# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Tokenization,一直是实现真正端到端语言模型的最后一个障碍。
我们终于摆脱 tokenization 了吗?
答案是:可能性无限大。
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。
「这一研究预示着 Tokenizers 正在退场,智能字节分块(Smart Byte Chunks)开始登场。或许无需 Tokenizer 训练的时代真的要来了 —— 可能性无限大。」X 知名博主 Rohan Paul 表示道。

现阶段,Tokenization 仍然是语言模型和其他顺序数据不可或缺的组成部分,因为它能够压缩和缩短序列。然而 Tokenization 存在许多缺点,如可解释性差,在处理复杂语言(如中文、代码、DNA 序列)时性能下降等。
迄今为止,尚未有任何端到端的无 tokenizer 模型在计算预算相匹配的情况下超越基于 tokenizer 的语言模型的表现。最近,已经有研究开始致力于在自回归序列模型中突破 Tokenization 限制。
在此背景下,来自 CMU、 Cartesia AI 等机构的研究者提出了一系列新技术,通过动态分块机制实现内容与上下文自适应的分割策略,该机制可与模型其他部分联合学习。将这一机制融入显式分层网络(H-Net)后,原本隐含分层的「tokenization–LM–detokenization」流程可被完全端到端的单一模型取代。
在计算资源和数据量对等的条件下,仅采用单层字节级分层的 H-Net 模型,其表现已优于基于 BPE token 的强 Transformer 语言模型。通过多级分层迭代建模不同抽象层级,模型性能得到进一步提升 —— 这不仅展现出更优的数据规模效应,更能媲美两倍规模的基于 token 的 Transformer 模型。
在英语预训练中,H-Net 展现出显著增强的字符级鲁棒性,并能定性学习有意义的、数据依赖的分块策略,全程无需启发式规则或显式监督。
最后,在 tokenization 启发式方法效果较弱的语言和模态(如中文、代码或 DNA 序列)中,H-Net 相比 tokenization 流程的优势进一步扩大(数据效率较基线提升近 4 倍),这证明了真正端到端模型从未经处理数据中实现更优学习和扩展的潜力。

