# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让产品团队共享设计语言,以构建可用、智能和安全的Gen AI体验
生成式人工智能(GenAI)“基于意图生成结果”,为人机交互提供了新的范式。GenAI的输出是概率性的,在制定GenAI设计原则和设计模式时,充分理解其变异性、记忆、错误、幻觉,以及恶意使用问题是非常必要的——正如IBM所指出那样。
此外,任何AI产品都是分层的,LLM只是其中之一,记忆、编排、工具扩展、UX和agent工作流才是真正的魔力所在!
本文是作者对GenAI设计模式演变史的回顾和总结。这些设计模式为产品经理、数据科学家和交互设计师提供了通用语言,可以弥合用户需求、技术能力和产品开发流程之间的差距,帮助产品团队更好打造以人为本的、值得信赖且安全的产品。
21个GenAI UX模式一览:
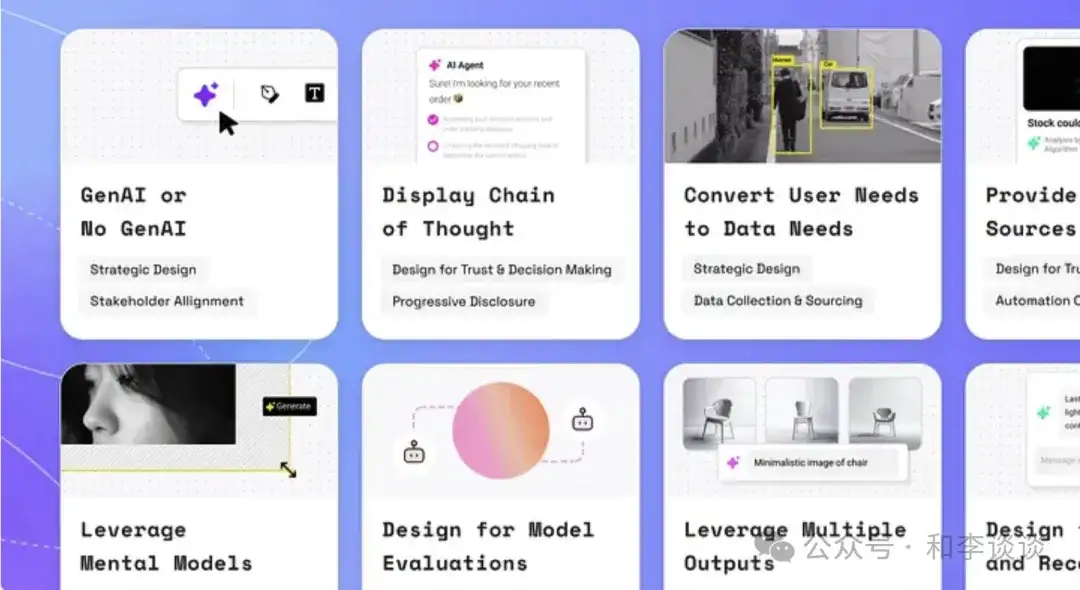
1、GenAI vs 非GenAI
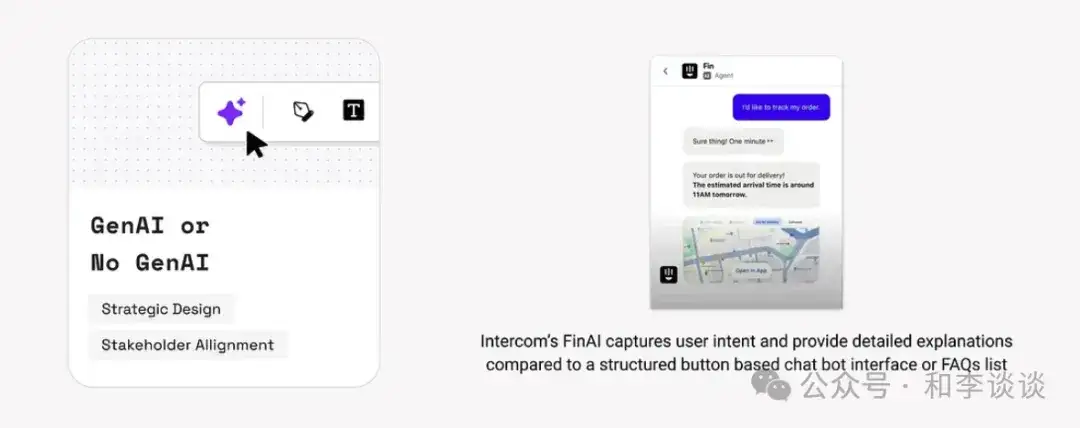
2、用户需求转换为数据需求
3、增强 vs 自动化
4、定义自定化水平
5、渐进AI采用策略
6、利用心智模式
7、传达产品限制
8、展示思考链(CoT)
9、多个输出结果
10、提供数据来源
11、传达模型信心
12、为记忆和回溯而设计
13、提供上下文输入参数
14、coPilot、共同编辑或部分自动化
15、让自动化能被用户控制
16、用户输入错误状态的设计
17、AI系统错误状态设计
18、捕捉用户反馈设计
19、模型评估设计
20、AI安全护栏设计
21、数据隐私和控制的传达
评估 GenAI 是否改善用户体验或增加了复杂性。通常,基于启发式 (IF/Else) 的AI解决方案更易于构建和维护。
(1)评估AI系统解决方案是否干扰用户预期——通过增强人类的努力,或完全替代人力操作(参见模式3)。
