# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就像是播放音乐,Prompt Engineering是在调音响的音量,那Context Engineering就是在设计整个音响系统,从音源、功放、音箱到房间声学,每个环节都要精心设计。Context Engineering本质上是设计和优化AI模型整个上下文窗口的工程学科。这不只是一个技术升级,更像是思维模式的根本转变。
这是Github目前上1.2kStar的最新实用的Context Engineering工具、指南和基于第一性原理的上下文研究。https://github.com/davidkimai/Context-Engineering/tree/main
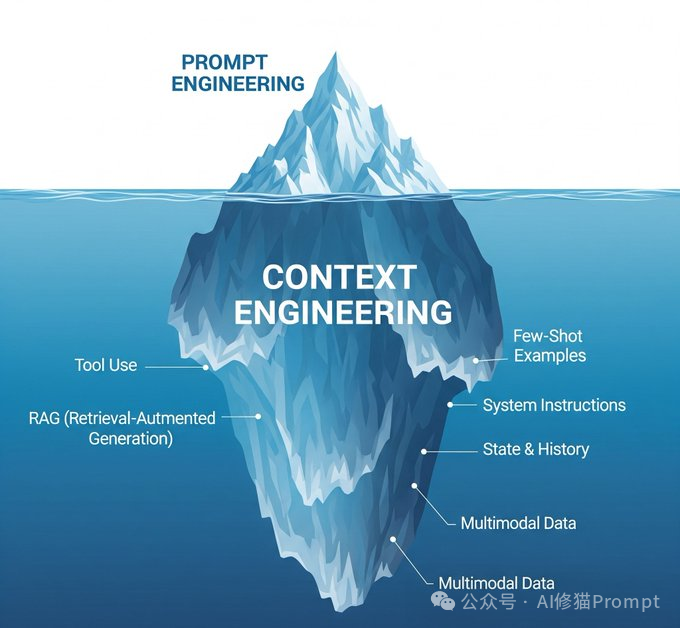
我看完后也大受震撼,Context Engineering已经超越了传统的prompt engineering,进入了一个更加理论化和数学化的层面。这让我想到了物理学中的场论...把上下文建模为连续的语义场,而不是离散的token序列。这对于依赖准确性与规避风险的行业非常关键,可以说上下文工程是当前能提升合规性、一致性与信任度的最好也是唯一方法。
原子级:单指令的根本局限与测量基准
就像卡尔·萨根说的"如果你想从头开始做苹果派,你必须先发明宇宙",Context Engineering从最基础的"原子"开始。一个独立的指令到LLM。但这种看似简单的方法暴露出根本性问题:无记忆、演示能力有限、易产生歧义、输出变化极大。
研究者的实验数据很说明问题:
# 原子级测试:同一提示重复5次
atomic_prompt = "列出糖尿病的5个症状"
responses = [llm.generate(atomic_prompt) for _ in range(5)]
# 结果:通常会得到远超5个的不同症状,一致性极差
但原子级有其价值,它帮我们建立效率基准线。在质量-复杂度曲线上,原子级提供了最小token开销的控制组,让我们能够量化后续改进的真实效果。
分子级:Few-shot学习的组合智慧与模式识别
当多个"原子"组合成"分子"时,我们看到了质的飞跃。分子级的核心不是问问题,而是教模式。通过Few-shot学习,模型能识别并延续模式,通常带来10-30%的准确率提升。
关键的发现是"整体大于部分之和":
# 分子级情感分析示例
instruction:"根据示例分类情感"
examples:
-input:"食物很棒!服务态度也不错"
output:"积极"
-input:"等了40分钟,食物还是冷的"
output:"消极"
-input:"还行吧,没什么特别的"
output:"中性"
current_input: "今天的体验超出预期"
研究显示存在收益递减规律:每增加一个示例都有成本,但质量提升逐渐减少。对大多数任务,2-5个精选示例就能达到最佳token效率。
细胞级:记忆与状态的生命体征
分子级的问题在于"健忘症",每次交互都是全新开始。细胞级引入了跨交互的状态记忆,就像生物细胞维持内部状态一样。这不只是简单的对话历史存储,而是智能的记忆管理系统。
实际应用中,我们面临"记忆token预算问题":
对话轮次增长 → 上下文窗口填满 → 需要记忆管理策略
四种核心记忆管理策略:
器官级:多智能体协作的复杂系统
单个上下文单元,无论多复杂,都有处理能力的天花板。器官级Context Engineering通过专业化分工和协调机制突破这个限制。就像生物器官由特化细胞协同工作,我们的"器官"由多个专门的LLM单元组成。
典型的器官架构包含三层:
┌─────────────────┐
│ 协调器(大脑) │ 任务分解、信息路由、冲突解决
└─────────────────┘
↕
┌─────────────────┐
│ 共享记忆系统 │ 工作记忆、知识库、过程日志
└─────────────────┘
↕
┌─────────────────┐
│ 专业化细胞群 │ 研究员 推理员 评估员 工具用户
└─────────────────┘
