# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。这为多模态统一建模带来了机遇,也提出了一个核心挑战:如何将各种模态信号转化为 LLM 可处理的离散表示。
在这一背景下,Discrete Tokenization(离散化)逐渐成为关键方案。通过向量量化(Vector Quantization, VQ)等技术,高维连续输入可以被压缩为紧凑的离散 token,不仅实现高效存储与计算,还能与 LLM 原生的 token 机制无缝衔接,从而显著提升跨模态理解、推理与生成的能力。
尽管 Discrete Tokenization 在多模态 LLM 中扮演着日益重要的角色,现有研究却缺乏系统化的总结,研究者在方法选择、应用设计与优化方向上缺少统一参考。为此,本文团队发布了首个面向多模态 LLM 的 Discrete Tokenization 系统化综述,系统地梳理技术脉络,总结多模态场景下的实践、挑战与前沿研究方向,为该领域提供全面的技术地图。


此综述按照输入数据的模态与模态组合来组织内容:从早期的单模态与多模态 Tokenization 方法,到 LLM 结合下的单模态与多模态应用,逐步构建出清晰的技术全景。这种结构既反映了方法的演进路径,也方便读者快速定位自己关心的模态领域。
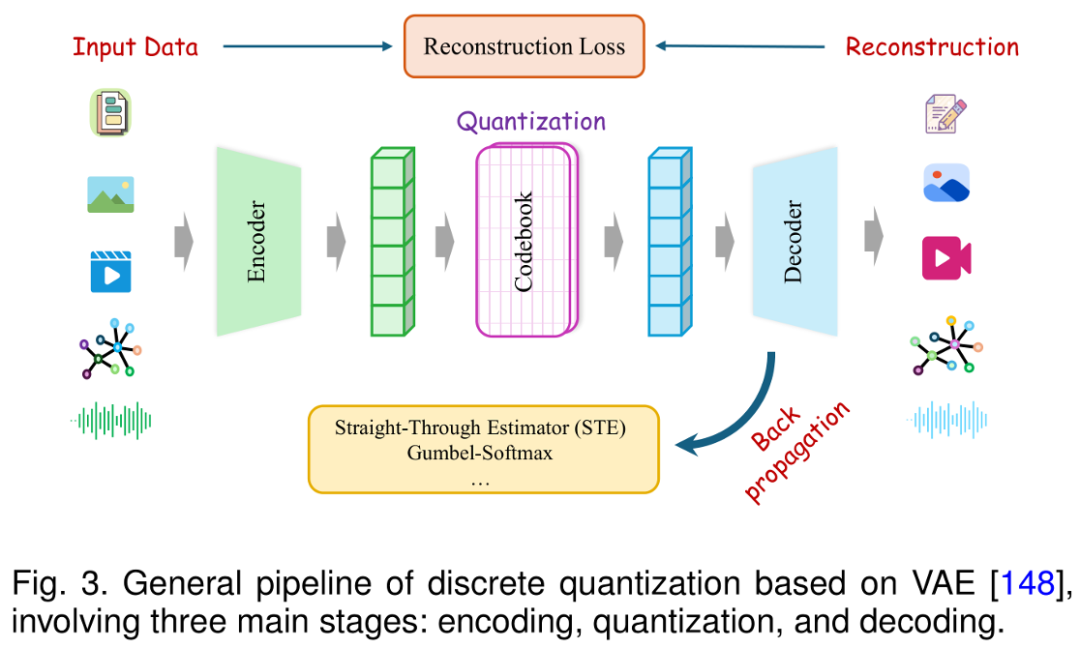
此综述首次系统性地整理了八类 Vector Quantization 方法,覆盖从经典方法到最新技术变体,并剖析了它们在码本构建、梯度传播、量化实现上的差异。
