# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
JEPA-2(V-JEPA 2)是Meta最新推出的视频世界模型,采用视图嵌入预测(Joint Embedding Predictive Architecture)框架进行自监督预训练。JEPA-2使用基于视觉Transformer的架构(参数规模约1.2亿至12亿级别),在第一阶段对千小时以上的网络视频和图像进行无监督预训练,在掩码后预测嵌入表示;第二阶段用约62小时的机器人交互视频及动作数据进行微调,使模型具备动作条件预测能力。MAE(Masked Autoencoder)是由He等人提出的视觉自编码器方法,采用不对称的ViT编码器–解码器结构:在输入图像中随机遮盖75%的补丁,仅对可见补丁编码,并通过轻量解码器重构缺失像素。DINOv2是Meta提出的自监督视觉Transformer方法,它通过学生-教师蒸馏的方式,在超过1亿张精心筛选的图像上训练,生成通用视觉特征。下表对比了几种主流模型的架构、训练数据和自监督策略:
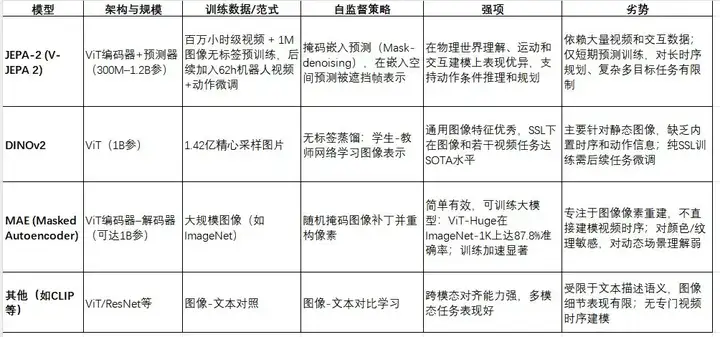
下表和列表总结了各模型在视觉任务中的表现差异。总体而言,JEPA-2在视频理解和物理推理任务上性能突出,而DINOv2/MAE等传统视觉SSL模型在纯图像任务上表现优异。
视频理解与动作预测:JEPA-2专注于视频世界建模,在运动理解任务上表现最好。如在Something-Something V2(SSv2)动作识别上,JEPA-2(ViT-g)Top-1准确率达75.3%,显著高于同级别的动态图像模型。在Epic Kitchens-100的动作预测任务中,JEPA-2在不同规模下均超过先前SOTA(如InAViT、Video-LLaMA等),尤其大模型(1B参)Action准确率可达38.0%。而DINOv2虽在图像任务卓越,但对视频长时信息缺乏内在建模,使用多帧输入时性能增长有限。
图像分类与通用视觉任务:DINOv2在图像分类上达到新SOTA水平;据Meta报道,DINOv2在ImageNet-1k分类上“显著超越”先前SSL模型,并与弱监督方法(如CLIP)相当甚至更好。MAE在图像分类上也表现出色:例如纯ImageNet预训练ViT-Huge可达87.8%精度。JEPA-2虽以视频预训练为主,但在Frozen Probe测试中也能达到约84.6%的ImageNet精度,略优于之前版本。
多模态感知与物理推理:JEPA-2还针对物理常识推理发布了新基准(IntPhys2、MVPBench、CausalVQA)以评估视频因果推理能力。在综合基准测试中,JEPA-2对比其他视觉模型(包括SigLIP、Perception Encoder等)在以视频为主的任务上均占优势。DINOv2等图像模型虽未专门针对因果推理,但其通用性使其在一些多模态任务(如基于图像的问答、深度估计)也取得优异成绩。
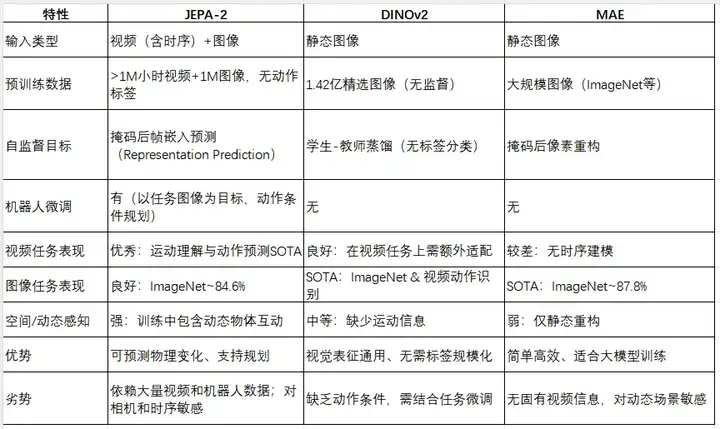
JEPA-2作为视频世界模型,在具身智能(机器人)场景中展现出显著潜力。Meta报告指出,基于JEPA-2的机器人系统可以在短期内通过模拟前推规划实现复杂操作:例如给定目标图像,机器人使用JEPA-2预测一系列动作并实施,每步均重新规划,以渐近目标。在仓库抓取和搬运任务上,新物体与场景中取得了65%–80%的成功率。此外,JEPA-2已被用于人机交互和物理推理基准测试,在运动识别(Something-Something v2)和未来动作预测(Epic-Kitchens)等任务上均达到前沿水平。
