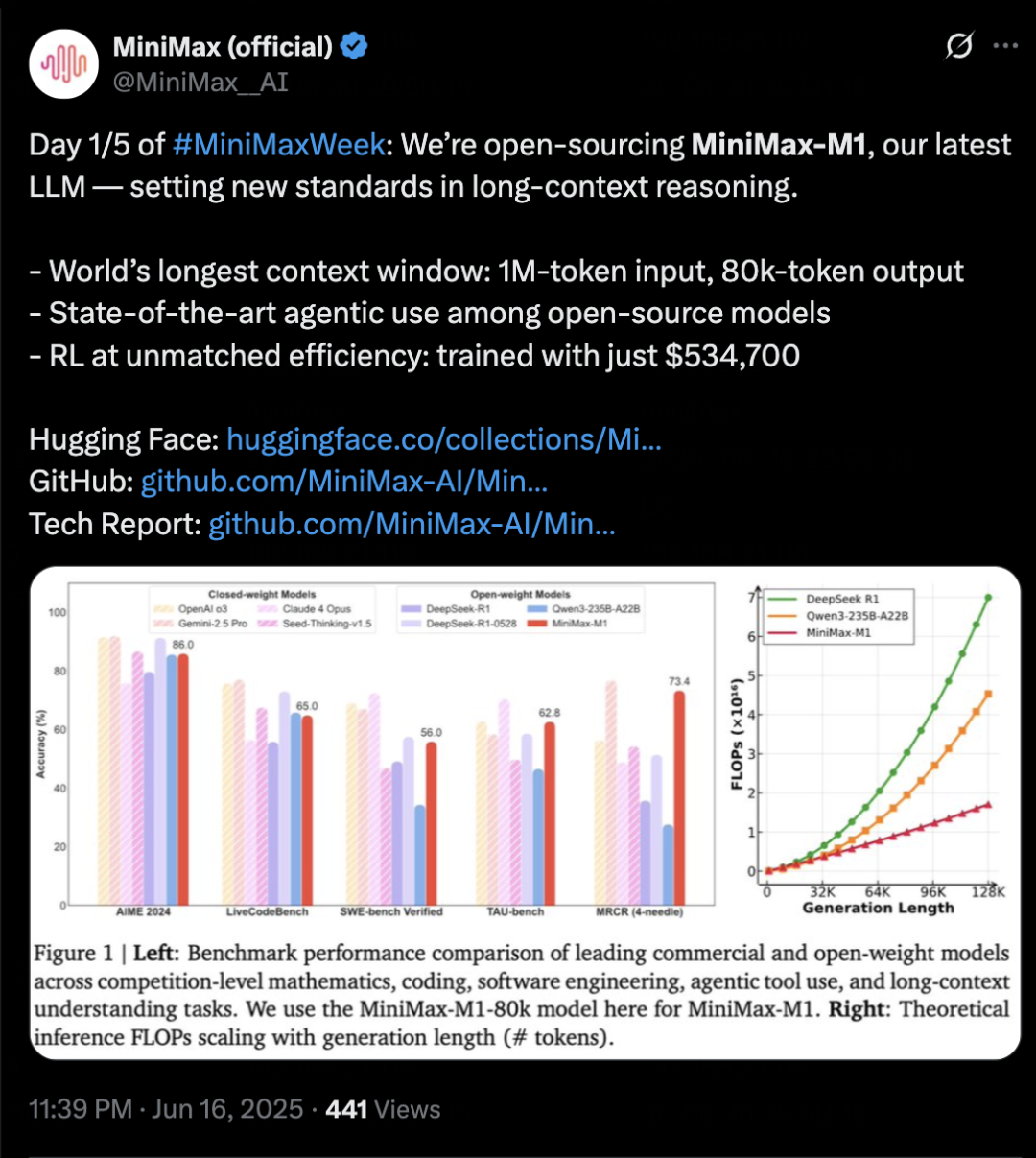
作为推理模型,MiniMax-M1在长上下文理解能力上,是目前包括所有闭源和开源模型在内,能力全球前二的模型,且在训练和推理成本上极高的性价比。
M1 仍然延续着 MoE 架构,而在注意力机制上和强化学习算法上的创新让 M1 鲜明的区别于其他推理模型。模型总参数达到 4560 亿参数,原生支持 100 万 token 的上下文长度输入,以及目前所有模型中最长的 80k token 的输出长度。
在上下文能力的评测基准 OpenAI-MRCR (128k/1M) 以及 LongBench-v2 中,M1 的表现远超包括 DeepSeek-R1-0528 和 Qwen3-235B 在内的所有开源模型,甚至超越 OpenAI o3 和 Claude 4 Opus,仅小幅落后 SOTA 的 Gemini 2.5 Pro。
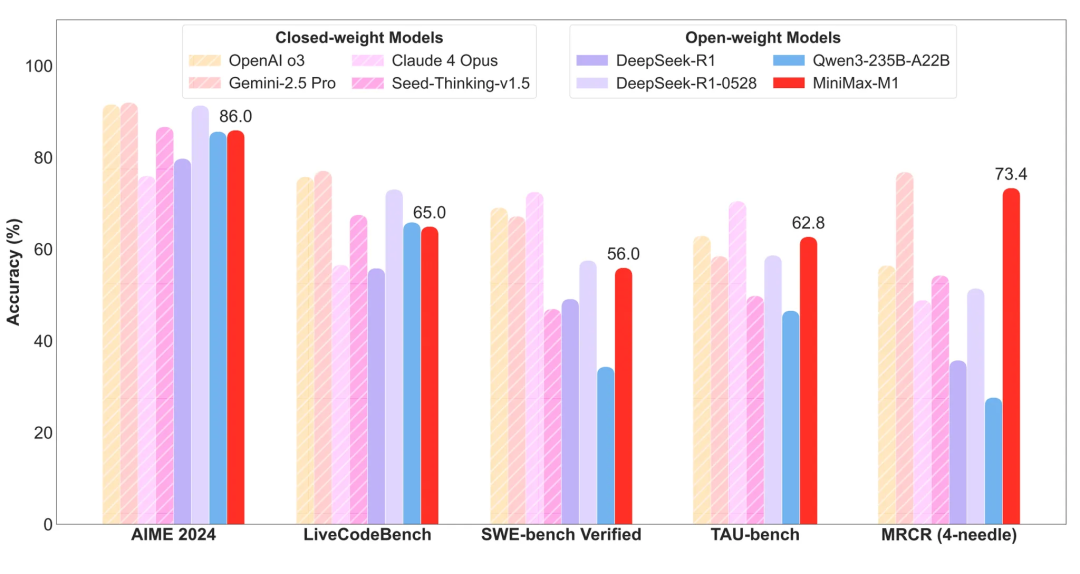
除了在长上下文能力上的强势,M1 所展现出的在智能体工具使用(Agentic Tool Use)维度上的能力上限甚至更加让人期待。从评测基准 TAU-Bench (airline) 中的表现来看,目前 M1 已经是市面上在 Agentic Tool Use 方面能力最强的模型。