不同的控制流模式适用于不同场景:串行流水线适合有明确依赖的步骤,并行MapReduce适合可独立处理的子任务,反馈循环适合需要迭代改进的任务。
符号机制:从神经到符号的涌现处理
2025年的突破性研究发现,LLM内部发展出了涌现的三阶段符号架构,这完全改变了我们对模型内部工作机制的理解。
Yang等人发现的三阶段架构:
输出层 ← 检索头:将抽象变量映射回具体token
中间层 ← 符号归纳头:识别抽象模式如"ABA"
早期层 ← 符号抽象头:将token转换为抽象变量
这个发现的实际意义是:模型不是在做简单的模式匹配,而是在进行真正的抽象推理。当您给出"dog cat dog"和"blue red blue"这样的例子时,模型识别的不是具体的词,而是抽象的"ABA"模式。
神经场基础:从离散到连续的语义空间
传统方法把上下文看作离散的token序列,但神经场理论提出了革命性的视角:上下文是连续的语义场,信息以场的形式传播、交互和演化。
想象池塘中的涟漪:扔下一颗石子产生同心圆涟漪,多颗石子的涟漪会相互作用,同相位时增强,反相位时抵消。语义场就是这样的媒介,概念和信息在其中传播和相互作用。
神经场的五个核心原理:
1.性:场是连续的,不是离散的chunks
2.共振:相似信息模式会互相增强
3.持久性:重要模式会持续共振,超越原始输入
4.熵组织:场自然地按相关性和连贯性组织信息
5.边界动力学:可调节的边界控制信息流入流出
涌现与吸引子:意义结晶的动力学原理
最令人着迷的是涌现现象:简单组件的相互作用产生了无法从个别部分预测的复杂行为。就像鸟群的复杂飞行模式来自个体鸟类的简单规则,语义场中的意义也是涌现的结果。
吸引子动力学解释了意义如何"结晶":
想象一个三维语义景观,有深浅不同的"盆地"
- 深盆地 = 强吸引子 = 稳定的解释
- 浅盆地 = 弱吸引子 = 不稳定的解释
- 盆地边界 = 语义障碍 = 不同解释间的分界
当您输入模糊信息时,语义状态就像球滚向最近的盆地,最终"落入"某个稳定的解释。这解释了为什么有些输入会收敛到特定解释,而另一些会在不同解释间"摇摆"。
关键洞察:我们不仅要设计输入内容,更要设计语义景观的形状,创建合适的吸引子盆地,引导模型朝向期望的解释收敛。这从根本上改变了Context Engineering的设计哲学。
基于LangChain框架与认知科学研究的深度融合,Context Engineering构建了四个相互协作的核心策略:Write(撰写)、Select(选择)、Compress(压缩)、Isolate(隔离)。这不仅是技术策略的组合,更是基于认知科学、设计模式理论、信息论和系统论的完整工程体系。
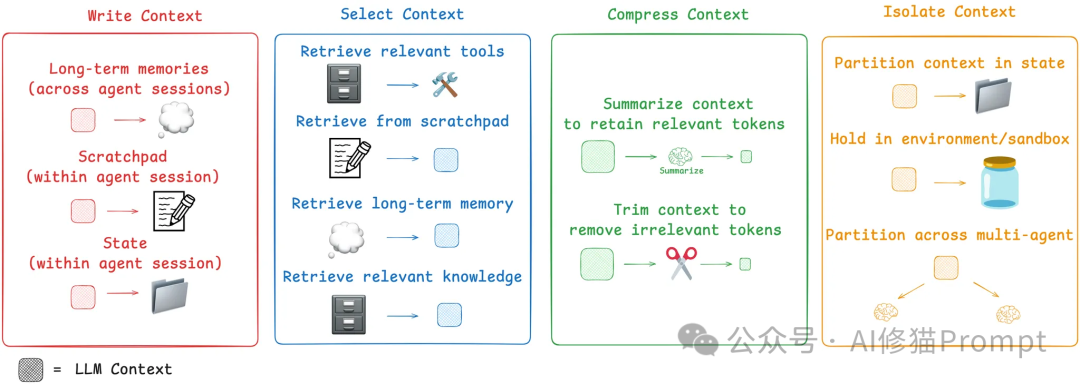
认知科学基础:四大认知原理
Write策略的深层基础来源于认知科学对人类思维结构的研究。基于认知模式理论,有效的上下文撰写必须遵循四个基本认知原理:
1. 分解性(Decomposability):问题结构化的艺术
2. 组合性(Composability):模块化思维的体现
3. 适应性(Adaptability):上下文的情境敏感性
4. 可验证性(Verifiability):推理透明化的要求
Schema驱动的系统化撰写方法
基于设计模式理论的抽象原则,Context Engineering采用Schema驱动的方法,将成功的设计模式编码为可重用的模板:
# minimal_context.yaml 核心结构
metadata:
token_budget:800# 预算约束
system:
role:"assistant"
constraints: ["准确性", "简洁性", "承认不确定性"]
memory:
max_turns:3
pruning_strategy:"drop_oldest"
evaluation:
metrics: ["相关性", "简洁性", "准确性"]
# 原子级基准测试
atomic_results = []
for prompt_variant in ["简短版", "详细版", "约束版"]:
result = measure_prompt_effectiveness(prompt_variant)
atomic_results.append(result)
