# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今年 4 月,围绕“华为芯片效率是否超越国际主流 AI 芯片和架构”的问题,网上曾引发一场激烈争论。争论的起点源于一条网友评论:“虽然华为芯片单颗比起用英伟达还是有落差,但是组成系统后,效率明显就高了。” 这条评论迅速引来大量围观,其中不乏对其可信度的质疑。
近日,这场争论迎来了一个重要节点:华为团队与老师木所在的硅基流动(Silicon Flow)联合署名的论文《Serving Large Language Models on Huawei CloudMatrix384》已在 arXiv 上公开(论文地址:https://arxiv.org/pdf/2506.12708)。
该报告详细阐述了如何在 CloudMatrix 384 超节点上部署 DeepSeek 大模型,这被认为是业界首次公开非英伟达体系下解决此类技术难题的细节。值得一提的是,华为的超节点设计理念和实现方案在 DeepSeek 需求爆发多年前就已经成熟。即便面对新兴且特殊的负载需求,CloudMatrix 超节点依然展现出良好的支持能力,证明了其底层设计理念和工程实现的前瞻性与技术实力。
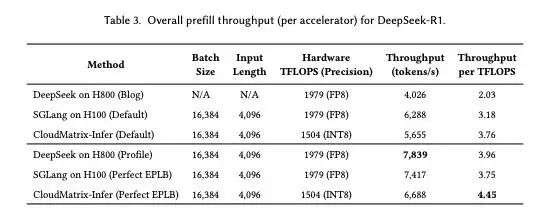
对于大家关注的性能问题,这篇论文也首次公开了华为 CloudMatrix384 在真实大模型部署场景中的性能指标,并与英伟达 H100、H800 平台进行了直接对比。
首先是预填吞吐量(Prefill Throughput),这是高效处理输入提示的关键因素。在预填吞吐量阶段,华为单卡吞吐达到 6688 tokens/s,并拿到全场最佳算力利用率(4.45tok/s/TPFOPS)。
这超过了 H100 上 SGLang 的理想效率(每 TFLOPS 3.75 tokens/s)和 H800 上 DeepSeek 的 Profile(每 TFLOPS 3.96 tokens/s)。
其次是解码吞吐量(Decode Throughput),华为单卡吞吐量达到 1943 tokens/s,计算效率为 1.29 tokens/s/TFLOPS。