技术报告中对于 M1 的概述是,这个新的开源模型已是与 DeepSeek-R1、Qwen3-235B 并列的世界顶尖开源推理模型,这一结论是在参与了业内主流的 17 个评测基准之后得出的。在处理复杂场景时长上下文、智能体工具使用能力上的长板足够亮眼,M1 在更通用的模型性能上也已经跨入顶尖行列。
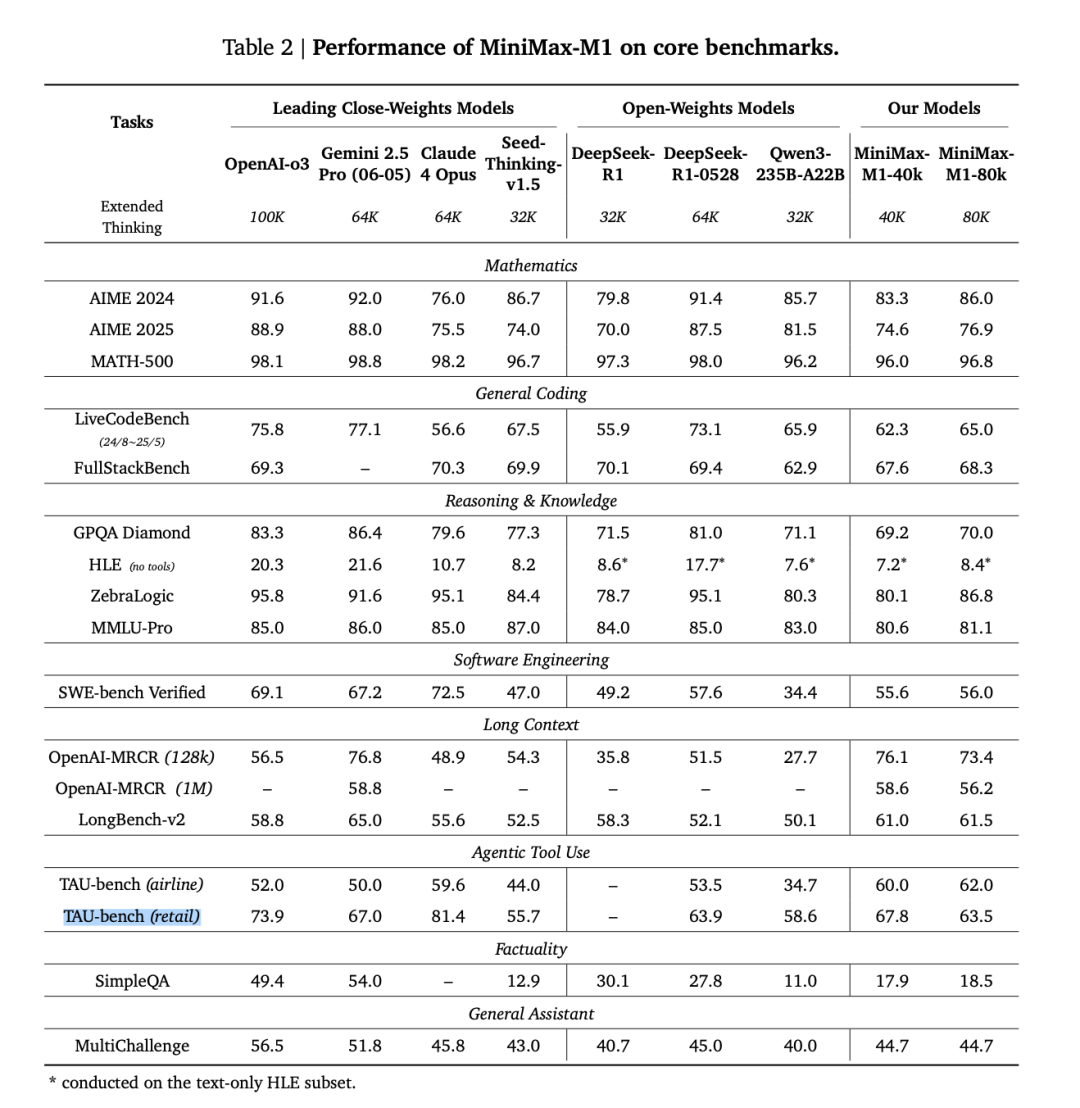
此外需要特意说明的是,M1 系列模型中的两个模型中,MiniMax-M1-40K 模型是 MiniMax-M1-80K 模型在训练时的中间阶段。而在测评基准所呈现的总体表现中,MiniMax-M1-80k 在多数基准上持续优于 MiniMax-M1-40k,这也验证了上下文窗口长度带来了模型整体性能的显著提升,而非仅仅意味着支持更长的输入。
与市面上主流的推理模型相比,M1 在底层架构和算法层上都有所创新。
在底层架构层面,M1 是目前唯一一个用线性注意力机制「大改」传统 Transformer 架构,从而大规模实现混合注意力的 MoE 推理模型;在算法层面,M1 提出了新的强化学习算法 CISPO。更彻底的双线创新提高了 M1 的训练效率,而训练成本的下降也非常可观。
为解放 Transformer 架构中核心的注意力机制 Softmax Attention 在计算资源消耗方面的局限性,M1 系列模型在注意力机制的架构设计方面相比传统架构的推理做了更大胆的尝试——采用混合注意力机制 Lightning Attention——来代替标准 Transformer 中使用的传统 Softmax Attention。