(2)评估AI系统解决方案是否干扰用户预期(参考模式 6)。

本模式可确保GenAI的起点是用户意图、其数据模型能达成用户意图。
GenAI系统的优劣取决于其训练数据。但实际使用中,用户并不是以技术性结构化的方式表述需求,而是在表达其使用AI产品的目标、挫折和行为。如果团队无法将用户需求转化为结构化的、模型可用的输入,那么系统或产品就可能给出错误结果、从而导致用户流失。
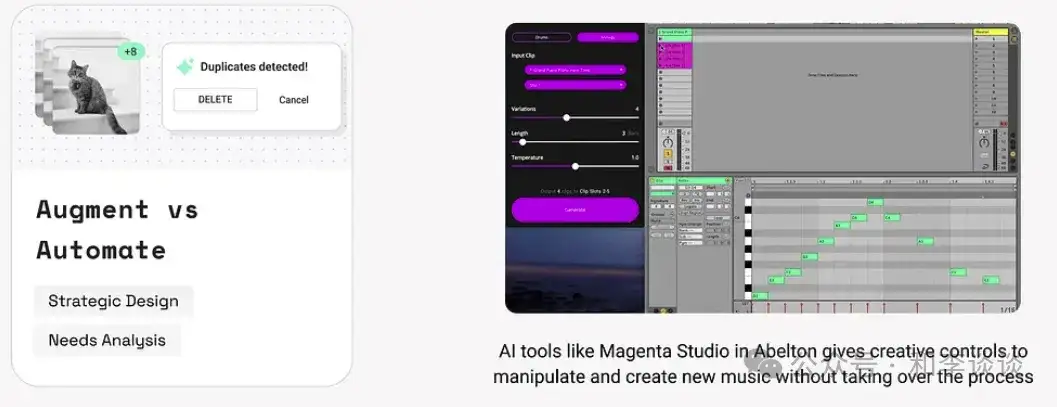
GenAI 应用开发的关键决策是,做AI增强还是完全自动化。此模式可使技术与用户意图、控制偏好保持一致。
自动化:最适合用户倾向于委派的任务,尤其是繁琐、耗时和不安全的场景。例如,Intercom FinAI 自动将冗长的电子邮件线索汇总为内部笔记,从而节省重复性、低价值任务的时间。
AI增强:可提升效率、创造力和控制力,从而增强用户想要持续参与的任务。例如Abelton 的Magenta Studio提供了创造性控制,方便用户操控和创作新音乐。
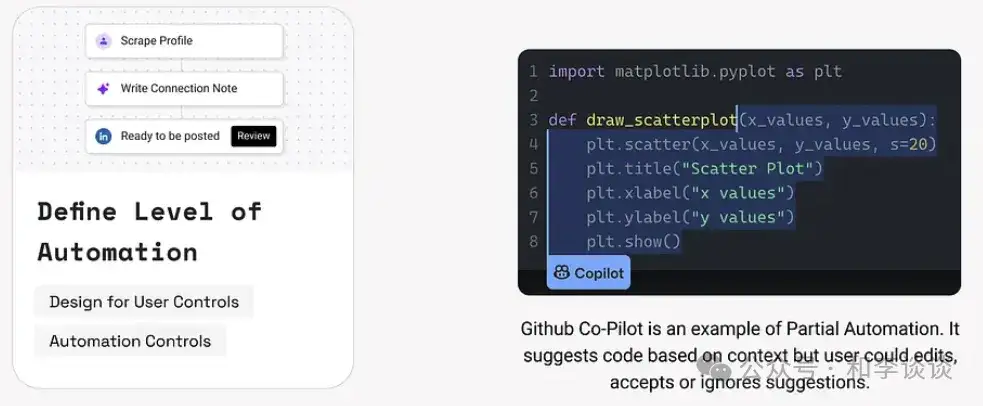
在AI系统中,自动化水平指的是AI系统掌握了多少的控制权。这种战略性的用户体验模式下,需要根据用户的痛点、情境和对产品的期望来决定其自动化水平。
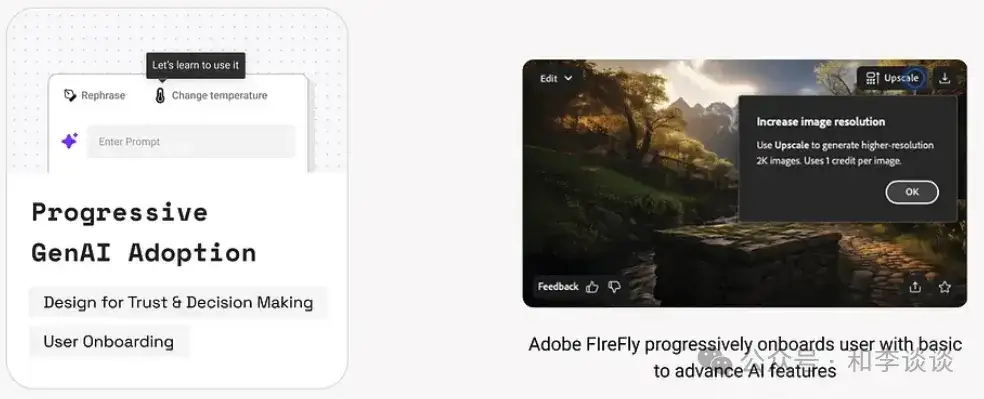
用户在首次接触基于新技术的产品时,常常想要知道这个产品能做什么不能做什么,是如何工作的、应该如何与其交互。
本模式提供了多维策略,以帮助用户更好使用AI产品或功能、减少错误,确保产品与用户准备情况相匹配、能为用户提供明智且以人为本的用户体验。
这种模式是其他模式的集大成者。
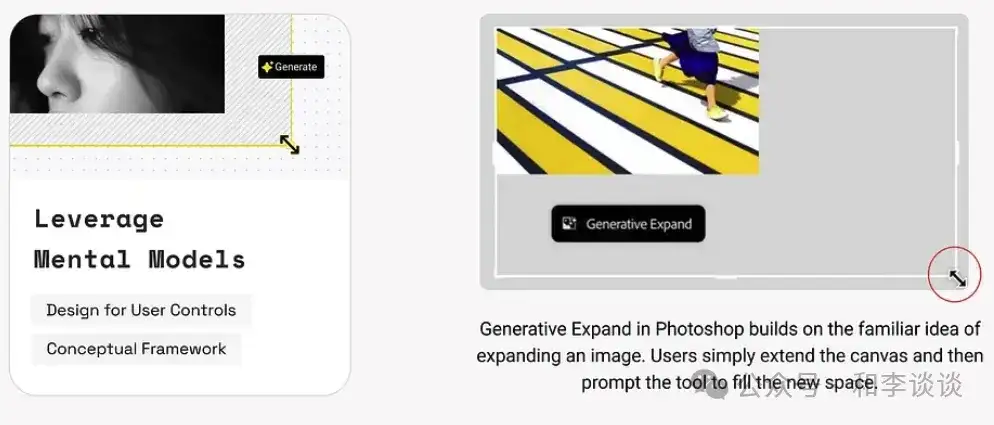