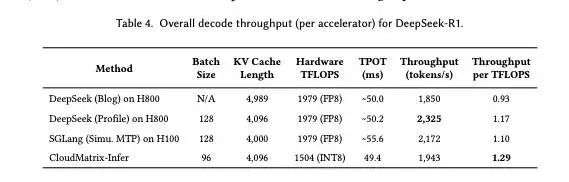
也就是说,在部署 DeepSeek-R1 这类大规模 MoE 模型时,CloudMatrix384 在关键性能指标上全面超越英伟达体系:在预填吞吐量和解码吞吐量上,双双高于 SGLang 在 H100 和 DeepSeek 在 H800 上的公开测试结果。
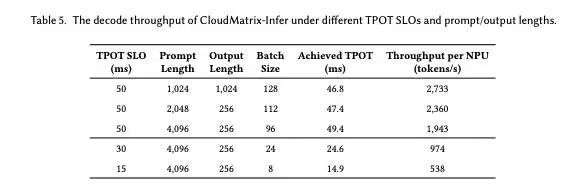
更值得关注的是,在要求更低时延的场景下(例如 TPOT<15ms),CloudMatrix 依然能维持 538 tokens/s 的 decode 吞吐表现,显示出对高并发、低延迟请求的强适应能力。
在推理精度方面,CloudMatrix 上基于昇腾 910C 实现的 INT8 量化版本,在 16 项权威 benchmark 上的准确率表现与 DeepSeek 官方 API 几乎一致,基本做到了“性能提升不以精度为代价”。
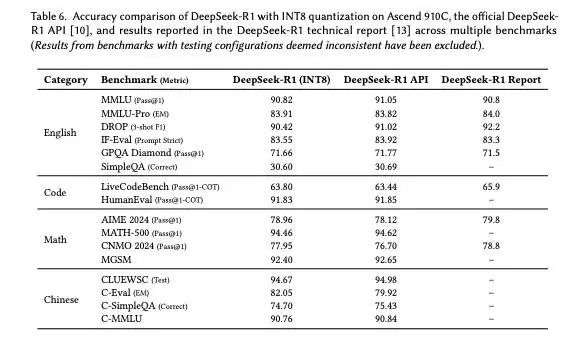
所以,从这些数据来看,CloudMatrix384 不仅在整体性能上接近或超越国际顶级方案,更重要的是,其底层架构设计提供了更高效的资源调度能力,尤其适合处理 MoE 并行度极高、KV Cache 高频访问等挑战性负载,为大模型的规模化部署与商业化落地提供了另一种可能路径。
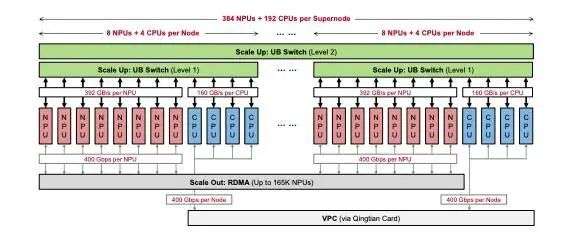
华为云 Matrix384 作为下一代 AI 数据中心架构的首个生产级实现,集成 384 个 Ascend 910C NPU、192 个 Kunpeng CPU,通过超高速低延迟统一总线(UB)网络互联,实现计算、内存和网络资源的动态池化与统一访问。
硬件架构
华为 CloudMatrix384 在网络架构设计上引入了三重通信平面,旨在实现超大规模 AI 集群内外的高效互联与资源协同:
首先,UB 平面作为系统内部的高带宽 Scale-up 通信结构,通过非阻塞的全互联拓扑将 384 个 NPU 与 192 个 CPU 直接连接。每颗昇腾 910C 芯片可提供超过 392GB/s 的单向带宽。