# 发现:详细约束版本通常比简短版高30%效果
渐进式构建方法论: 不同于传统的"一次性完美"方法,Context Engineering采用迭代优化策略:
关键洞察:不要试图一次性写出完美上下文,而要建立撰写→测量→改进的快速反馈循环。项目中的01_min_prompt.py展示了如何从单句指令发展为multi-layered上下文的完整过程。
传统方法把上下文当作static内容,但Select策略的核心是动态信息检索。RAG(Retrieval-Augmented Generation)不只是"搜索+生成",而是智能上下文组装的艺术。关于RAG的文章我介绍过非常多,具体您可以看看,《动态数据太折磨人!静态RAG搞不定,就试下ZEP,让Agent调用实时知识图谱。》《搞RAG开发,听都没听说过Embedding模型排名,快看下MMTEB嵌入基准 | ICLR2025》以后我也会同步到ima知识库:“AI修猫Prompt-上下文工程” 中,作为上下文工程体系的一部分。
信息论基础:表示与检索的数学原理
Select策略的理论基础源于信息论和检索理论。有效的信息选择必须在四个维度上进行优化:
1. 表示优化(Representation):语义空间的构建
2. 分块策略(Chunking):信息颗粒度的权衡
3. 索引结构(Indexing):搜索效率的系统设计
4. 查询转换(Query Transformation):意图理解的桥梁
Token经济学:稀缺资源的最优配置
Compress策略的核心是Token经济学,如何在有限的上下文窗口中实现信息价值的最大化。这涉及微观经济学的资源配置理论:
Token价值评估模型:
Token价值 = (相关性 × 特异性 × 独特性) ÷ Token成本
其中:
- 相关性:信息与任务目标的直接关联度
- 特异性:信息的精确度和详细程度
- 独特性:模型难以从其他信息推断的程度
- Token成本:该信息占用的token数量
信息密度优化的层次策略
基于信息论的熵最小化原理,Context Engineering采用多层次的压缩策略:
1. 语法层压缩:结构优化
2. 语义层压缩:概念抽象
3. 语用层压缩:上下文优化
记忆系统的压缩策略
细胞级Context Engineering的核心是intelligent memory management:
memory_strategies = {
"sliding_window": "保留最近3轮完整对话",
"summarization": "将旧对话压缩为structured summaries",
"key_value_storage": "提取重要事实存储为KV pairs",
"priority_pruning": "基于重要性score删除内容"
}
每种策略都有其适用场景。客服场景适合key-value存储,创意写作适合summarization,技术支持适合priority pruning。
语义场的信息压缩
最先进的压缩技术来自neural field theory。不是逐个处理tokens,而是在semantic space中进行压缩:
# 语义场压缩原理
def field_based_compression(context_field):
# 1. 识别强吸引子(重要概念)
attractors = identify_strong_attractors(context_field)
# 2. 保留高共振模式
resonant_patterns = extract_resonant_patterns(context_field)
# 3. 压缩弱相关信息
compressed_field = compress_weak_signals(context_field)
return reconstruct_context(attractors, resonant_patterns, compressed_field)
系统论基础:关注点分离的设计哲学
Isolate策略的核心是separation of concerns。复杂任务不应该由单一上下文处理,而是分解为specialized components,基于系统论的模块化设计原理,实现复杂系统的有效管理。核心思想是通过边界定义、接口标准化和职责分离来降低系统复杂度。