心智模型帮助用户预测网页、应用程序或其他类型的产品的系统运行机制,并影响其与系统界面的交互方式。当产品与用户现有心智模型相符时,用户会感觉直观且易于上手。当两者发生冲突时,可能会导致用户沮丧、困惑甚至放弃。(关于心智模式,可参阅:https://www.nngroup.com/articles/mental-models/)
例如:
通过提问来构建基于已有心智模型的AI系统
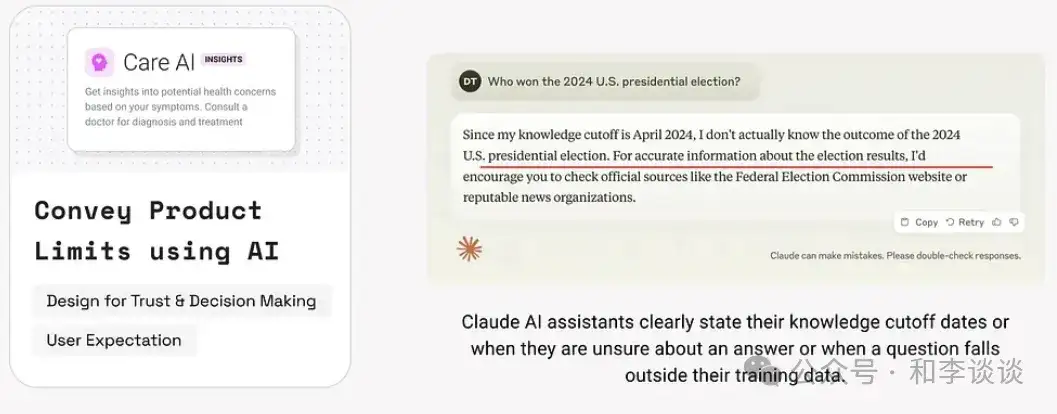
本模式要求清楚传达出AI系统能做什么不能做什么,展示大模型的知识边界、能力和局限性。
这有助于建立用户信任,设定恰当的期望、防止误用,并在模型出现故障或异常行为时减少挫败感。
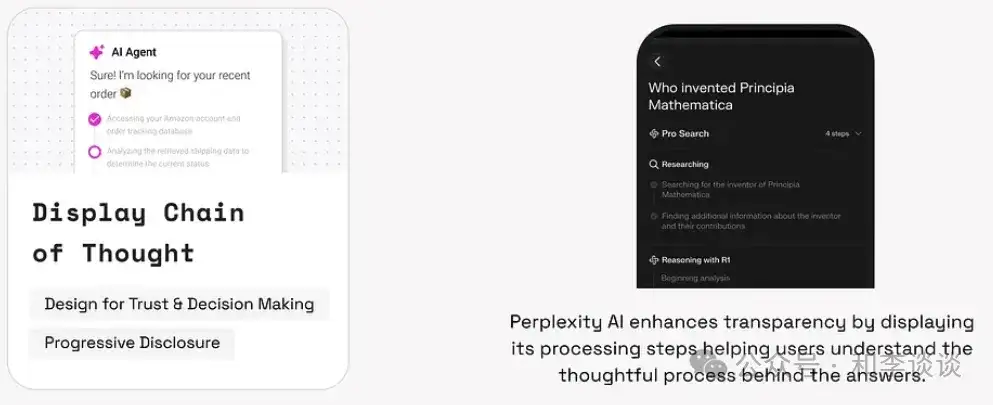
AI系统中,思考链提示技术(CoT) 通过像人那样地结构化、循序渐进的思考过程,来增强模型解决复杂问题的能力。
COT显示是通过展示“AI是如何得出结论”这个过程来提高透明度的一种体验模式,它可以增强用户信任、增强可解释性并为用户提供反馈空间——尤其是在高风险或高模糊性的场景下。
例1,Perplexity显示处理步骤来提高透明度,帮助用户理解生成答案背后的详细思考过程。
例2,Khanmigo(译者注:这是一款AI教育辅导产品)通过模仿人类的推理和学习方式,指导学生一步一步地解决问题。
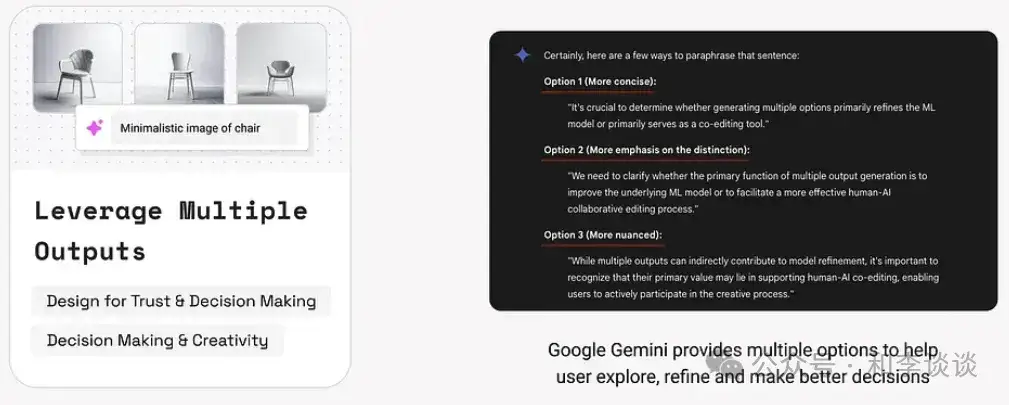
GenAI 凭借其概率特性,能够对同一输入生成多个不同的响应。本模式通过依次呈现多个结果来体现这种可变性。多样化的选项有助于用户创造性地探索、比较、改进或作出更符合其意图的决策。例如, Google Gemini就提供了多个选项,来帮助用户探索、改进并作出更明智的决策。
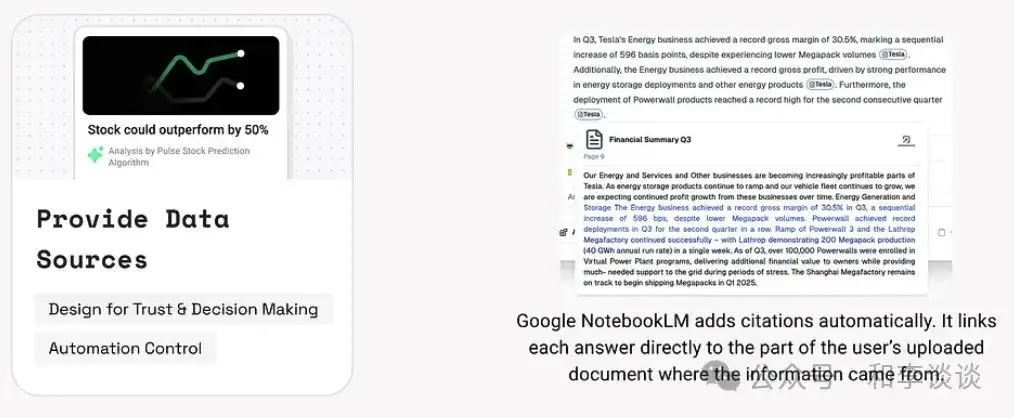