独特的注意力层设计让 M1 在推理时具有显著效率优势,天然有利于强化学习的高效扩展,但走到混合架构大规模强化学习的无人区,MiniMax 显然也会遇到新架构带来的挑战。
比如在混合架构的初步零强化学习(zero-RL)实验中,团队发现传统的 PPO/GRPO 算法会意外的严重损害训练性能。具体来说,与反思行为相关的关键 token——例如表示转折的 however、wait——这些低概率 token 对稳定熵和促进可扩展 RL 至关重要,但却容易在策略更新时被裁剪,难以保证这些 token 的梯度贡献,导致难以促进长 CoT 推理行为。此问题在混合架构模型中尤为突出,阻碍了强化学习的规模扩展。
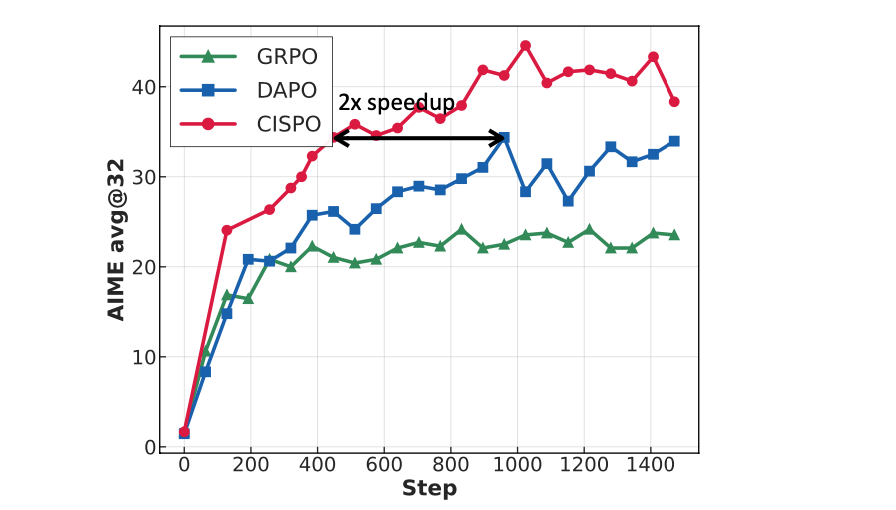
为此,M1 在算法层面提出了新的强化学习算法 CISPO,意在明确避免丢弃任何 token(即使更新幅度大),同时将熵维持在合理范围以确保稳定探索。
在 zero-RL 设置下,MiniMax 团队在数学推理数据集上训练 Qwen2.5-32B-base,对比 CISPO、 字节跳动提出的 DAPO 以及 DeepSeek 提出的 GRPO 算法在 AIME 2024 上的表现。相同步数下 CISPO 显著优于 DAPO 和 GRPO;其训练效率更高,仅需 DAPO 50% 的步数即可达到同等性能。