其次,RDMA 平面用于超节点之间及与外部 RDMA 系统的 Scale-out 通信,当前采用 RoCE(RDMA over Converged Ethernet)协议,以兼容标准 RDMA 软件栈。
最后,VPC 平面通过华为自研的擎天网卡将 CloudMatrix384 超节点接入数据中心网络,每节点可提供高达 400Gbps 的单向带宽,采用标准的以太网和 IP 协议,支持可选的 UBoE(UB over Ethernet)增强。
虽然 CloudMatrix 的长期目标是将 RDMA 与 VPC 平面合并为一个统一架构,但目前 CloudMatrix384 仍将两者分离,以保证对现有数据中心基础设施的兼容性。
在论文中,华为表示该架构的核心是超高速、低延迟的统一总线(UB)网络,它促进了高效的系统级数据移动和协调。据悉,这也是 UB 统一总线架构首次揭秘。
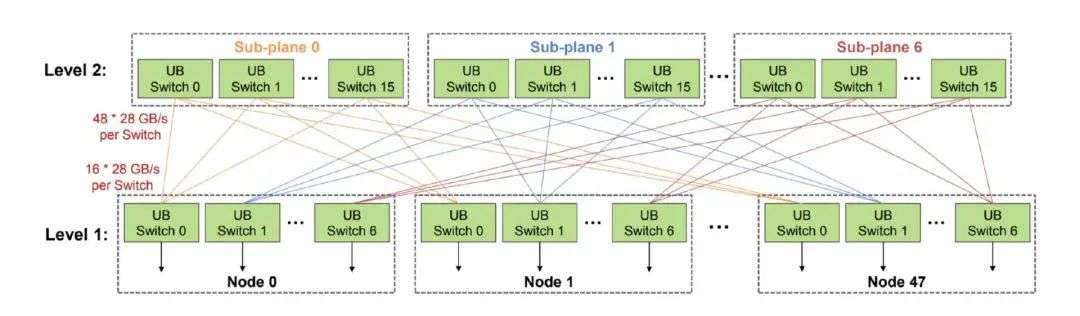
CloudMatrix384 超节点共覆盖 16 个机柜,其中包括 12 个计算机柜(部署了 48 台 Ascend 910C 节点,合计 384 个 NPU)以及 4 个通信机柜。通信机柜中部署了第二级(L2)UB 交换芯片,负责将整个超节点内的所有节点互联起来。
UB 网络拓扑由两级交换结构构成:第一级(L1)UB 交换芯片部署在每个 Ascend 910C 节点内部;第二级(L2)UB 交换芯片部署于机柜间的交换设备中,形成整个超节点范围内的互联网络。该拓扑结构设计为无阻塞(non-blocking),在 L2 层不存在带宽过订阅问题。
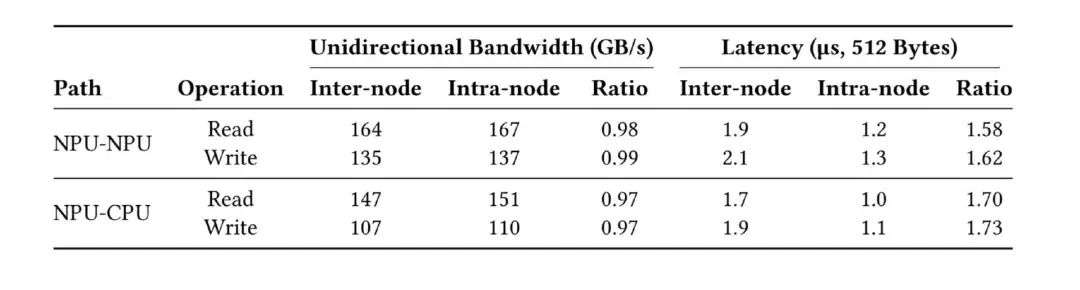
数据显示,CloudMatrix384 的 跨节点带宽已接近芯片内部带宽水平,并且单跳延迟更是达到了接近 1 微秒的极低水平。
基于这一互连基础,CloudMatrix 提供了四项基本能力,共同定义了 AI 原生基础设施的新范式:UB 互连支持 NPU 之间直接、高吞吐量的点对点通信,使得张量并行(TP)和数据并行(EP)组能够跨节点边界扩展,消除节点间瓶颈,实现大模型在超节点内的高效分布式部署;CloudMatrix 将 CPU、NPU 和内存解耦为独立池化的资源,实现细粒度、工作负载驱动的组合;高带宽 UB 网络在单一可扩展基础设施内同时支持 AI 和数据密集型应用;CloudMatrix 将集群中 CPU 附带的 DRAM 聚合为共享的高性能内存池,可通过 UB 访问。
