# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你对着家里的机器人说:“去厨房,看看冰箱里还有没有牛奶。”
它不仅准确走到了厨房,还在移动过程中避开了椅子,转身打开冰箱,并回答你:“还有半瓶。”
这不是遥远的科幻,而是视觉语言导航技术的下一站。
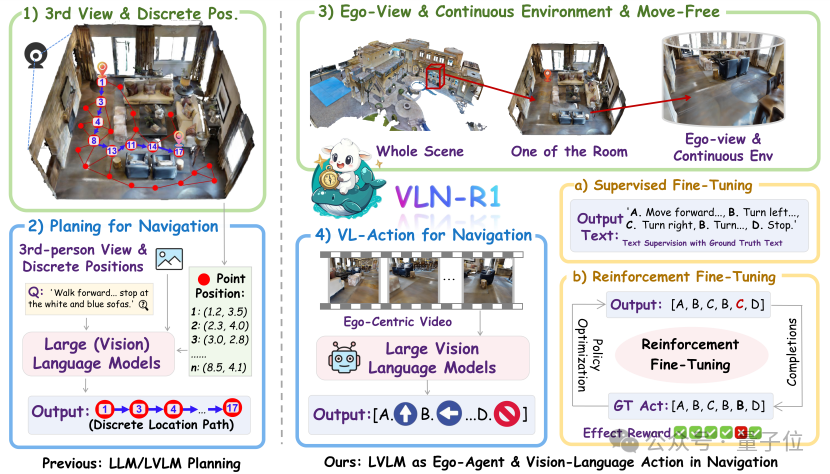
由香港大学与上海AI Lab联合提出的VLN-R1,具备将自然语言指令直接转化为第一人称视角下的连续导航动作的能力,无需依赖离散地图,能在复杂环境中灵活感知、决策与行动,实现类人级别的具身智能导航。

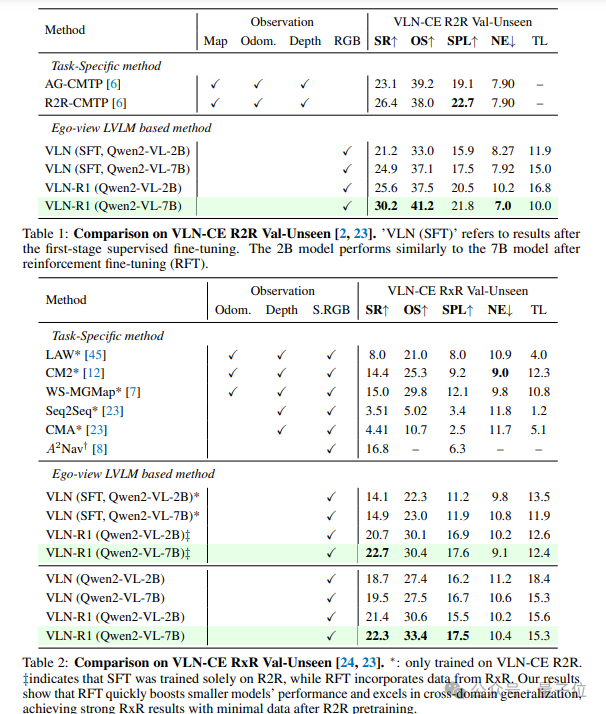
在VLN-CE基准测试中,VLN-R1展现出了很强性能,仅用Qwen2-VL-2B模型(20亿参数),通过RFT训练后就超越了7B模型的SFT结果。
更具挑战性的长距离导航中,VLN-R1实现了“跨域迁移”——在R2R上预训练后,仅用1万RxR样本进行RFT,性能就超过了使用完整RxR数据训练的模型,彰显出极强的数据效率。
视觉语言导航(VLN)是具身人工智能领域的核心挑战之一。其核心要求是:让智能体能够基于自然语言指令(如“走到客厅的沙发旁”),在现实环境中自主完成导航任务。
这一任务的复杂性在于,智能体需要同时理解语言语义,并结合实时视觉感知来规划行动路径,实现“语言指令”与“环境交互”的跨模态融合。
当前主流的基于语言模型的导航系统,普遍依赖离散拓扑图进行路径规划。具体表现为:
VLN-R1的核心突破在于打破了“视觉输入→文本描述→离散决策”的传统链条,直接让LVLM(如Qwen2-VL)以第一人称视频流为”眼睛”,输出连续导航动作(前进、左转、右转、停止)。
这一框架具有三大创新支柱:
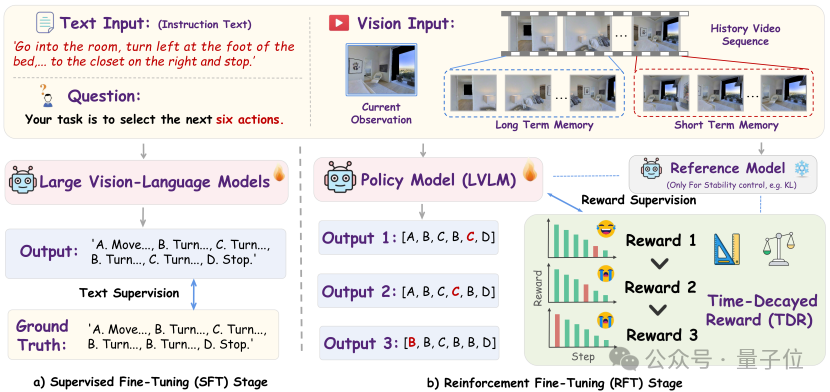
两阶段训练+时间衰减奖励:从模仿到强化的智能进化
1.监督微调(SFT):让模型先通过专家演示学习”正确动作序列的文本表达”,例如看到”前方有门”时输出”FORWARD”动作描述。
2.强化微调(RFT):为了让导航需要考虑动作的前后关联(比如现在转错方向,后面就很难到达目标)。为此,强化微调阶段引入了 “奖励机制”,让模型在试错中学会更聪明的决策:
a.分组对比优化(GRPO)
模型会针对同一组指令和画面,同时生成多个不同的动作方案(比如 8 种走法),然后通过比较这些 方案的“好坏”来优化策略:好的方案会被鼓励多生成,差的方案则减少出现,就像人类在多个选项 中选择最优路径。
这种方法不需要提前设定固定的奖励规则,而是通过方案间的相对优劣来学习,更符合真实环境的复杂性。