底层架构上对于线性注意力机制的引入,以及算法层围绕 CISPO 所形成的高效 RL 框架,最终让 M1 的强化学习训练变得十分高效,进而取得了训练成本的大幅下降。
与模型一同发布的技术报告中显示,在生成长度为 10 万 Token 时,M1 的计算量仅为 Deepseek R1 的 25%,而整个 M1 的完整强化学习训练能在 512 张 H800 GPU 上仅用 3 周完成,以目前的 GPU 租赁价格计算,成本仅为 53.47 万美元。
MiniMax 官方也发布了几个 demo,我们可以从中看到 M1 究竟能做到什么。
比如最经典的用贪吃蛇游戏测试 coding 能力的测试玩法,但这次 M1 展示的是用一句自然语言生成一个更复杂的迷宫游戏。
Prompt 是这样的: 创建一个迷宫生成器和寻路可视化工具。随机生成一个迷宫,并逐步可视化 A* 算法的求解过程。使用画布和动画,使其具有视觉吸引力。
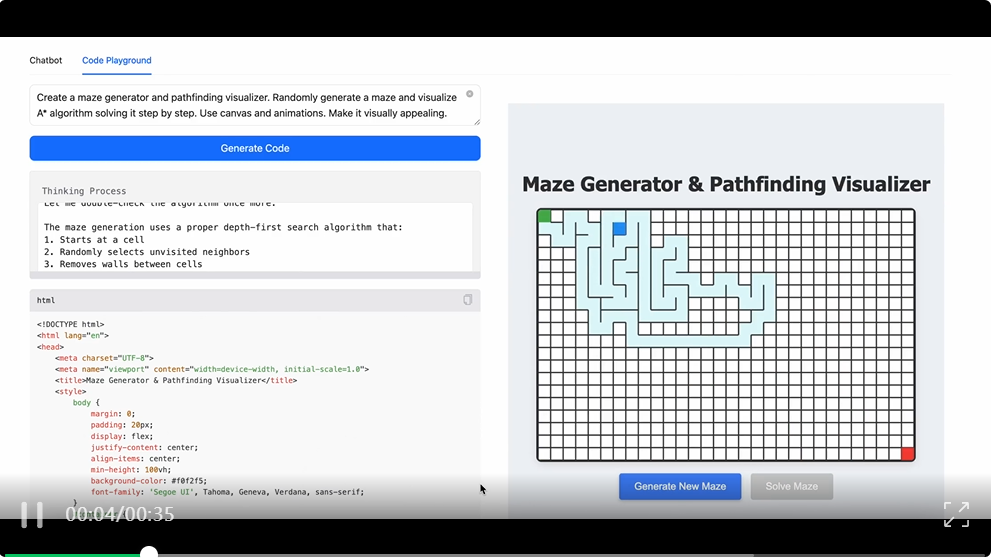
或者让 M1 来帮你从 0 到 1 搭建一个能够测试打字速度的网页:
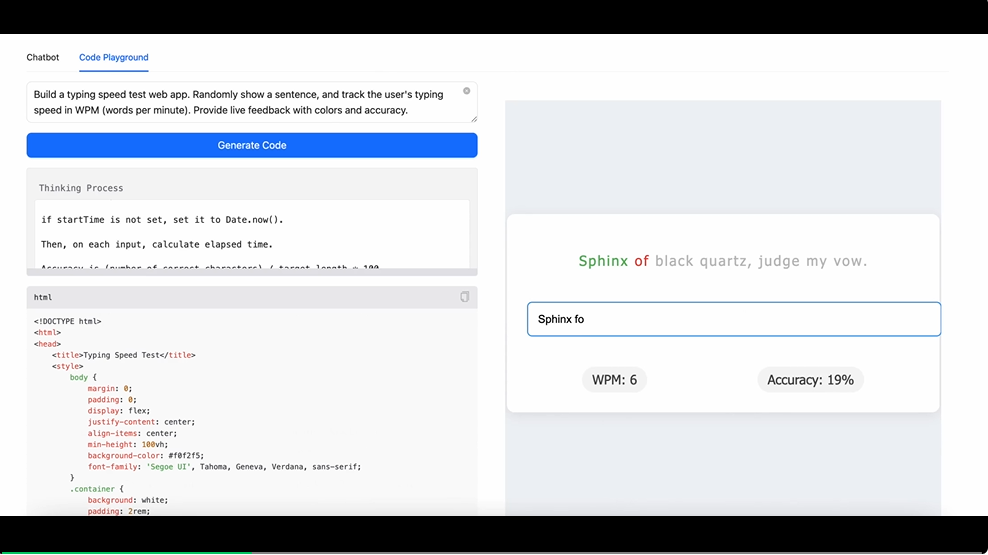