论文地址:https://arxiv.org/pdf/2507.07955v1
本文提出了一种端到端的分层网络(H-Net),通过递归、数据依赖的动态分块(DC,dynamic chunking)过程压缩原始数据(见图 1)。H-Net 在保持与 token 化流程相同效率的同时,通过用从数据中学习的内容感知和上下文依赖的分割替代手工启发式方法,显著提高了建模能力。
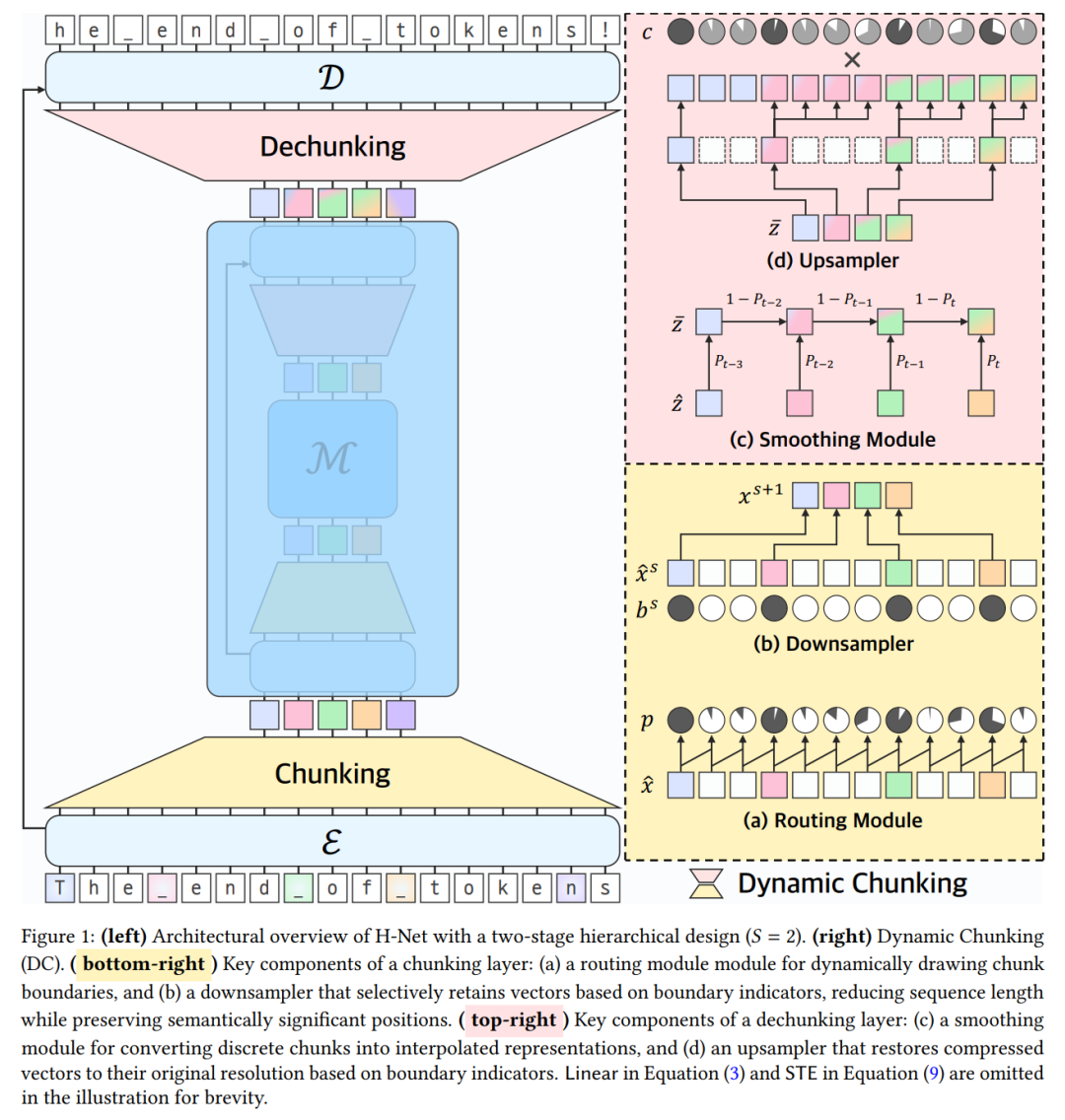
分层处理
H-Net 采用了分层架构,其工作流程分为三步:
这种设计形成了天然的认知分层 —— 外层捕捉细粒度的模式,内层处理抽象概念。
关键是,主网络包含了大部分参数,并且可以适配任何标准架构,例如 Transformer 或状态空间模型(SSM)。
动态分块
H-Net 的核心是动态分块(DC)机制,它位于主网络与编码器 / 解码器网络之间,用于学习如何分割数据,同时使用标准的可微优化方法。DC 由两种互补的新技术组成:
(i) 路由模块,通过相似度评分预测相邻元素之间的边界;