软件栈
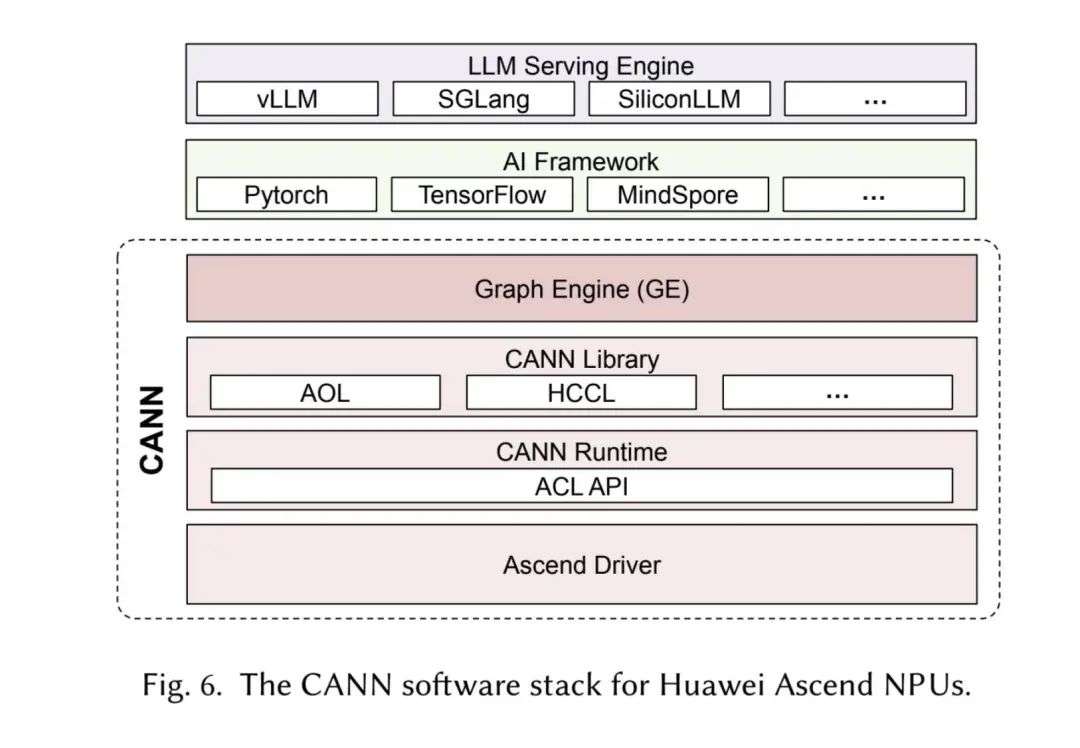
华为为 Ascend NPU 开发了全面的软件生态系统,称为神经网络计算架构(CANN)。
CANN 作为中间软件层,能够实现高级 AI 框架(如 PyTorch、TensorFlow)与 Ascend NPU 底层硬件接口的高效集成。它通过将这些框架生成的抽象计算图转换为经过优化的、可在硬件上执行的指令,简化了开发人员与 Ascend 硬件的交互,促进了软硬件协同设计,并致力于在 Ascend 架构上实现应用性能的最大化。
CANN 软件栈由三个主要层组成:驱动层、运行时层和库层,其架构类似于 NVIDIA 的 CUDA 生态系统。
另外,为了支持 CloudMatrix384 在云环境中的部署,华为云提供了一套复杂的基础设施软件,包括 MatrixResource、MatrixLink、MatrixCompute 和 MatrixContainer,旨在抽象硬件复杂性并通过标准云 API 实现无缝资源编排。
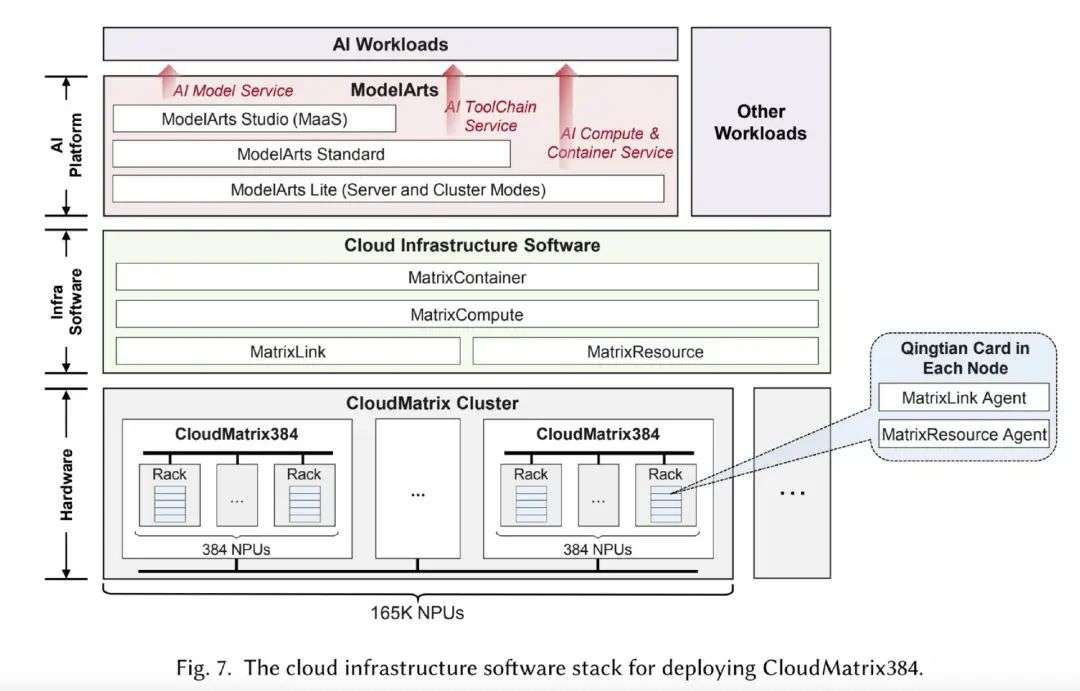
ModelArts 位于基础设施栈的顶部,提供端到端的 AI 平台服务,包括 ModelArts Lite(用于通过裸机和容器化环境直接访问 Ascend 硬件)、ModelArts Standard(支持完整的 AI 开发和 MLOps 管道)以及 ModelArts Studio(提供模型即服务(MaaS)功能,用于 LLM 和其他模型的快速部署和定制)。
整体来看,这一软件栈屏蔽了底层基础设施的复杂性,同时保留了 CloudMatrix384 的性能优势,使开发者能够高效构建并部署大规模 AI 应用。
适配 DeepSeek
为了高效运行 DeepSeek-R1 这样的大参数量、MoE 架构和长上下文模型,华为提出了 CloudMatrix-Infer 推理优化方案,从架构到算子实现全面对昇腾硬件做了适配和增强。

