# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文介绍并开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程中,模型能够从所有先前的视图中提取有效的引导信息,从而增强多视图的一致性。
MVAR 拉近了纯自回归方法与最先进的基于扩散的多视图图像生成方法的生成图像质量,并成为能够处理同时多模态条件的多视图图像生成模型。

推理代码、权重、渲染的 GSO 及其配套的 Prompt 已全部开源。
根据人工指令生成多视图图像对于 3D 内容创作至关重要。主要挑战在于如何在多视图之间保持一致性,以及如何在不同条件下有效地合成形状和纹理。此前的工作主要使用 Diffusion 模型中自带的多视角一致性先验,促进多视角一致图像生成。但是 Diffusion 模型存在一些先天劣势:
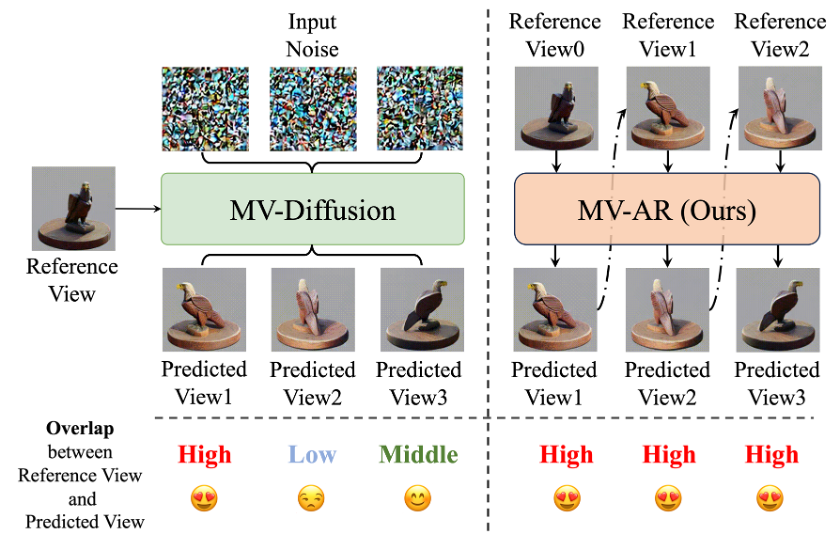
如上图左所示,当使用 Diffusion 模型从相隔较远的视角合成图像时,参考图像和目标图像之间的重叠度会显著降低,从而削弱了参考引导的有效性。
在极端情况下,例如从前视角生成后视角图像,由于重叠纹理极少,视觉参考信息几乎可以忽略不计。这种有限的参考信息可能会导致模型生成的多视角图像不够一致。
为了解决这一局限性,我们提出采用自回归 (AutoRegressive, AR) 生成方法进行多视图图像生成。
如上图右所示,在基于 AR 的生成中,模型利用前 n-1 个视图的信息作为生成第 n 个视图的条件,从而允许模型利用先前生成的视图的信息。在从前视图参考生成后视图的场景中,AR 生成模型会从先前的视图中提取足够且相关的参考。
值得注意的是,AR 生成过程与人类观察 3D 物体的方式高度一致。人类也是按照一个特定且连续的路径观察物体的多个视角,而非如 Diffusion 一样同时观察多个视角。
受此概念的启发,我们提出了多视图自回归 (MVAR) 模型。
MVAR 的主要目的是探究 AR 形式(此处的 AR 是狭义上的 AR 模型,仅仅指代 next token prediction 这一范式)的生成方法在多视角生成问题中的优势、劣势(及其对应的解决方案)。
我们将首先简单介绍什么是基于自回归的图像生成。
前置知识:什么是 AR 生成?

多视角图像生成中的AR
多视角情况下,由于存在多张图象,其相对于一般的 2D 图像多出了一个维度,这一维度可以被简单的理解成「时间」维度。
与视频不同,视频的不同帧之间有固定的时序关系,多视角图像之间并没有固定的时序关系,我们可以从很多条不同的时序轨迹去合成多视角图像。这一问题我们将在后续讨论。
于是,我们可将上式进行简单的扩展,使得 AR 能够适配多视角图像生成:
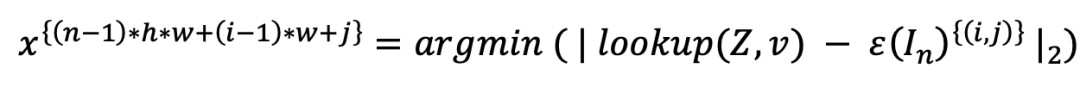
其中, n 代表第 n 个视角。
AR模型生成多视角图像有何问题
多视图生成的多条件控制、有限的训练数据,为 AR 在多视角图像任务的应用带来了许多阻碍。本博文简要介绍了其中两点:
MVAR给出的解决方案
我们分别针对这些问题给出了特定的解决方案。
多模态条件嵌入网络架构:文本、相机位姿、图像、几何。
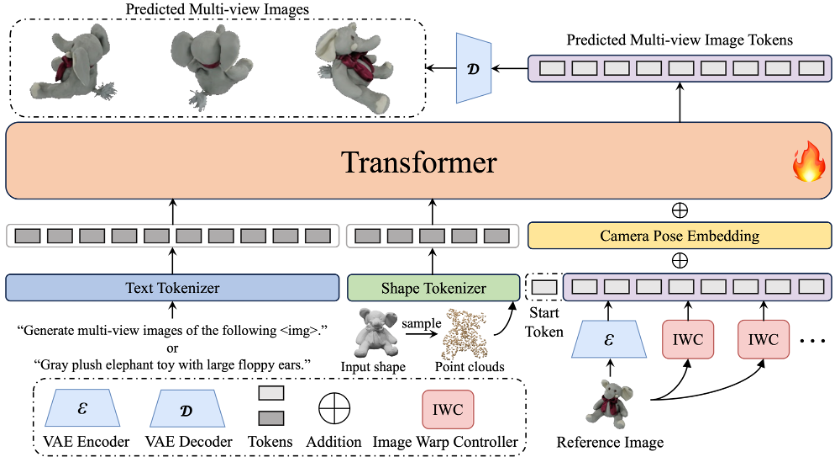
我们通过一些架构设计解决多模态条件嵌入,并试图避免简单的 in-context 条件注入形式可能带来的多模态塌缩问题。MVAR 的具体的网络架构如上图所示,其基础模型架构参考了 LLaMa;对于不同的模态,我们使用的条件注入方法整理如下:
以上条件注入结构设计遵从以下核心原则:
1.与输出能大致逐像素匹配的(如:普朗克编码后的相机位姿、参考图像、深度图),使用逐像素加法进行条件注入;
2.完全不能逐像素匹配的(如:文本、几何),使用 in-context 条件注入。