demo 里可以清晰看到,M1 在生成的网页中思路清晰的设置了代表打字速度的 WPM(words per minute)和准确度的 Accuracy 两个指标,并且体贴的让上方文字随着你的输入进程而同步变色。
又或者,用户可以直接让 M1 做一个可拖拽的便签墙。
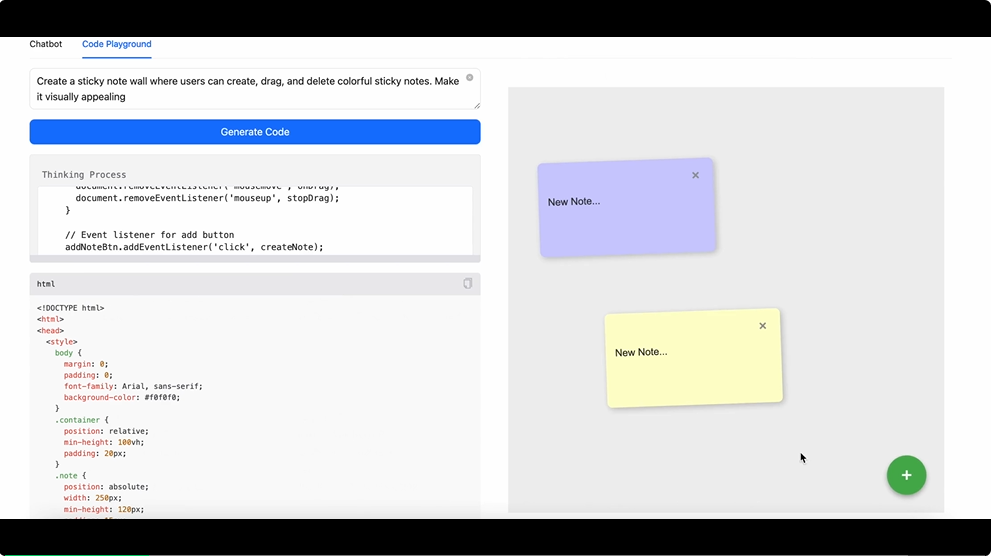
这些 demo 都在指向一些通用 agent 中产品化 feature 的可能性。长上下文理解、智能体这些在模型能力产品化过程中的核心能力,恰好是 M1 模型的强势所在。这符合 MiniMax 最早以产品起势的路线,而这家公司近来在基础模型层面持续的激进探索,也以 M1 的出现为节点,在当下大模型公司们技术突破普遍降速的时候显示出后劲。
M1 的出现,背后是一条 MiniMax 从传统的稠密模型与 Transformer 架构,转向 MoE 与线性注意力机制的草蛇灰线。在 MiniMax 决定引入 MoE 与线性注意力机制的时候,在当时几乎都没有什么可以参考的对象。
Mistral AI 在 2023 年底用开源的模型 Mistral 8✖️7B 击败了当时最优秀的开源模型之一,700 亿参数的 Llama 2。2023 年夏天,MiniMax 已经在准备从稠密模型转向 MoE,投入了当时公司 80% 的算力与研发资源,在 Mistral 8✖️7B 发布的一个月后,上线了国内首个 MoE 大模型 abab 6,并且由于这是个过于新的架构,MiniMax 为 MoE 自研更适配的训练和推理框架。