CloudMatrix-Infer 采用 PDC 解耦架构,将推理流程拆分为 Prefill、Decode 和 Caching 三个子系统,分别负责长输入处理、自回归生成和上下文 / 模型缓存管理。NPU 通过 UB 总线直连共享 DRAM 池,实现 KV 缓存和模型权重的高效分布式访问,彻底消除了传统架构中的缓存访问瓶颈。
在并行策略上,DeepSeek-R1 的 320 个 MoE 专家被一一映射到 160 个 Ascend 910C NPU(320 个芯片) 上,实现大规模专家并行(LEP),通信通过 UB 高速网络完成,MoE 延迟不再是性能短板。
推理执行方面,引入原生 Ascend 算子和微批流水线,使计算与通信充分重叠;此外,通过自研 INT8 量化方案(包括自适应尺度、离群值抑制、高效 GEMM、剪枝和误差补偿等技术),在不依赖 FP8 的前提下显著提升性能与能效。
这一整套优化,使 CloudMatrix-Infer 成为大模型推理的高效基座(更具体的可以参考论文原文)。
这篇论文在业界引发了一些讨论,华为团队的作者之一也在知乎进行了详细回应。
他们表示,这篇论文中他们毫无保留地将 Huawei CloudMatrix 全栈的技术体系呈现给大家,一方面意在帮助业界全方位了解我们国产昇腾 NPU,另一方面也希望为国内技术生态建立起使用国产 NPU 战胜 NV GPU 的信心。

另外也有匿名网友表示,基于公开数据测算,CloudMatrix 在百万 token 推理成本上已与主流英伟达 GPU 方案相当。
结合网友们对华为在算力领域“掰手腕”甚至“超越”英伟达的讨论,这篇论文的公开正是对这份争议的有力回应。它完整展现了基于国产芯片、面向未来 AI 负载的全栈技术方案,同时为业界带来了宝贵的第一手官方技术资料。
参考链接:
https://arxiv.org/pdf/2506.12708
https://www.zhihu.com/question/1918276517865157261
文章来自于微信公众号“InfoQ”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
