# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Key Points
昨天(6月17日),豆包上线了一个叫AI播客的功能,用户只需上传文档或者输入文章的网页链接,即可一键生成一段由AI双人对话构成的播客类音频。与去年9月Google在NotebookLM中上线的AI播客中主播生硬的念稿感相比,豆包播客要自然得多,而且,连晦涩的英文技术论文它也能将其变成播客。
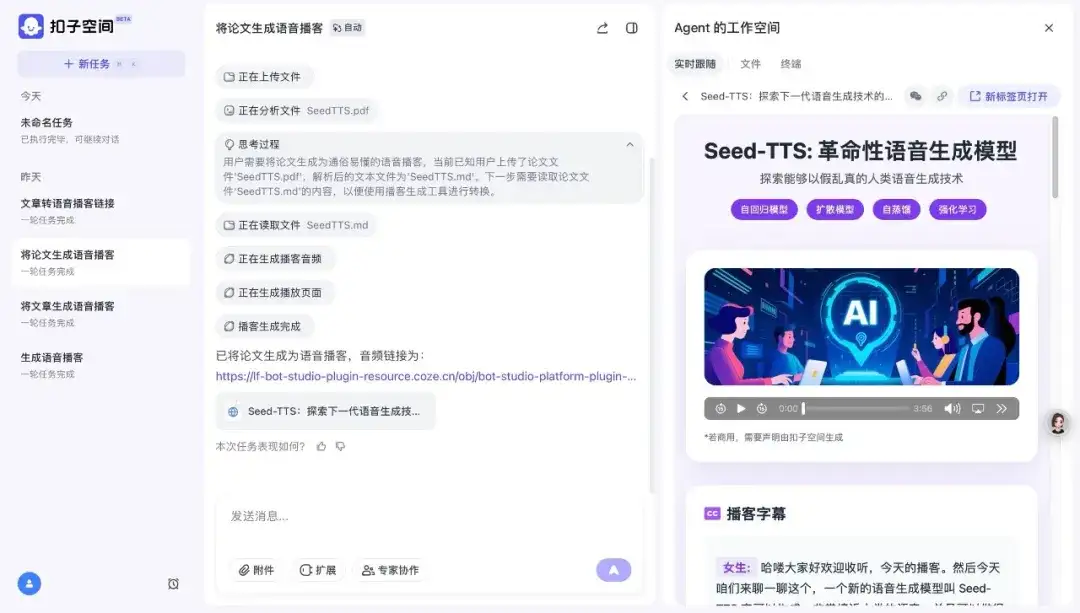
例如,将字节跳动Seed-TTS团队一篇18页的英文技术论文发送给豆包或扣子,即可收获一段两人对谈讲解论文的中文播客,时长3分56秒。开头的前奏音乐也由播客模型自动生成,两位AI主播对话的过程中,男女声的音色与音调都比较自然,还会模仿人说「然后」「这个」等连接词,自然程度堪比OpenAI去年5月发布GPT-4o模型时展示的对话能力。
内容表达方面,这段AI播客并非直接逐字朗读原文,而是总结内容,还会表达观点、引导对话。比如,其中一位AI主播介绍Seed-TTS(Text to Speech)模型「可生成与人类声音几乎无法区分的语音」时,另一位AI主播给出了「听上去很厉害,但我猜这还不是全部」的回应。
传统的播客节目制作环节复杂。主播需要先做案头研究,制定内容框架,部分主播还会提前写好逐字稿再录制音频,录制结束后再进行人工剪辑。相比之下,用AI生成播客的步骤要简单得多——将资料「投喂」给AI,即可生成一段播客。
播客制作技术的改变可能会让这种内容变得更流行,不过不单是因为制作变简单了。
Seed-TTS:革命性语音生成模型,新皮层NewNewThing,3分钟图说:豆包生成的AI播客。聊天,比陈述更有市场?商业数据平台Statista的数据显示,2024年中文播客的听众规模预计为1.34亿,相当于每100个互联网用户中有12人收听播客。这个比例不算高,因为它意味着八九成的人目前依然在通过图文、视频而非音频获得信息。不过,播客不同于传统音频产品,它不是一个人的陈述,而是至少两个人的聊天。
有例子表明,相较于单向输出,用户似乎更喜欢有互动感的内容。2023年,Google推出AI原生应用NotebookLM,起初,它只是一款普通的AI助手,可以根据用户上传的内容生成摘要、注解与用户想要的答案。真正让NotebookLM获得关注的是2024年9月上线的AI播客功能——音频概述(Audio Overviews)。这项功能支持上传PDF、Google文档、YouTube视频或音频文件等内容。上传文件后,NotebookLM就会把它们变成一段两人对谈的播客。根据Similarweb的监测数据,音频概述上线后的一个月,NotebookLM的访问量增长了200%以上,达到3150万次。
随后,2024年11月,音频生成公司ElevenLabs推出了类似的AI播客功能GenFM,支持32种语言;一个月后,2024年12月,传统音频平台Spotify上线了年度回顾(Wrapped)功能,首次引入AI生成的播客版本,不过这一功能的基座技术不是Spotify研发的,而是来自Google的NotebookLM。今年1月,国内的理想同学App也推出了「听播客」功能,AI音频的音色有5种可选,不过新闻来源均为虎嗅,用户暂时还无法自主上传内容以生成播客。豆包在今年5月加入了这场「潮流之战」。