在 GenAI 应用程序中清晰地阐明数据源对于透明度、可信度和用户信任至关重要。清晰地表明 AI 的知识来源有助于用户评估响应的可靠性并避免错误信息。
这在医疗保健、金融或法律指导等高风险事实领域尤其重要,因为决策必须要基于经过验证的数据。
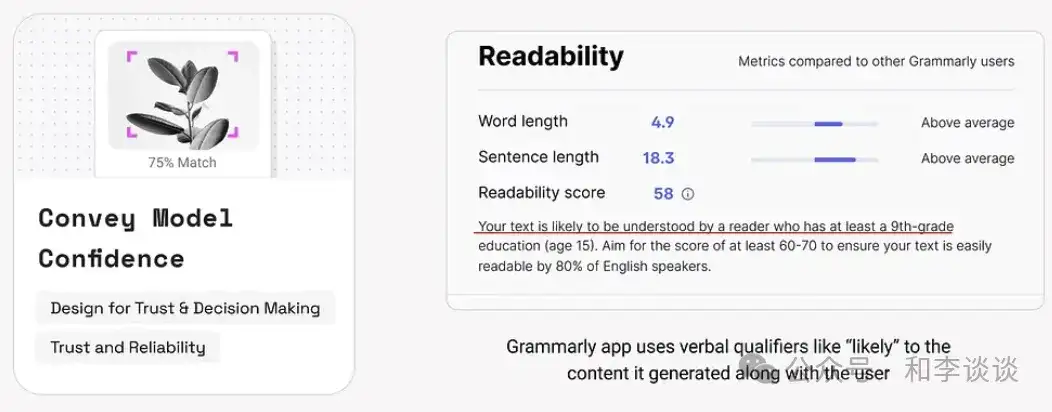
AI 生成的结果具有概率性,不同结果的准确性可能存在差异。显示信心水平分数能传递出模型对其输出结果的确定性高低,从而有助于用户对结果的可靠性进行评估、作出更明智的决策。

记忆和回溯是帮助AI产品存储和重复使用历史交互信息的重要概念和设计模式,例如用户偏好、反馈、目标和任务历史等信息可提高系统的连续性和情境感知能力。
记忆访问的信息可能是短暂的(仅限单次对话可用)或持久的(在多个对话记录中可用),并且可能还会包括对话上下文、行为信号或明确的输入信息。
1.定义用户上下文并选择记忆类型。
根据用例选择记忆类型(如:短暂记忆、持久记忆或两者兼有)。购物助理可能会实时跟踪而无需为后续会话保留数据,而个人助理则需要长期记忆来实现个性化。
2.在用户交互中智能地使用记忆
为 LLM 构建基础提示,以便根据上下文回忆和传达信息(例如,“上次你喜欢更轻松的语气。我应该继续使用这种语气吗?”)。
3.传达透明度并提供控制功能
清晰地传达正在保存的内容,并允许用户查看、编辑或删除已存储的记忆。使“删除记忆”操作易于访问。例如,ChatGPT 在其平台上提供了广泛的控制功能,用户可随时查看、更新或删除记忆。
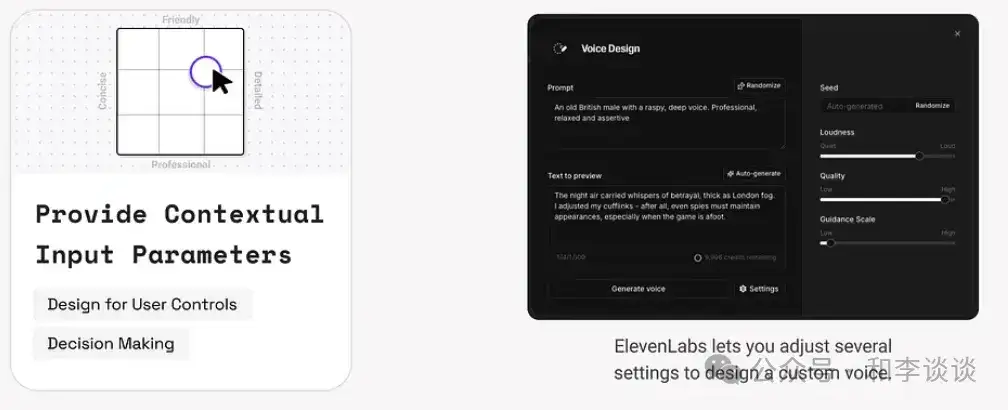
情境化的输入参数可以简化用户交互、提升用户体验,帮助用户更快地实现目标。GenAI 可以利用用户特定的数据、偏好数据、交互历史甚至其他相似用户的数据,提供定制的输入方式或功能来更好地满足用户意图和决策需要。
例如,Perplexity会根据你的当前查询线索智能提供后续查询建议。