b.时间衰减奖励(TDR):让模型关注“眼前重点”
在真实导航场景中,当前动作的准确性直接决定了后续规划的可行性 —— 就像人类走路时若不先避开眼前的障碍物,即便远处的路线规划得再完美也会碰壁。
TDR机制正是模拟了这一人类直觉:它对近期动作(如当前步、下一步)赋予更高的奖励权重,而随着时间推移,远期动作(如 5 步之后)的权重会逐步降低。
这种设计让模型学会优先确保眼前动作的精准执行,比如先完成关键的转弯避开障碍,再循序渐进地考虑后续步骤,避免因过度关注远处目标而忽视当下的环境风险,如同人类行走时总是先看好脚下的每一步,再规划前方的行进路线。
VLN-Ego数据集:构建具身智能的“训练操场”
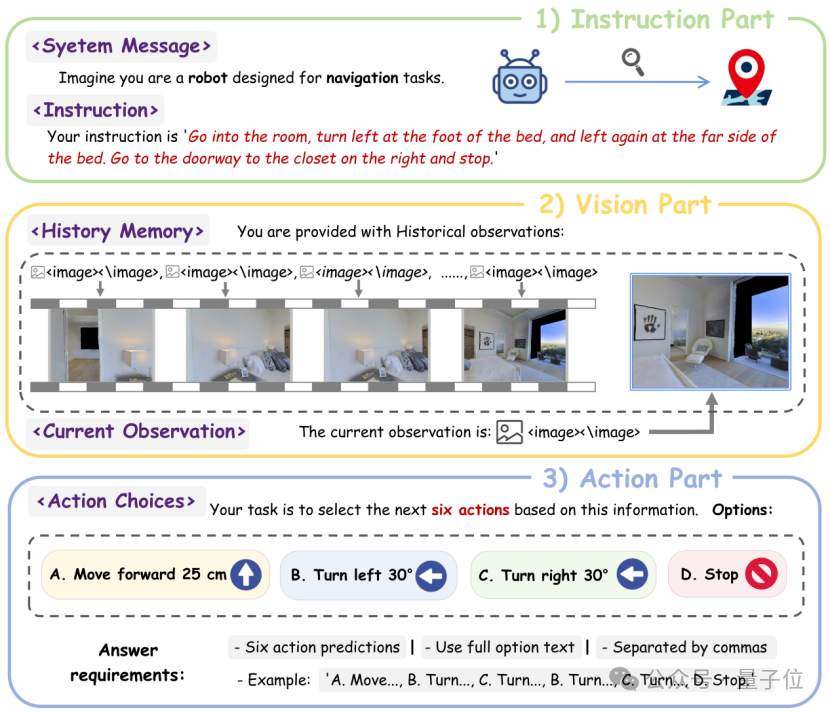
研究团队利用Habitat模拟器构建了全新的VLN-Ego数据集,包含63万R2R(房间到房间)和120万RxR(跨房间)训练样本。每个样本由三部分组成:自然语言指令(如“走过餐桌,左转进入走廊”)、第一人称历史视觉记忆与当前观测、未来6步的动作标签。
与传统数据集不同,VLN-Ego完全基于第一人称视角,摒弃了全局地图等“作弊”信息,迫使模型学会基于实时视觉输入的决策能力。
短时记忆采样:平衡历史经验与实时感知
为解决视觉序列处理中“近期信息过载、长期记忆丢失”的难题,VLN-R1提出了长短时记忆采样策略。
模型会以较高频率采样最近M步的短期记忆(如当前看到的沙发位置),同时以较低频率抽取更早的长期记忆(如走廊的初始方向),通过这种”远近结合”的方式,确保Agent在复杂环境中既不迷失方向,又能对突发情况做出反应。
除了前文所描述的性能表现,更值得关注的是VLN-R1的”小而美”特性——通过RFT优化,2B模型性能直逼7B模型,这为资源受限场景(如家用机器人)的落地提供了可能。

该研究的核心启示在于:具身智能的关键不是复杂的模块化设计,而是让模型像人类一样,通过“感知-决策-行动”的闭环进行学习。VLN-R1证明,LVLM完全有能力成为这个闭环的“控制中枢”,而时间衰减奖励等机制则为模型注入了对物理世界时序规律的理解。
随着VLN-Ego数据集与配套训练框架的开放,该方法的可复现性和拓展性正在提升。从工厂物流机器人到家庭服务助手,该框架正在促进AI从“数字智能”向“具身认知”跨越。
主页网址:https://vlnr1.github.io/
代码网址:https://github.com/Qi-Zhangyang/GPT4Scene-and-VLN-R1
文章来自于微信公众号“量子位”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