(ii) 平滑模块,使用路由器的输出插值表示,通过减弱不确定边界的影响,显著提高学习能力。
通过将这些技术与一个新的辅助损失函数结合,并利用现代基于梯度的离散选择学习技术,DC 使得 H-Net 能够以完全端到端的方式学习如何压缩数据。
信号传播
本文还引入了几种架构和训练技术,以提高端到端优化过程中的稳定性和可扩展性。这些技术包括:(i) 精心布置的投影层和归一化层,以平衡交互子网络之间的信号传播;(ii) 根据每层的维度和有效批次大小调整其优化参数。
总的来说,H-Net 学习了与主干网络联合优化的分割策略,基于上下文信息动态地将输入向量压缩成有意义的数据块。
H-Net 代表了第一个真正的端到端、无 tokenizer 的语言模型:通过一个动态分块阶段,字节级的 H-Net 在超过 10 亿参数的规模下,达到了与强大的 BPE token 化 Transformer 相当的困惑度和下游性能。
从经验上看,动态分块模块自然地将数据压缩到与 BPE tokenizer 相似的分辨率(每块 4.5-5 字节),并且在没有任何外部监督或启发式方法的情况下,定性地学习到有意义的边界。
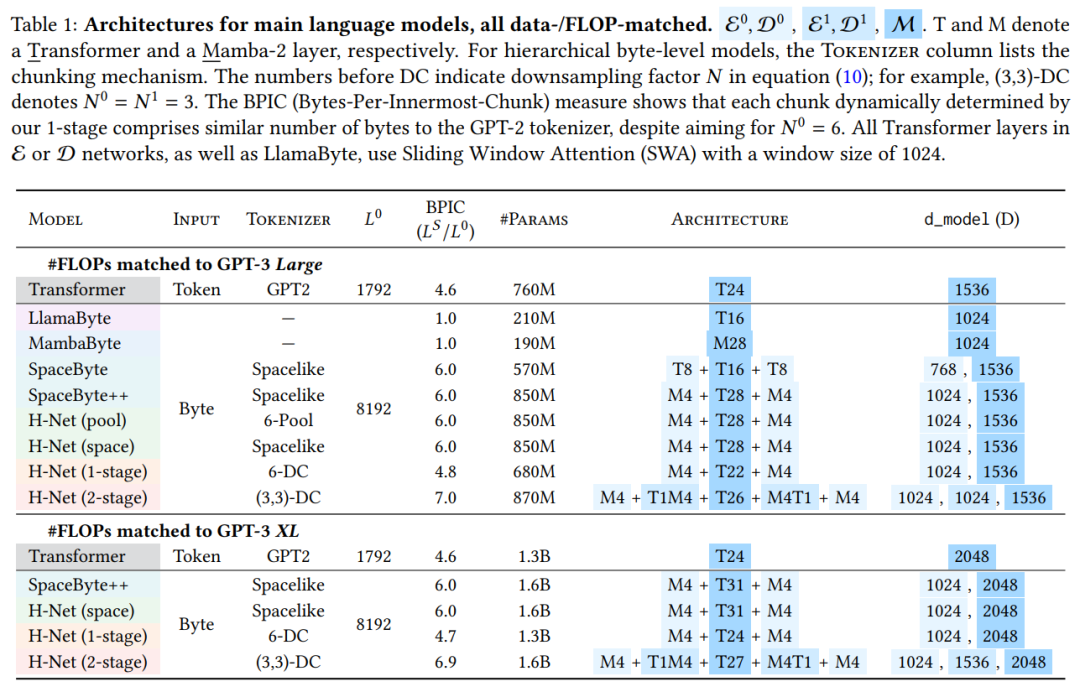