3.交互式推荐UI 小组件:根据系统预测定制化地提供toast、滑块或复选框等输入组件,以增强用户输入体验。例如,ElevenLabs显示预设或默认值等方式帮助用户快速微调语音生成设置。
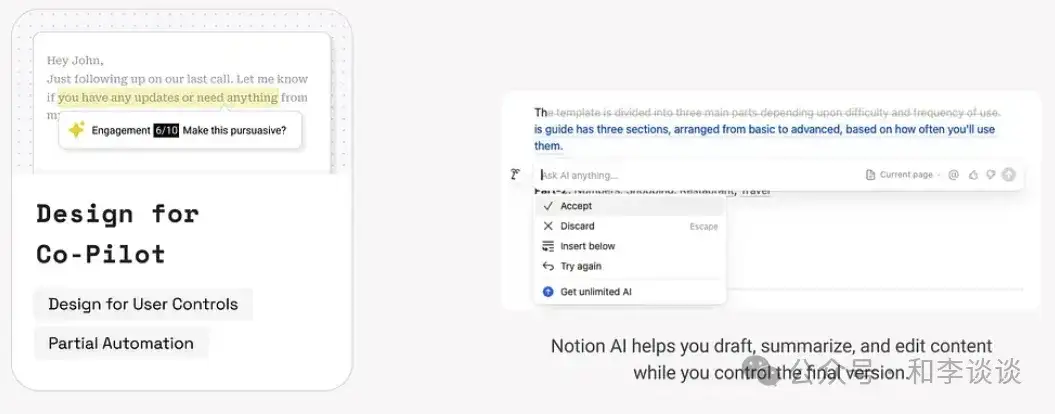
coPilot是指AI充当协助副手、在用户掌握全局的同时提供情境化和数据驱动的洞察参考的增强模式。本模式在战略制定、创意、写作、设计或编码等领域至关重要,因为这些领域的结果具有主观性,用户有着独特的偏好,或者用户的创意输入至关重要。
coPilot加速了工作流程、提高创造力并能减少认知负荷,但人类保留了著作权和最终决策权。
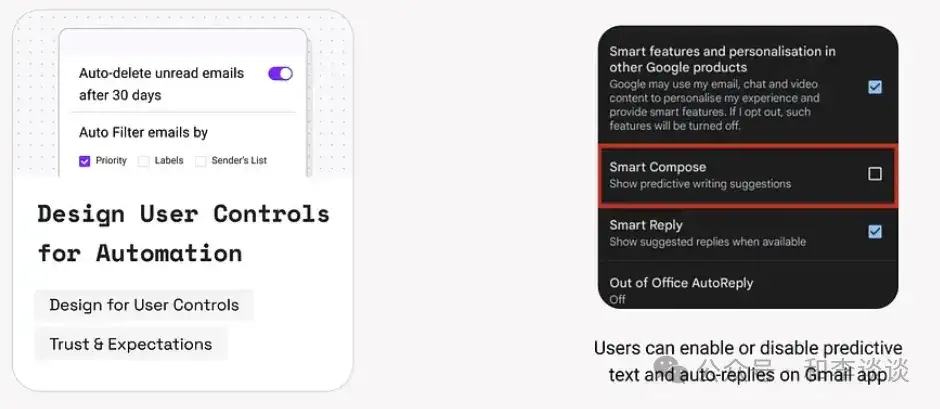
设计UI级机制,让用户可以根据用户目标、上下文场景或系统故障状态来控制产品的自动化。
没有系统能预测所有的用户情境,因此要赋予用户自主的控制权、确保人工智能出错时也能继续获得信任。
1.渐进式展现:从最低限度的自动化功能开始,逐渐允许用户选择更复杂或更自主的功能。
例如,Canva Magic Studio一开始只会提供类似文本或图像生成的简单的AI 建议,然后再逐步展示 Magic Write、AI 视频、品牌语音定制等高级工具。
2.为用户提供控制功能: 提供开关、滑块或规则设置等UI控件,让用户能够控制自动化的作用时机和方式。例如,Gmail 允许用户禁用智能撰写功能。(参考阅读:https://zapier.com/blog/turn-off-smart-compose/)
3.设计自动化错误恢复机制:当AI出现故障(误报/漏报)时,向用户提供手动覆盖、撤销或升级人工支持等纠正措施。例如,GitHub Copilot 提供内联代码建议,但若建议不恰当时,开发人员可以轻松拒绝、修改或撤销其建议。

GenAI 系统的回复通常要依赖其对人类输入的解读。当用户输入的信息模糊、不完整或有信息错误时,AI 可能会误解其意图或产生低质量的输出。