空间导航方面,JEPA-2尚无公开评测,但其对周围物体动态和交互的建模能力有望辅助场景理解和规划。动作预测与计划上,JEPA-2通过动作条件建模,对下一步动作和未来序列可做预推断(如1秒后动作预测任务,精度优于多个专业模型)。然而,局限性也很明显:JEPA-2的规划多为短期(秒级)模拟,对长时程规划仍有挑战;模型对相机视角和目标表达(图像指定目标)较敏感,真实世界复杂性下表现尚待验证。此外,JEPA-2目前主要在内部数据集训练,适应性和泛化需要更多公开测试。总的来说,JEPA-2为机器人赋予了类似“前瞻”物理直觉的能力,但要实现鲁棒的长程行为(如导航避障、持续执行任务)仍需进一步研究。
Project CAIRaoke:Meta AI推出的端到端对话式助手模型,目标是实现更自然的任务导向对话。与传统对话系统(通常分为NLU、DST、DP、NLG四个模块)不同,CAIRaoke采用单一神经网络来完成所有对话组件,从而便于扩展新功能领域。该模型应用于Portal智能屏幕,可执行如提醒设置等任务,完成率显著高于以前的模块化方法。Meta公开指出CAIRaoke集成了BlenderBot等技术以获取外部知识和减少生成错误。虽然CAIRaoke专注于语言与对话,它的开放设计理念(单模型一体化)表明未来可以与视觉模块结合,例如配合摄像头信息理解周围环境。然而,目前该项目更多关注语言,对JEPA-2这类视觉预测模型暂无直接集成的公开方案。
Habitat:一个开源的具身AI仿真平台,由Meta(FAIR)发起,用于训练导航和交互型虚拟机器人。Habitat由高性能的3D仿真器(Habitat-Sim)和强化学习环境库(Habitat-Lab)组成,可加载真实世界的3D扫描场景和物理对象。其特点是高速度高保真:单线程即可每秒渲染几千帧,GPU多进程可达万帧速度。通过Habitat研究人员可在模拟中并行验证导航、物体操作、指令跟踪等任务。该平台完全开源(GitHub上有Habitat-Sim和Habitat-Lab代码),并设有年度挑战赛以评测代理泛化能力。JEPA-2与Habitat的协同可体现在:Habitat提供大量交互环境,未来可用JEPA-2作为视觉世界模型对虚拟传感器数据建模,实现学习型导航与预测;反过来,JEPA-2可以在Habitat仿真中测试其规划和行动推理能力。
Droidlet (Fairo):Meta提出的开源具身智能平台,目标是简化多模态智能体的构建。Fairo(Unified Robotics Platform)框架下包含多个项目:Droidlet专注于基于语言的人机交互,提供构建智能体的工具,支持自然语言指令、任务指定以及与人类交互;Polymetis提供实时机器人控制器接口,可在仿真和真实硬件之间无缝切换;Meta Robotics Platform (MRP) 用于机器人资源管理与编排。Droidlet本身可在Habitat等环境中运行虚拟机器人,通过对话和视觉信息完成任务。该项目开源于GitHub,促进社区复现和扩展。JEPA-2和Droidlet的协同可能体现在:Droidlet的智能体可以集成JEPA-2生成的视觉表示和预测信息,从而在接受语言指令时利用更丰富的世界模型。比如,机器人在执行“把杯子放在桌上”的指令时,可使用JEPA-2预测不同动作序列的结果来规划路径。
Meta在具身智能领域的这些项目各有侧重:CAIRaoke侧重对话与知识整合,Habitat提供训练环境,Droidlet构建代理框架,而JEPA-2则专注于视觉世界建模与物理推理。尽管目前尚无公开工作将JEPA-2直接嵌入上述系统,但它们之间有潜在的协同价值。举例来说,使用Habitat或Fairo等平台产生的多样化视频数据可以进一步丰富JEPA-2的训练;反过来,JEPA-2可作为高级感知模块,为这些平台上的智能体提供动作预测和规划支持。未来一个完整的多模态智能体可能会结合CAIRaoke的对话能力、JEPA-2的视觉预测和Habitat/Droidlet的交互框架,共同推动具身智能的发展。
文章来自于“Xbot具身知识库”,作者“木木-具身”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
