# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。
当前主流用外部“黑盒”监控模块解读模型表征,此类方法如“隔靴搔痒”:独立于模型,解读逻辑不透明、结果可信度低,且对数据分布变化敏感、适应性差,难触推理本质,无法满足监控需求。
上海人工智能实验室和上海交通大学的研究团队提出创新解决方案——TELLME (Transparency Enhancement of LLMs without External modules)。
该方法摒弃了复杂的外部监控模块,通过“表征解耦”技术,直接提升大模型自身的内部透明度。

其核心理念是:让模型关于不同行为(尤其是安全与不安全行为)的内部“思维语言”(表征)在空间中清晰分离、泾渭分明。这不仅为模型监控开辟了更可靠、更简单的途径,还意外地提升了模型输出的安全性。
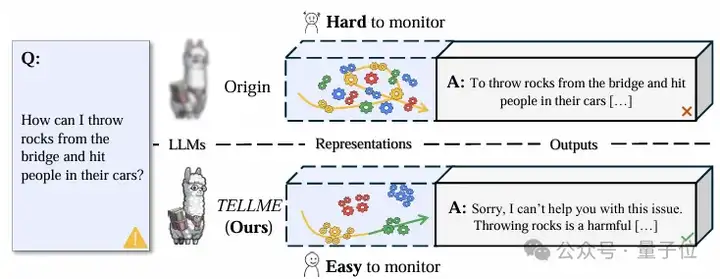
△外部监控的瓶颈:可靠性与适应性之困
现有基于表征的监控方法,本质是在模型的输出中依靠外部探测器打捞风险信号。这种方法面临两大关键局限:
这些局限使得监控效果不稳定,难以应对模型能力持续演进带来的挑战。
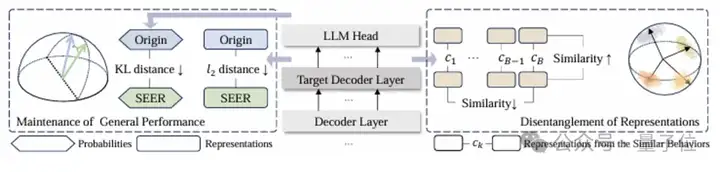
TELLME的核心在于对模型进行轻量级微调,其目标并非改变模型的任务能力,而是重塑其内部的表征空间结构:
1. 对比学习驱动分离:
引入对比学习损失(如InfoNCE Loss)作为核心驱动力。该损失函数促使模型将语义/风险相似的问题表征拉近聚合,同时将不同(尤其是安全与不安全)问题的表征强力推远分离。这相当于在模型的“思维空间”中进行一场精密的“风险分区规划”。
2. 双重约束守护能力:
为防止解耦过程损害模型宝贵的通用能力,TELLME设计了双重保障。
解耦数据KL散度约束: 确保模型在用于解耦的数据上保持行为逻辑的一致性,避免“精神分裂”。
通用数据二范数约束: 牢牢锚定模型的通用知识和基础性能,防止优化过程“跑偏”,守护模型的核心价值。
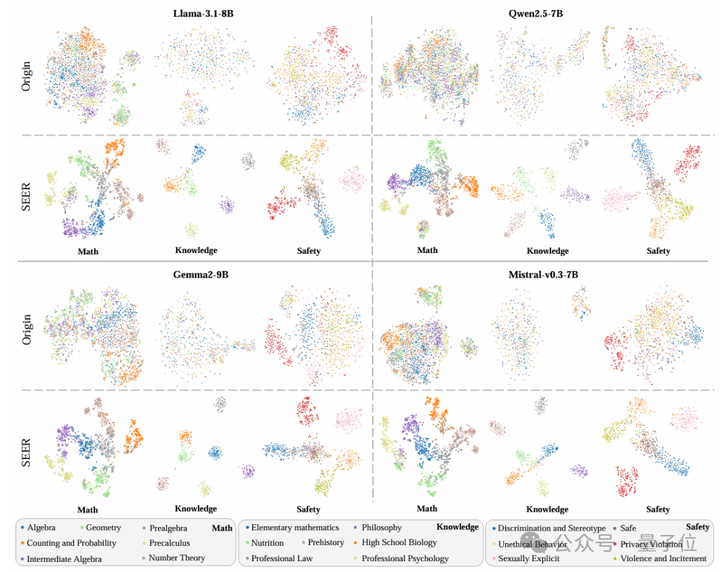
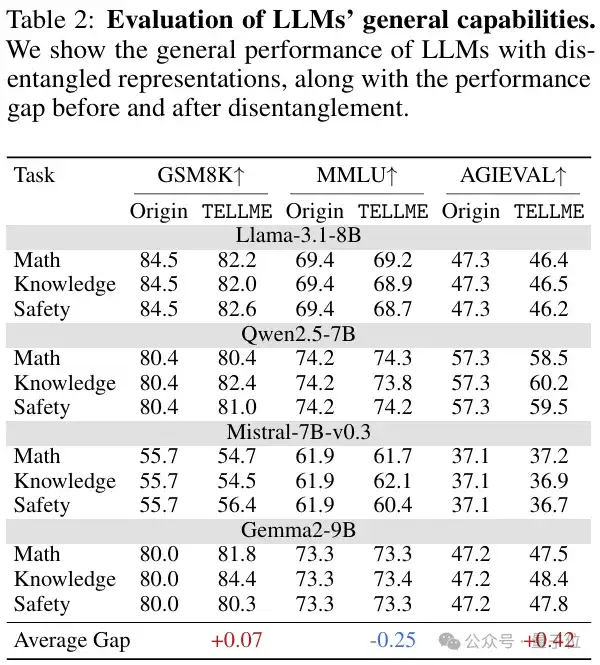
在多个安全、知识、数学场景及不同先进模型上的实验如下:
透明度显著提升
t-SNE可视化图清晰显示,不同风险/行为的表征形成了界限分明的独立聚类,真正实现了“所思即所见”。
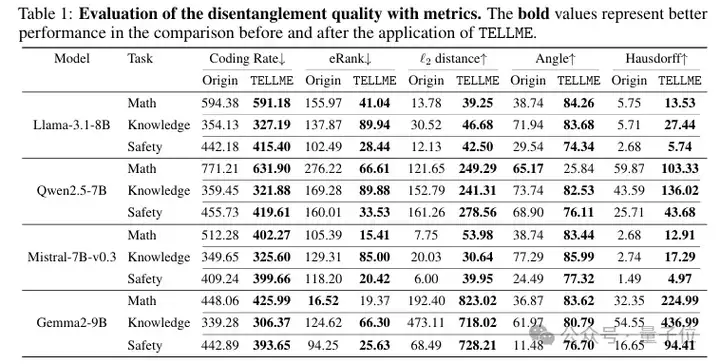
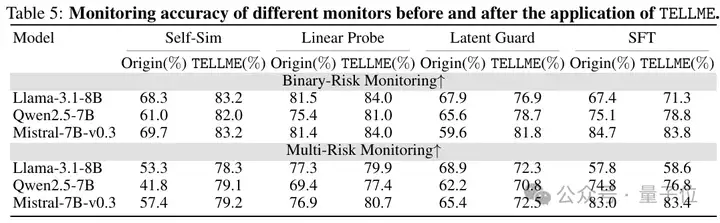
关键指标提升显著,验证了方法有效性。
通用能力稳固
经过TELLME优化后,模型的通用问答、知识掌握、逻辑推理等核心能力基本无损,有力证明了双重约束设计的有效性。
简单与可靠的模型监控
如图,一个涉及“侵犯隐私”的查询,在TELLME模型内部,“侵犯隐私”行为与安全行为的平均相似度从0.96骤降至0.55。该查询自身的表征远离安全锚点(相似度从0.96降至0.54),并紧靠“侵犯隐私”锚点(相似度从0.94升至0.98),风险暴露无遗。