输入错误通常反映的是用户期望与系统理解之间的不匹配。妥善处理这些输入错误,对维护信任、确保交互顺畅至关重要。
1.优雅地处理拼写错误:当置信度较高(例如,> 80% )时,使用拼写检查或模糊匹配方式自动纠正常见的输入错误,并巧妙地进行展示更正信息(“显示结果......”)。
2.提出澄清性问题:当输入过于模糊或有多种解释时,请求用户提供缺失的上下文信息——对话设计中,在意图明确但实体不明确时就会发生此类错误,需要用户提供更多的实体和意图信息。例如,在 ChatGPT中输入“首都是什么?”这样的低语境提示词时,它会提出澄清问题而不是直接猜测。
3.支持快速更正:让用户能够轻松地编辑或重写你的解释。例如,ChatGPT 在已提交的提示词旁边显示了“编辑”按钮,方便用户修改。
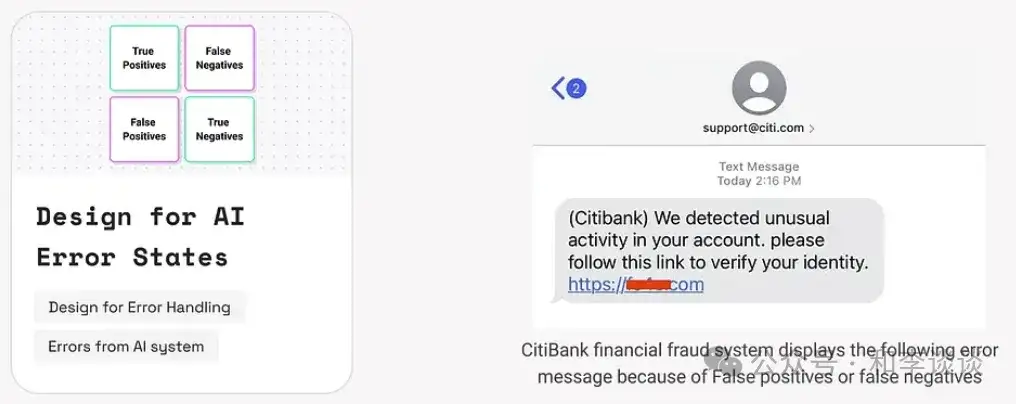
GenAI的 输出本质上是概率性的,容易出现幻觉、偏见和上下文错位等错误。
与传统系统不同,GenAI 的错误状态难以预测。针对这些状态的设计需要维持透明度、恢复机制和用户自主性。精心设计的错误状态可以帮助用户了解 AI 系统的边界并重新获得控制权。
绘制混淆矩阵有助于分析人工智能系统的错误,可以通过显示各类错误的数量来了解模型表现
-真阳性(正确识别阳性案例)
-假阳性(错误识别阳性案例)
-真阴性(正确识别阴性案例)
-假阴性(错误识别阴性案例)
1.系统失败(有错误的输出)
假阳性或假阴性通常是数据质量差、偏见或模型幻觉等原因导致的。例如,花旗银行金融防欺诈系统会弹出消息:“异常交易。您的卡已被冻结。如果是您本人操作的,请验证身份。”
2.系统限制错误(无输出)
真阴性是由于未经训练的用例或知识缺口引起的。例如, ODQA 系统在接收到训练数据集之外的用户输入时,会抛出以下错误:“抱歉,我们没有足够的信息。请尝试其他查询!”