单从技术看,豆包实现了业界最好的音色自然度,不过在将长视频变成播客时,豆包生成的音频内容相对简略。而且,豆包PC端、App端和扣子空间还未上线下载AI音频的功能。也就是说,豆包生成的播客目前只能在豆包应用内收听,用户无法把节目下载后再发布到其他平台。对于一个想做社区而非只做生产工具的应用来说,AI播客是个机会。
NotebookLM也曾限制用户向其他平台分享生成的笔记和播客,不过这个月初,NotebookLM修改了规则,开始允许用户通过公开链接将自己创建的东西——无论笔记还是播客——分享出去,以增强产品的传播力。豆包押注音频,AI播客只是其中之一为了实现把没有角色的文章变成由两位主播对话的AI播客,字节推出了专门的「豆包·语音播客模型」。在模型介绍中,字节称该模型是豆包大模型语音语言技术的「重大场景化升级成果」。
豆包对语音能力的重视超过国内其他ChatBot。去年6月,字节大模型团队发布过一个语音生成基座模型——Seed-TTS(Text-to-Speech)。研究团队称,和传统的单一任务模型不同,「我们希望它(Seed-TTS)能干任何任务、发出任何声音,且同时允许我们进行很多个维度的操控,比如方言、真人口癖,甚至吞字这类语音上的瑕疵。」
今年1月,字节推出端到端语音大模型,并基于该模型在豆包App中推出实时语音通话功能,用户可以直接给豆包发语音或者打电话给它。这一功能契合了下沉市场用户与AI交互的方式。有用户对「新皮层」称,她的父母会像发微信语音那样给豆包发语音询问生活中的问题。另有用户称,他会在逛博物馆时直接拨通豆包的电话,让豆包实时讲解馆藏文物。跟豆包语音对话的短视频内容,也是抖音平台上热度最高的AI类内容之一。多位业内人士对「新皮层」称,语音功能提升了豆包在年轻用户中的渗透率。

推出端到端语音大模型之前,豆包的语音通话功能采用的是ASR+LLM+TTS的方案:用户输入的语音先是通过ASR(自动语音识别)被转写为文本,再通过LLM(大语言模型)生成对话文本,最后通过TTS(文生音频)转为语音输出。今年1月上线的端到端语音大模型则将上述环节放在同一个模型中解决,由此降低了交互延迟,同时提升了对AI声音音色和情绪的把控。目前,国内多个语音生成产品仍然采用ASR+LLM+TTS方案。
6月中旬的火山引擎大会AI应用专场论坛上,字节跳动语音产研负责人叶顺平称,字节的语音技术涵盖了音频生成与创作、音频理解与生成、音乐理解与生成三大能力,可在语音助手、智能客服、在线教育、虚拟陪伴、有声内容生产等场景发挥价值,日均语音处理量达到约150亿次,已应用于超30个行业。
推出AI播客功能前,字节跳动还将其AI语音能力加载到了其他场景上。比如,邀请演播圈艺术家,以他们的真实人声为基础,使用豆包语音模型制作有声书,然后在番茄小说App内上架,方便习惯通过听的方式阅读的用户。
「语音不完全是工具,而是人类最直接的交互形式。」豆包大模型Seed-TTS团队在去年6月的内部访谈中称。人与人之间的情感连接更多依靠语音。想要迈向真正的AI,语音的自然度是关键一环,要让AI真的像人类的助手、伙伴一样,语音带来的情感连接必不可少——比如《钢铁侠》系列电影中的贾维斯。
除了小说电子书、角色设计、视频翻译、虚拟角色、播音、演员表达等关键词,那次访谈中还提到了如何让口吃、发不出声音的人也可以借助语音技术表达。
文章来自公众号“新皮层NewNewThing”,作者“陆彦君”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