模块化设计的四个层次:
1. 组件隔离(Component Isolation)
2. 状态隔离(State Isolation)
3. 错误隔离(Error Isolation)
4. 资源隔离(Resource Isolation)
神经场的边界动力学
基于接口隔离原则,Context Engineering引入协议Shell概念,为每个处理单元定义标准化的交互界面,在最前沿的Isolate实现中,项目使用neural field boundary dynamics来实现intelligent isolation。不同的语义区域通过可调节的边界进行隔离:
# 场边界管理示例
classFieldBoundaryManager:
def__init__(self, permeability=0.7, isolation_strength=0.8):
self.permeability = permeability # 边界通透性
self.isolation_strength = isolation_strength # 隔离强度
self.field_zones = {} # 不同的语义区域
defcreate_isolation_zone(self, zone_name, patterns, isolation_level):
"""创建隔离的语义区域"""
self.field_zones[zone_name] = {
"patterns": patterns,
"isolation_level": isolation_level,
"resonance_threshold": self.calculate_threshold(isolation_level)
}
defmeasure_cross_zone_interference(self, zone_a, zone_b):
"""测量不同区域间的相互干扰"""
returnself.field_resonance_measurer.measure_resonance(
self.field_zones[zone_a]["patterns"],
self.field_zones[zone_b]["patterns"]
)
这种approach的关键优势是dynamic isolation,隔离强度可以根据任务需求动态调整,既保证组件独立性,又允许必要的信息流动。
策略间的相互增强机制
四大策略不是孤立运作的,而是形成了一个相互增强的生态系统:
Write ⟷ Select协同:
Select ⟷ Compress协同:
Compress ⟷ Isolate协同:
Write ⟷ Isolate协同:
质量保证:评估驱动的持续优化
基于评估方法论的四大基础,可测量性、代表性、可重复性、可操作性,Context Engineering建立了完整的质量保证体系:
质量评估的多维框架:
┌─────────────────────────────────────────────┐
│ 功能质量:准确性、完整性、一致性 │
│ 性能质量:延迟、吞吐量、资源利用率 │
│ 语义质量:连贯性、相关性、合理性 │
│ 体验质量:可理解性、可用性、可靠性 │
└─────────────────────────────────────────────┘
这种多维度的质量评估不仅确保了每个策略的有效性,更重要的是验证了整体系统的协同效果,实现了从局部优化到全局最优的跃升。
关键洞察:Context Engineering的真正价值不在于任何单一策略的技术细节,而在于四大策略形成的有机整体。这种整体性设计使得AI系统能够在认知深度、信息效率、系统稳定性和用户体验等多个维度同时达到最优,实现了从简单工具到智能伙伴的根本性转变。
关键洞察:Context Engineering的真正价值不在于任何单一策略的技术细节,而在于四大策略形成的有机整体。这种整体性设计使得AI系统能够在认知深度、信息效率、系统稳定性和用户体验等多个维度同时达到最优,实现了从简单工具到智能伙伴的根本性转变。这也是为什么说Prompt Engineering只是Context Engineering的一部分,跟造不造新词没关系。