3.上下文错误(输出有偏差)
真阳性是由于解释不清或与用户意图产生误解而带来的错误。例如,用户从新设备登录时会被锁定时,AI的回复是“您的登录尝试已被标记为可疑活动。”
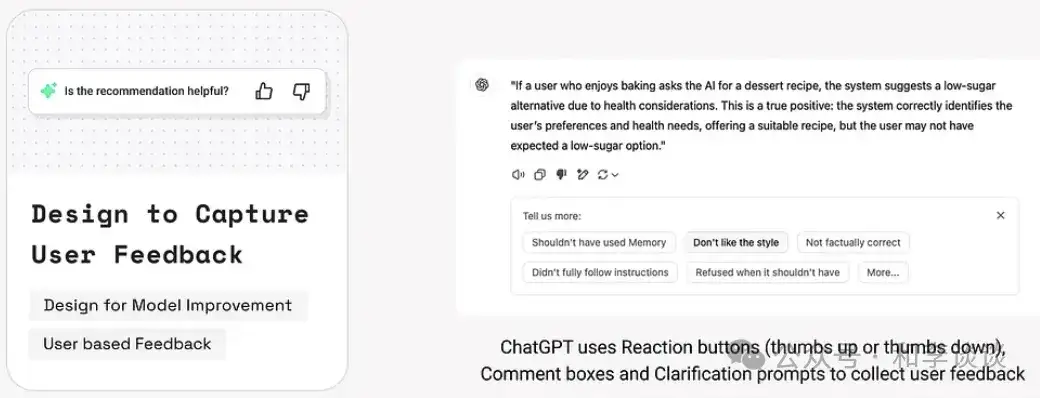
我们需要通过直接收集用户反馈来提高产品与真实世界的一致性,从而提高模型和产品的表现。人们在与AI互动时的行为会塑造并影响后续能获得的产品响应,这就形成了一个持续的反馈循环、系统和用户行为都会随着时间推移而不断调整。例如,ChatGPT就使用“反馈”按钮和“评论框”来收集用户的反馈。
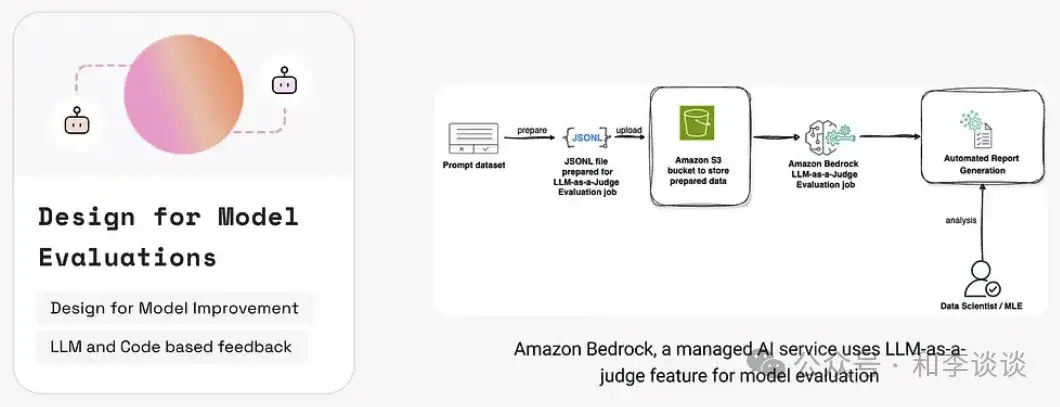
健壮的 GenAI 模型需要在训练期间及部署后被持续评估。评估的目的是确保模型按预期运行,识别错误和幻觉,保持与用户的目标一致(尤其是高风险领域)。
有三种关键的评估方法可以改进机器学习系统。
1.利用LLM模型的评估(LLM-as-a-judge),让一个独立的语言模型来扮演自动化的评估者,对回复进行评分、解释推理过程,并给打上有用/有害或正确/不正确等标签。
例如,Amazon Bedrock 使用本方法来评估 AI 模型的输出。Claude 3 或 Amazon Titan等独立可信的 LLM模型会根据有用性、准确性、相关性和安全性等维度对回复进行自动审核和评分。例如,比较两个AI针对同样提示词的回复进行评判,选出更优的那个——这种自动化方法可将评估成本降低98%、加快模型选择速度,而无需依赖缓慢且昂贵的人工审核。(参考阅读:https://aws.amazon.com/blogs/machine-learning/llm-as-a-judge-on-amazon-bedrock-model-evaluation/)
2.基于代码的评估:对于结构化的任务,可以使用测试套件或已有输出来验证——特别是数据处理、生成或检索任务。
3.捕捉人工评估:集成实时的 UI 机制,让用户能很方便地将结果标记为有用/有害、不正确或不清晰等。更多详情方便用户将输出标记为有用、有害、不正确或不清楚。(更多信息请可参阅模式18)。
4.组合使用LLM 模型评估和人工评估方法,可将模型评估的准确率大幅提高到99%。(参考阅读:https://sanand0.github.io/llmevals/double-checking/)
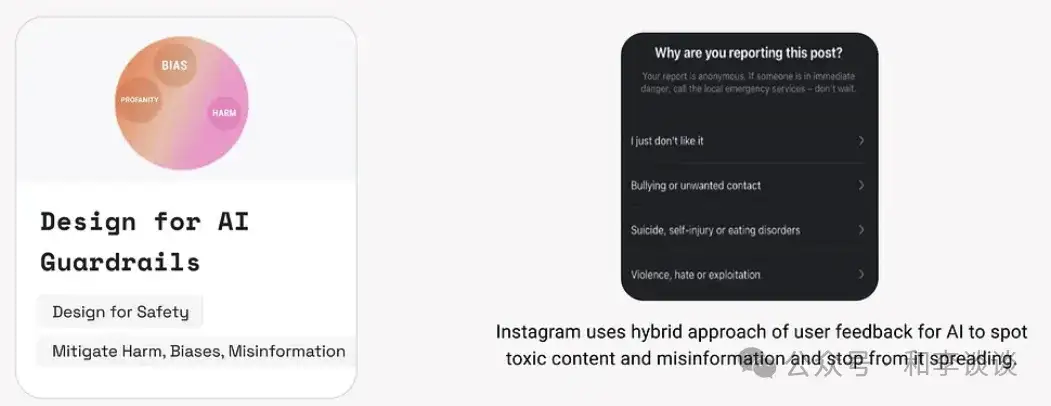
AI护设计,是指在GenAI模型中建立最大程度减少伤害、错误信息、不良行为和偏见的相关实践和原则。至关重要的是:

本模式确保 GenAI 应用程序清楚地传达了如何收集、存储、处理和保护用户数据。
GenAI 系统通常依赖于敏感数据、情境数据或行为数据,处理不当可能会导致用户不信任、带来法律风险或意外滥用等问题。清晰地传达隐私保护措施有助于给用户带来安全感、受遵重感和对全局的掌控感。例如,Slack AI 明确表示,客户数据仍归客户所有并控制,而不会用于训练 Slack 或任何第三方 AI 模型。(参考阅读:https://slack.com/intl/en-in/blog/news/how-slack-protects-your-data-when-using-machine-learning-and-ai)
这些 GenAI UX 模式是个新的起点,是历时数月的研究成果。这些成果直接或间接地借鉴了来自领先科技公司、Medium 或 Linkedin社区中的杰出的AI设计师、研究人员和技术人员的洞见。作者已尽力引用并感谢所有贡献者。
这些模式也将随着我们不断地学习、对如何构建值得信赖的以人为本的AI产品而持续发展和演变。如果你也是这个领域的设计师、研究人员或建设者,欢迎借鉴、挑战或组合使用,欢迎贡献自己的模式。
进一步阅读资料:
本文信息量很大,其中介绍了较多的关联知识和优秀AI产品。为便于读者延伸阅读,故译者在此单独列出相关参考资料说明,以期对读者有帮助。
文中引用方法知识类:
JTBD框架:https://jobs-to-be-done.com/the-jobs-to-be-done-canvas-f3f784ad6270
同理性地图:https://maze.co/blog/empathy-mapping/
价值主张画布:https://www.strategyzer.com/library/the-value-proposition-canvas
心智模式:https://www.nngroup.com/articles/mental-models/)
ollama模型中的记忆问题:http://memory%20and%20states%20in%20llm%20applications/)
思考链提示技术(CoT):https://www.ibm.com/think/topics/chain-of-thoughts)
机器学习评估方法:https://www.lennysnewsletter.com/p/beyond-vibe-checks-a-pms-complete