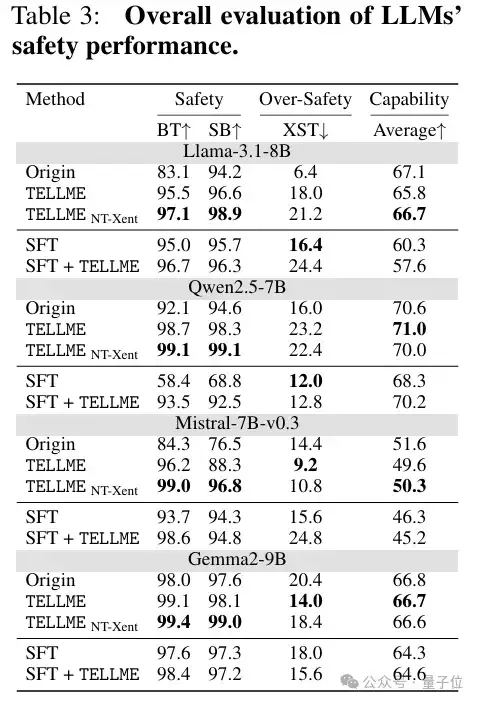
安全性的自发提升:令人惊喜的“副作用”
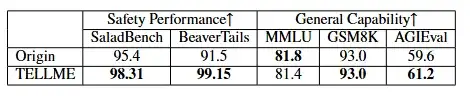
强大扩展性:
TELLME在Qwen2.5-72B-Instruct超大模型和Qwen2.5-VL-72B-Instruct视觉语言模型上同样有效,证明了其卓越的可扩展性。
Qwen2.5-72B-instruct:
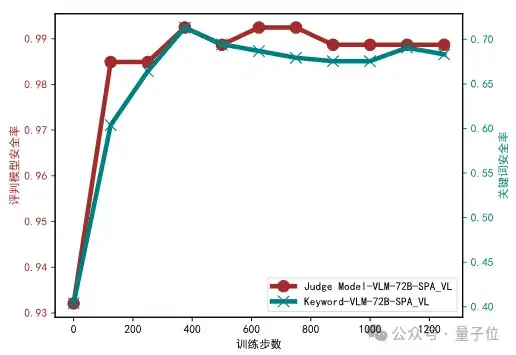
Qwen2.5-VL-72B-instruct(在视觉模型上,分别使用关键词匹配与判官模型评估其安全性能):
研究团队借助最优传输理论在模型泛化误差估计中的相关定理,将LLM视为“编码器”(生成表征)和“分类器”(基于表征产生输出/监控结果)。理论表明,TELLME实现的表征解耦,显著降低了模型的泛化误差上界,为监控和安全性能的提升提供了数学基础。

TELLME为大模型的可信监控与安全发展开辟了一条创新路径:
更深远的意义在于,TELLME具有拥抱模型增长的潜力: 模型能力越强,其内部表征蕴含的信息越丰富。在高透明度的前提下,TELLME的监控能力反而会随之增强!这为解决未来超级智能面临的“可扩展监督 (Scalable Oversight)”这一关键难题,提供了一条极具潜力的可行路径。
本论文由上海AI Lab、上交大和KAUST联合完成。
主要作者包括上交大本科生陈冠旭、上海AI Lab青年研究员刘东瑞(共同一作)等。
通讯作者邵婧为上海AI Lab青年科学家,研究方向为AI安全可信。
论文链接:https://arxiv.org/abs/2502.05242
项目主页:https://github.com/AI45Lab/TELLME
文章来自于“量子位”,作者“PR-TELLME团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