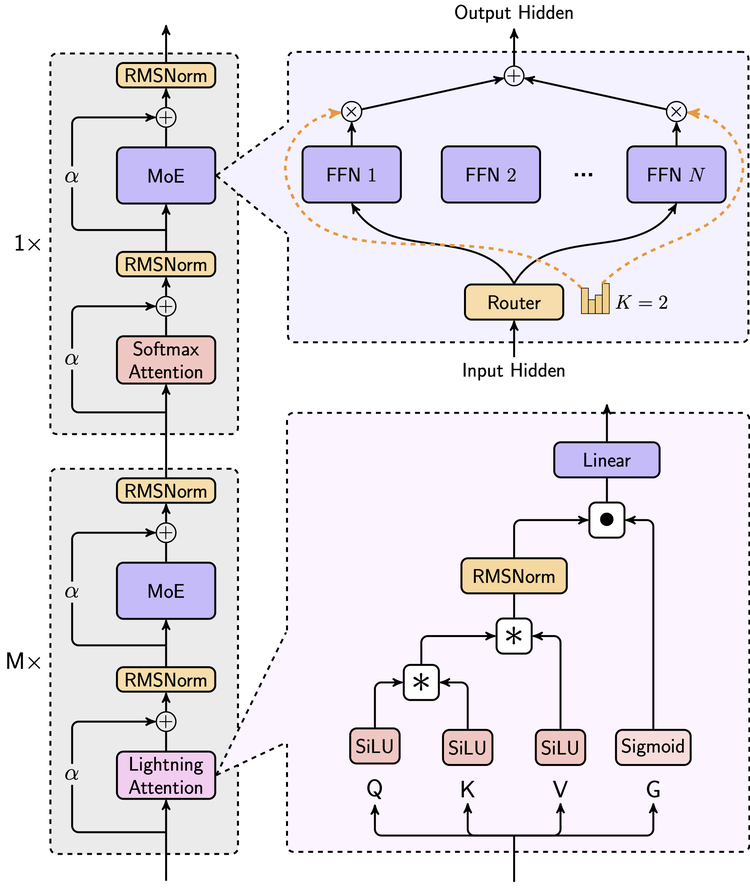
MoE 架构
M1 的混合架构的特征,则开始于今年年初 MiniMax-Text-01 模型里线性注意力(Linear Attention)混合架构的引入。
MiniMax 开始投入 Linear Attention 是从 2024 年 4 月开始的,那时尚没有模型在千亿级别的参数规模层面挑战传统的 Transformer 架构。这使得 MiniMax 需要对分布式训练和推理框架进行彻底的重新设计来适配,使得模型能够在大规模 GPU 集群上高效运行,这才有了今年 1 月的 MiniMax-Text-01,这也是第一个依赖线性注意力机制大规模部署的模型。
可以说,MiniMax-Text-01 是 MiniMax 在线性注意力这件事上,为整个行业从小规模可行的共识,到 Scale up 的可行做了一次验证。而推理模型 M1,本质上又是一次基于 MiniMax-Text-01 的 scale up 和架构创新。
MiniMax 也公开了一部分 M1 基于 MiniMax-Text-01 训练的细节。
团队以 MiniMax-Text-01 为基座,实施 7.5 万亿 token 的定向增强预训练,将 STEM(科学/技术/工程/数学)、编程代码与复杂推理三类核心领域的数据权重提升至总语料 70%。随后通过监督微调阶段注入链式思考(CoT)机制,系统性构建模型的分步推理能力,为强化学习奠定能力基础。
最终这种激进式的创新得到了积极的验证,M1 是目前全球最先抵达 80k 上下文输出的推理模型,同时在长上下文,软件工程和 Agent 工具使用方面体现出了优势。
此前星野和 Talkie 在商业化上的优异表现,让 MiniMax 早早成为一家可以自己独立行走的大模型公司,也让外界赋予了这家公司一个「产品驱动」这样过于笼统的标签。这一定程度上忽视了 MiniMax 在模型层面上相当强悍的研发能力。
值得注意的是,MiniMax 的官方公告透露,M1 系列模型同时也拉开了为期五天的 MiniMaxWeek 的序幕,未来五天,MiniMax 会围绕文本、语音和视觉等多模态模型对外公布更多的技术进展。
与此前 MoE 的 Abab 6 模型刚出现时类似,此次发布的混合注意力机制的 M1 在底层架构层面仍然是一个「非共识」的推理模型,但也正是因为这些屡次探入模型底层架构「非共识」地带所带来的技术创新,一直在印证 MiniMax 终究是一家「模型驱动」的 AI 公司。
而这早该成为一种共识。
*头图来源:视觉中国
文章来自于微信公众号“极客公园”,作者是“甘德”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