实验中,本文采用的主要语言模型架构如下所示,如 MambaByte 是使用纯 Mamba-2 层的各向同性模型。
Training Curves. Figure 3 presents validation BPB metrics throughout training for both Large and XL model scales
训练曲线。图 3 显示了 Large 和 XL 规模模型在整个训练过程中的验证 BPB 指标。
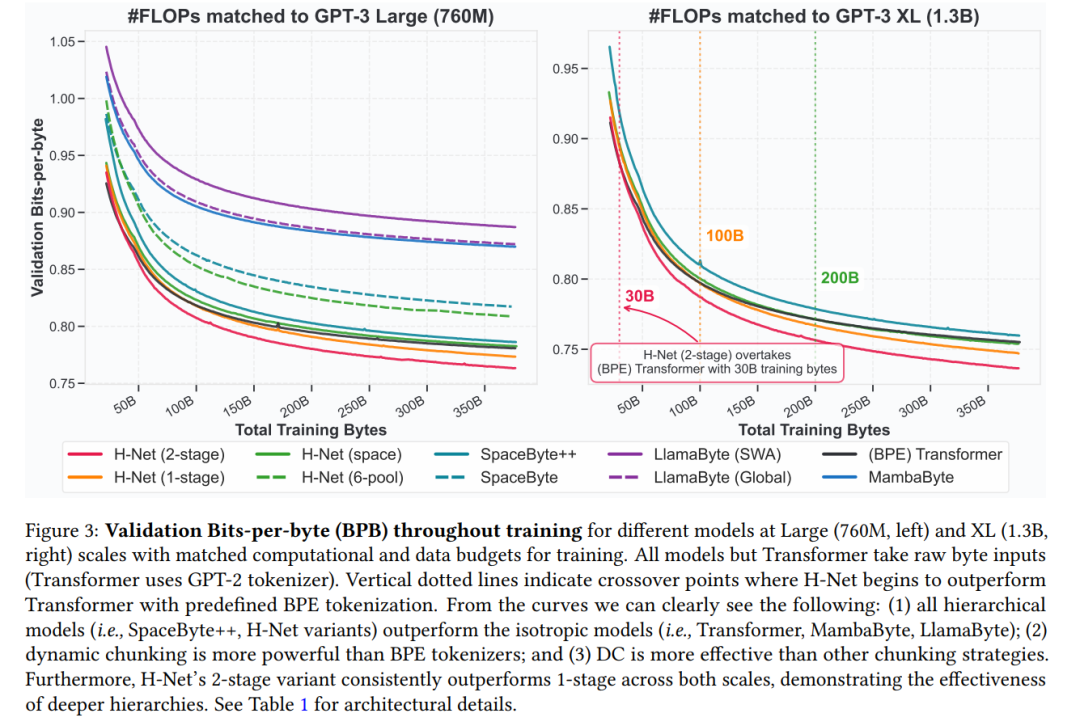
在较大规模上,本文注意到:
所有各向同性模型在性能上都远逊色于分层模型。在这些模型中,MambaByte 明显优于 LlamaByte。
SpaceByte 明显逊色于 SpaceByte++,这一结果验证了本文在外部网络中使用 Mamba 的有效性。SpaceByte++ 又比 H-Net(space)差,表明本文提出的改进信号传播技术的有效性。
H-Net(space)是一个非常强大的模型,达到了与 BPE Transformer 相当的性能,验证了数据依赖的分块策略与精心设计的分层架构的效果。