值得注意的是,相机位姿与参考图像的条件在 token 维度存在错位:
数据增强

由于 self attention 和 FFN 都具有置换等变性。因此,输入序列顺序的变化将导致模型中间特征序列顺序的相应变化。为了确保辅助条件(例如相机姿态和参考图像)能够有效地引导模型按照预定顺序生成图像,必须重新排列这些条件。这种重新排序将确保条件序列与输入序列的序列对齐。
我们认为 ShufV 在增广有限的高质量数据问题的同时,有助于缓解多模态条件控制中的部分问题:
AR 模型难以利用连续视图和当前视图之间的重叠条件。
使用 ShufV 进行数据增强时,视图的顺序不是固定的。假设输入序列 x 中存在两个视图 A 和 B。ShufV 使 MVAR 能够在训练阶段获得从视图 A 到视图 B 以及 视图 B 到视图 A 的转换。这允许模型利用当前视图和其他视图之间的重叠条件并有效地使用它们。
渐进式学习
最后,我们使用渐进式学习,将模型从仅接受文本条件的 text to multi-view image (t2mv) 模型泛化到 any to multi-view image (x2mv) 模型。
在 x2mv 模型的训练过程中,文本条件会被随机丢弃,而其他条件则会随机组合。当文本提示被丢弃时,它会被替换为与目标图像无关的语句。例如,可以使用诸如 「Generate multi-view images of the following <img>」 之类的 prompt 。在这种情况下,「<img>」 表示将在文本之后组合参考图像。如果后续元素是几何形状,则将 「<img>」 替换为 「<shape>」。这种渐进式学习使模型能够受到训练期间引入的新条件的影响,同时保持对文本提示的一定程度的遵循。
MVAR 拉近了基于 AR 的多视角生成模型与现有的 Diffusion 模型的差距,并展示出更强的指令遵从与多视角一致性。

图生多视角图像
与一些先进的基于 Diffusion 的方法的数值指标比较如下:
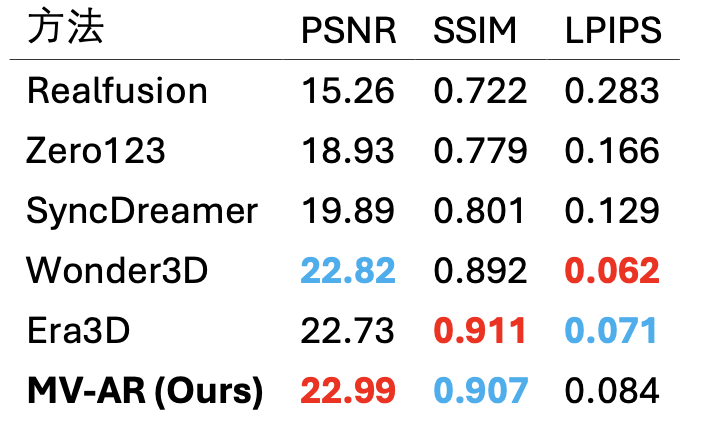
其中,红色表示最优、蓝色表示次优。
MVAR 的表现上有着最高的PSNR、次优的SSIM,但在LPIPS这一感知指标上仍有些逊色。更高的PSNR意味着生成的视角与对应的GT能更好的进行颜色、形状、物体位置上的对齐;略低的 LPIPS 意味着 MVAR 在实际图像质量上可能相对于Diffusion略逊一筹。
我认为 MVAR 生成的图像感知质量较差的原因是因为 MVAR 使用的基础模型 LLamaGen 相比 Diffusion-based 方法使用的基础模型 SD 系列要差一些。不过随着现有基于 AR 的图像生成基础模型的发展,我相信基于 AR 的多视角生成的感知质量将会很快追上并超过已有 Diffusion-based 方法。

文生多视角图像

文+几何生多视角图像(纹理生成)
更多结果欢迎大家在 arxiv 查看,或在 github 上下载代码与权重自行生成。
文章来自于微信公众号“机器之心”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