不同的应用场景需要不同的策略组合。以下是实用的决策指南:
应用场景 | Write重点 | Select重点 | Compress重点 | Isolate重点
---------|-----------|------------|-------------|-------------
简单问答 | 原子级模板 | 基础RAG | 滑动窗口 | 单组件处理
复杂分析 | Schema驱动 | 混合RAG | 语义场压缩 | 器官级分工
创意生成 | 分形结构 | 动态示例选择 | 模式抽象 | 反馈循环隔离
客服系统 | 结构化模板 | 知识库检索 | KV存储 | 专业化流程
技术支持 | 递归schema | 优先级检索 | 层次摘要 | 状态机隔离
实用建议:从您当前的pain points开始。如果主要问题是inconsistency,重点关注Write策略;如果是irrelevance,focus on Select;如果是cost,emphasize Compress;如果是complexity,prioritize Isolate。
企业级Context Engineering的成功不在于技术细节,而在于三个根本性的战略转变:
1. 从静态到动态的系统架构
2. 从单点优化到全链路质量保证
3. 从技术工具到组织能力
观察领先企业的部署实践,成功的Context Engineering都遵循"三层金字塔"模式:
关键成功因素:不是技术的先进性,而是三层之间的无缝集成和数据一致性。那些成功的企业级AI助手(如金融顾问机器人、法律文档助手)都实现了从底层知识到顶层交互的端到端Context Engineering。
Context-Engineering项目中最令人兴奋的概念之一是"递归涌现",AI系统能够自主优化自己的上下文结构。想象一下,您的AI系统不仅能完成任务,还能根据反馈自动调整自己的思维模式和知识结构。这不是科幻小说,项目中已经提供了初步的实现框架。您可以看下《!离AGI更近了!!0.31元运行谷歌的AlphaEvolve和UBC的DGM「达尔文-哥德尔机」?》
随着Context Engineering的发展,AI系统的角色正在从"工具"向"合作伙伴"转变。具备了记忆、学习、自我改进能力的AI系统,能够与人类形成真正的协作关系。这种转变将彻底改变我们对AI应用的认知和设计模式。
如果您正在开发AI产品,建议您先评估现有系统的上下文设计。问问自己:我的AI系统有记忆能力吗?能够处理多步骤任务吗?有系统化的质量监控吗?大部分现有系统在这些方面都有改进空间。关于记忆感兴趣您可以看下这篇G-Memory《Agent不长记性咋整?试试G-Memory,可进化的有组织“集体大脑”》
Context-Engineering项目提供了完整的学习路径,但您不必从头开始。根据您的具体需求,可以直接使用相应的模板和工具。比如如果您需要改进chatbot的一致性,可以直接使用细胞级的记忆管理模板;如果您要处理复杂的分析任务,可以考虑器官级的多步骤工作流。
没有测量就没有改进。在应用任何Context Engineering技术之前,先建立基准测试和评估体系。这样您才能量化改进效果,也才能持续优化系统性能。
Context Engineering不只是一个新的技术方向,它代表了AI开发思维的根本转变。从关注单个提示词到设计整个信息生态系统,从静态交互到动态进化,从工具使用到系统架构。这种转变的意义不亚于从汇编语言到高级编程语言的跨越。
作为AI产品的开发者,您站在了这个转变的关键节点上。Context Engineering为您提供了从提示词工程师进化为AI架构师的完整路径。这不只是技术能力的提升,更是职业发展的重大机遇。
现在的问题不是要不要学习Context Engineering,而是您准备好迎接这场技术变革了吗?最后,我的ima知识库:“AI修猫Prompt-上下文工程” 会持续更新Context体系的内容,包括我过去写的一些文章,欢迎你来和我交流!
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