表 2 展示了不同模型在多个下游基准测试上的零样本准确率。
SpaceByte++、H-Net(space)和 H-Net(1-stage)在大规模上与 BPE Transformer 的性能相似,在 XL 规模上稍微超越了 BPE Transformer。
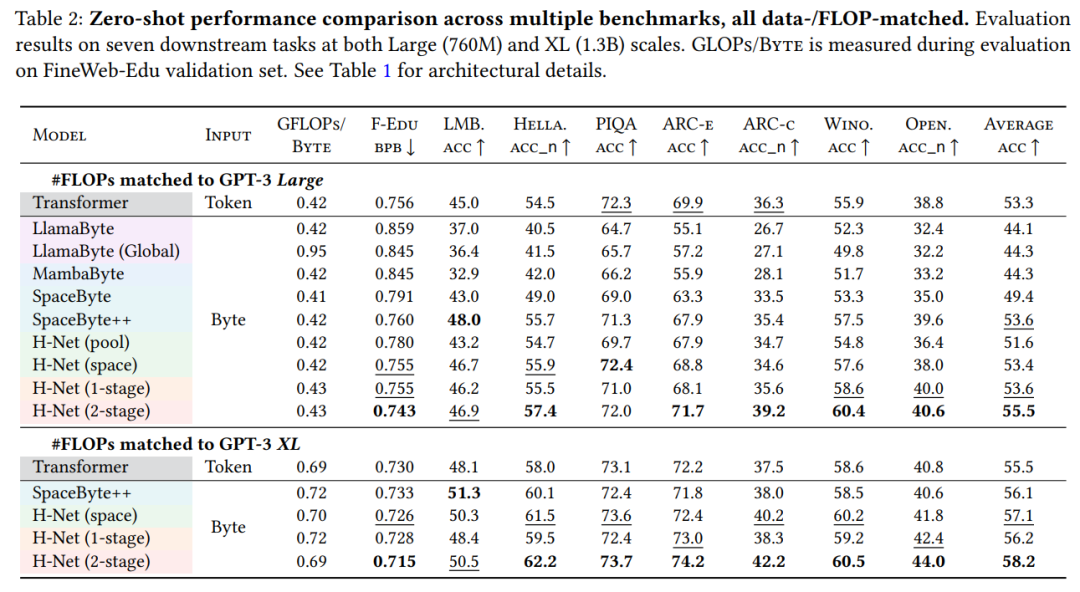
表 3 评估了模型在 HellaSwag 上的鲁棒性。与所有基准模型相比,H-Net(2-stage)显著提高的鲁棒性。
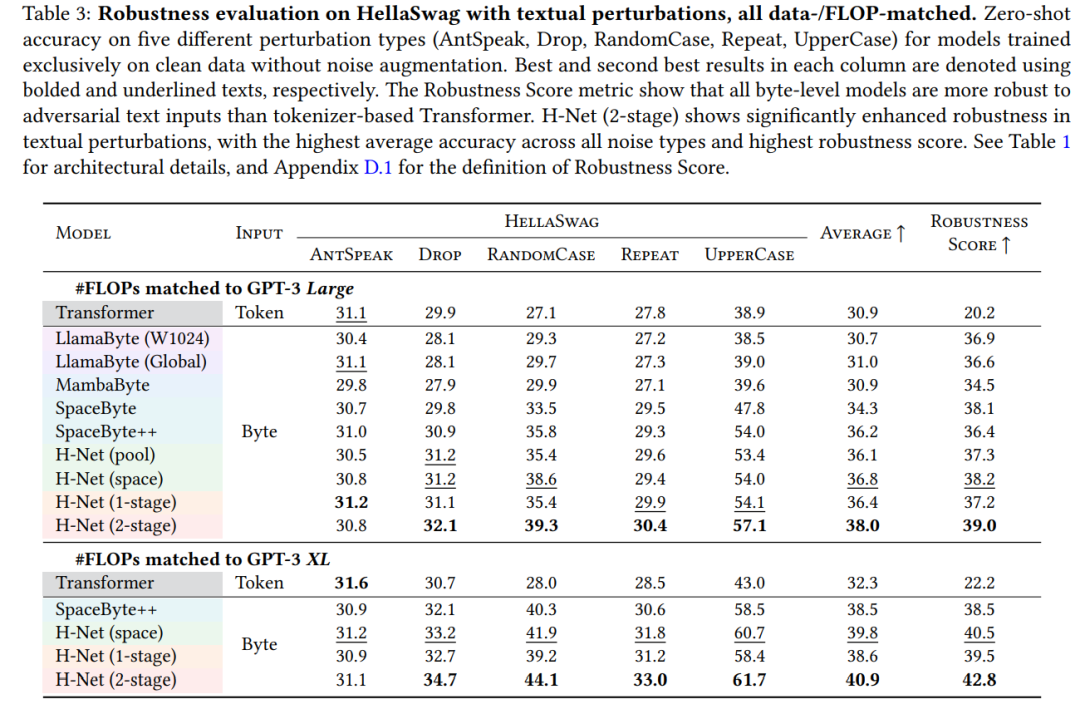
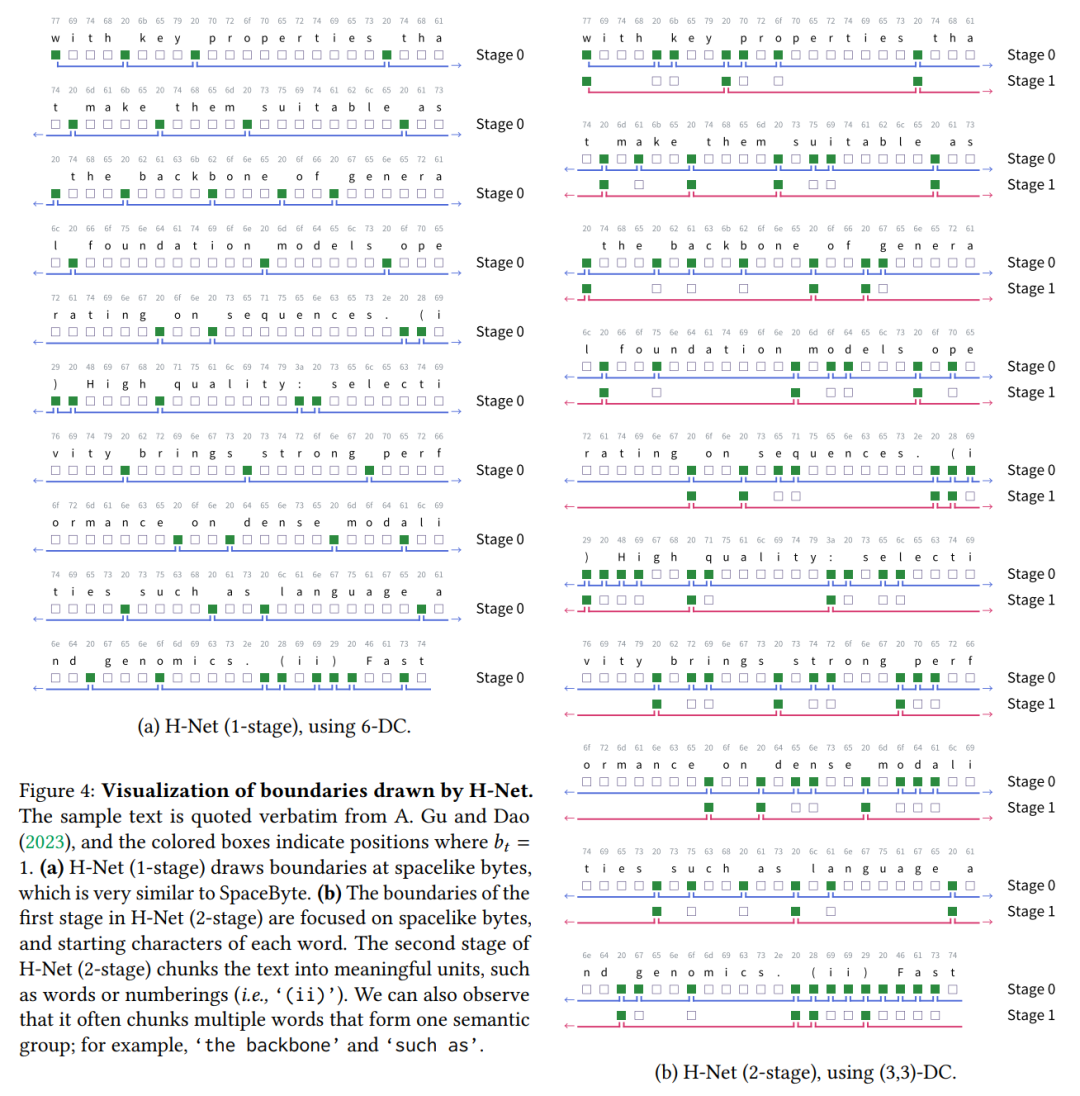
图 4 提供了 H-Net(1-stage)和 H-Net(2-stage)动态绘制的边界的可视化图。这些可视化提供了关于模型如何决定边界的几个重要见解。
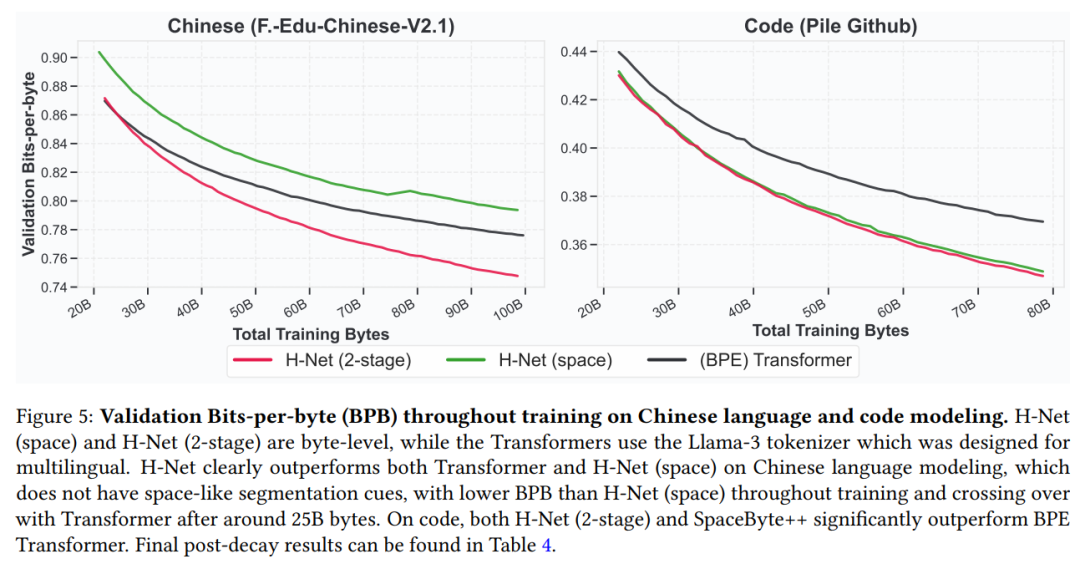
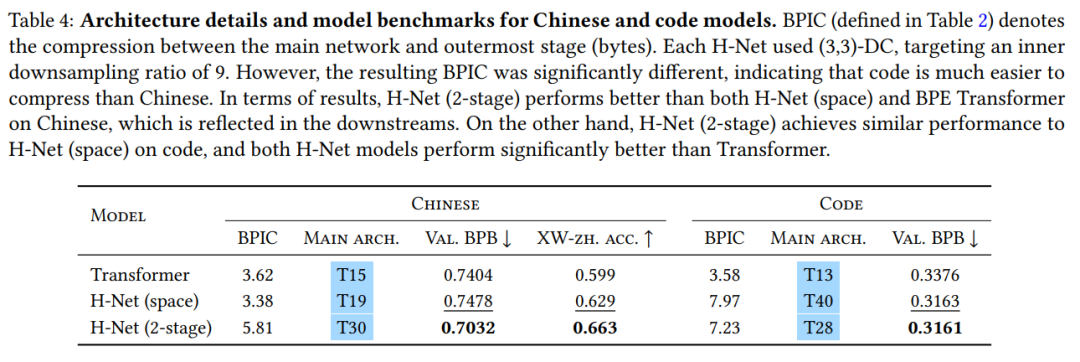