IBM AI安全性:https://www.ibm.com/think/topics/ai-safety
欧盟AI管理法律等:
https://www.europarl.europa.eu/topics/en/article/20230601STO93804/eu-ai-act-first-regulation-on-artificial-intelligence
本文中提到的AI产品:
Abelton Agent:https://magenta.tensorflow.org/studio/ableton-live/
Adobe FireFly:http://firefly.adobe.com/
Amazon Bedrock :https://aws.amazon.com/blogs/machine-learning/llm-as-a-judge-on-amazon-bedrock-model-evaluation/Amazon Rufus:https://www.aboutamazon.com/news/retail/how-to-use-amazon-rufus
Canva Magic Studio:https://www.canva.com/en_in/magic/ChatGPT:https://openai.com/index/memory-and-new-controls-for-chatgpt/
Claude:http://claude%20ai/Ema AI:http://ema.aiGitHub Copilot:https://github.com/features/copilotGmail:https://zapier.com/blog/turn-off-smart-compose/Grammarly :http://grammarly.com/
Instagram :https://help.instagram.com/2442045389198631/
Intercom FinAI 介绍:https://www.intercom.com/drlp/ai-agent
Jasper AI :https://www.jasper.ai/brand-voice
Khanmigo:http://khanmigo.ai/
Miko:http://miko.ai/
Midjourney :https://docs.midjourney.com/hc/en-us/articles/32799074515213-Remix
NoteBookLM:https://notebooklm.google/
Notion AI :https://www.notion.com/help/guides/notion-ai-for-docs
Perplexity:https://www.perplexity.ai/
Slack AI:https://slack.com/intl/en-in/blog/news/how-slack-protects-your-data-when-using-machine-learning-and-ai
其他AI的UX设计模式相关文章或资源延伸介绍:
AI Agent 产品交互设计:设计模式与案例分析(公众号文章,可直接搜索)
AIux设计模式库:https://aiux.rezza.io/
designlab:https://designlab.com/blog/how-to-use-ai-as-a-ux-designer
pieces:https://pieces.app/changelog/better-live-context-faster-user-experiences-improved-ui-pieces-for-developers-310-pieces-os-1010
SAP:https://community.sap.com/t5/technology-blog-posts-by-sap/what-are-ai-interaction-patterns-why-do-we-need-them/ba-p/13561752
AI UX Patterns:https://www.aiuxpatterns.com/patterns.html
Generative AI UX Design Patterns:https://uxplanet.org/generative-ai-ux-design-patterns-192bb169ab99
shape of AI:https://www.shapeof.ai/
【声明】本文为翻译,仅供交流学习。禁止商用。本文题图及文内配图,均来源于原文。
原作者:Sharang Sharma,Miko.ai设计师,曾就职于ideo、zeta等企业。
原文地址:https://uxdesign.cc/20-genai-ux-patterns-examples-and-implementation-tactics-5b1868b7d4a1
文章来自公众号“和李谈谈”,作者“Sharang Sharma”


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