即使使用 Llama3 tokenizer,本文发现 H-Net(2-stage)在中文和代码处理上,比 BPE Transformer 和 H-Net(space)具有更好的扩展性(图 5),并且在衰退阶段后实现了更低的压缩率(表 4)。
之前的研究已经证明,SSM 在 DNA 序列建模上比 Transformer 表现更好。实验(表 5)也验证了这一点:即使换成 Mamba-2 作为主网络,SSM 的优势仍然存在。
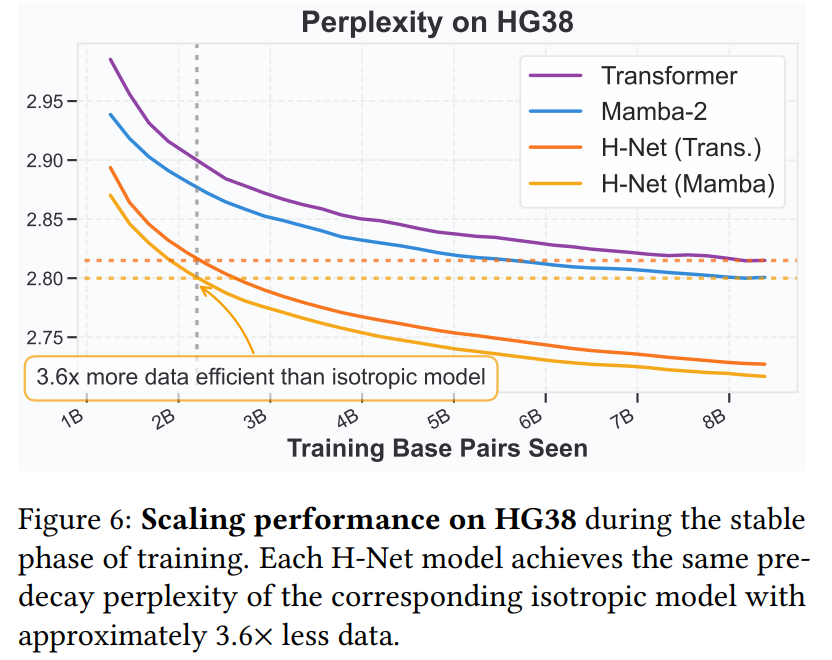
实际上,通过直接比较训练稳定阶段的困惑度曲线(图 6),本文发现 H-Net 模型在数据量仅为 3.6 倍的情况下,能够达到与各向同性模型相似的性能,这一发现适用于两种主网络架构的选择。
最后,Albert 还撰写了精彩的博客文章,介绍关于 H-Net 的幕后故事和精彩见解。感兴趣的读者可以前去阅读。
博客地址:https://goombalab.github.io/blog/2025/hnet-past/
文章来自于微信公众号“机器之心”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