八类方法包括:
不同方法在编码器训练、梯度传递、量化精度等方面各具特点,适用于不同模态与任务场景。
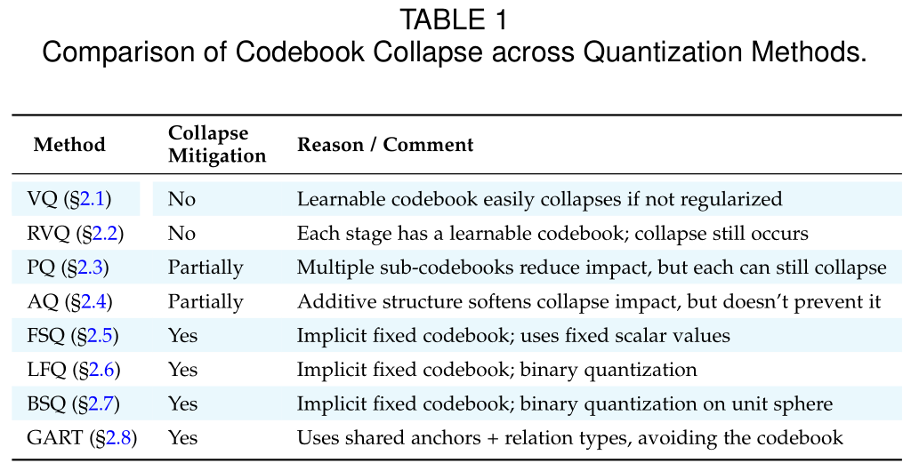
方法挑战:码本坍塌(Codebook Collapse)
在多种 VQ 方法实践中,码本坍塌是影响性能的核心问题之一。它指的是在训练过程中,码本的有效向量逐渐收敛到极少数几个,导致码本利用率下降、表示多样性不足。
常见解决思路包括:
缓解码本坍塌对于提升 Discrete Tokenization 在多模态 LLM 中的稳定性与泛化能力至关重要。
在 LLM 出现之前,Discrete Tokenization 已经在多个深度学习任务中得到广泛应用,涵盖单模态场景与多模态场景。在这一阶段,它的主要作用是实现高效表示、压缩以及不同模态间的对齐。典型应用包括:
这一阶段的实践奠定了 Discrete Tokenization 在后续 LLM 时代广泛应用的技术基础,并为跨模态对齐和统一处理提供了早期经验。
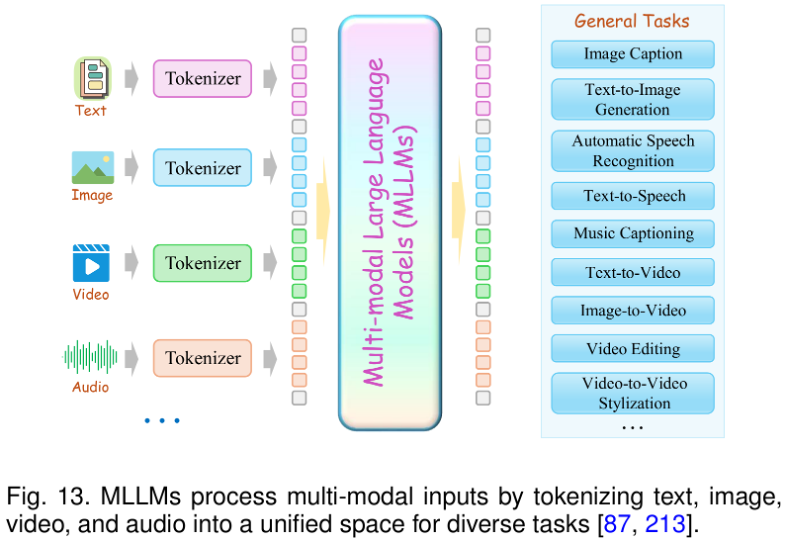
LLMs 在生成、理解、泛化等任务中展现了强大的能力,使其成为建模非文本模态的理想骨干。在单模态任务中,Discrete Tokenization 被广泛应用于图像、音频、图、动作以及推荐系统等领域,通过将非文本模态编码为 LLM 可读的 token,Discrete Tokenization 实现了与语言 token 在同一空间下的融合。这些离散 token 作为桥梁,使 LLM 能够完成多类下游任务:
通过 Discrete Tokenization,不同单模态的数据特征得以映射到 LLM 的词表空间中,统一进入模型处理框架,从而充分利用 LLM 强大的序列建模和泛化能力。
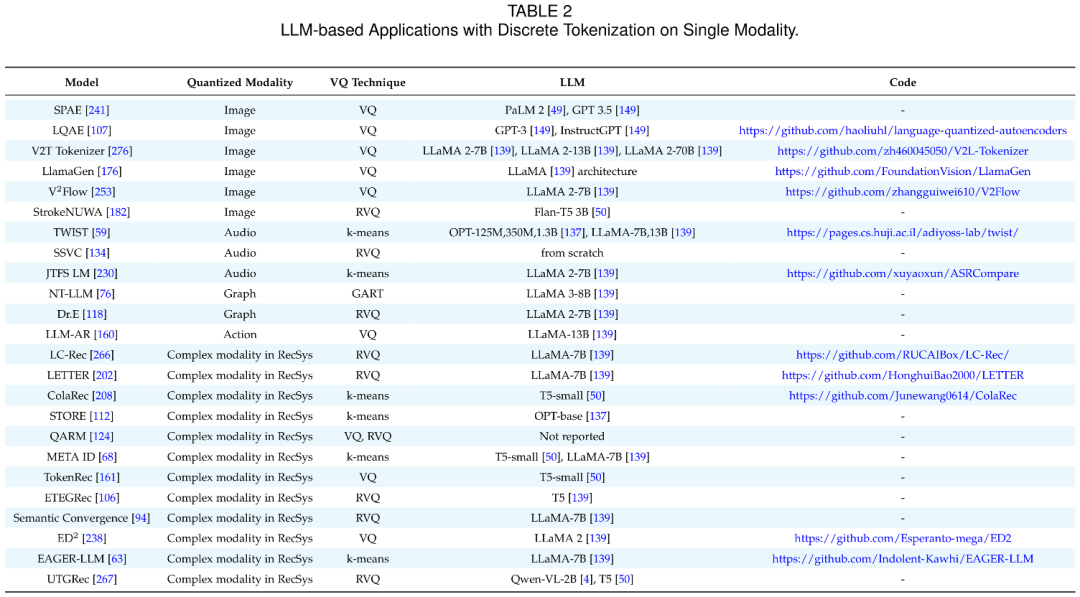
在多模态任务中,Discrete Tokenization 的作用尤为关键,它为不同模态之间建立了统一的语义桥梁,使模型能够在一致的 token 表示下处理复杂的多模态输入。
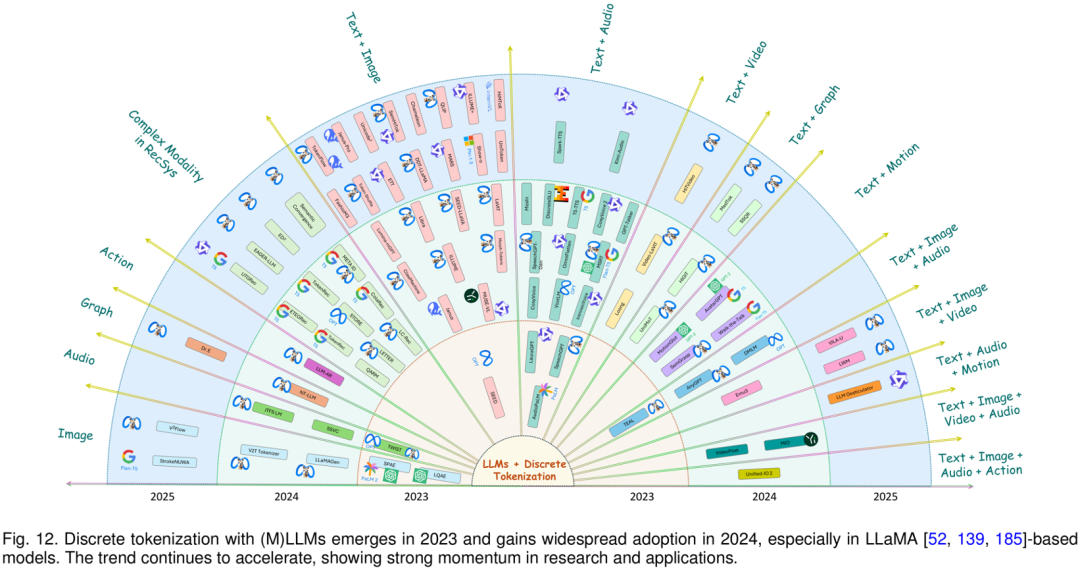
双模态融合
双模态组合起步于 2023 年,其中 Text + Image 是最活跃的方向,其次是 Text + Audio,随后扩展到 Text + Video、Text + Graph、Text + Motion。在这些任务中,各模态通过各自的 tokenizer 转换为离散 token,并映射到统一空间,从而支持图文描述、跨模态问答、语音合成、视频理解、动作生成等任务。
多模态融合
在三模态及以上的组合中,Discrete Tokenization 帮助更多模态在统一框架中协同工作,例如 Text + Image + Audio、Text + Image + Video、Text + Image + Audio + Action。这些组合在统一 token 空间中实现检索、生成、对话、理解等复杂任务。
统一 token 机制使得模型无需为每个模态单独定制架构,而能够在单一框架内自然扩展到更多模态组合,大幅提升泛化性与扩展性。
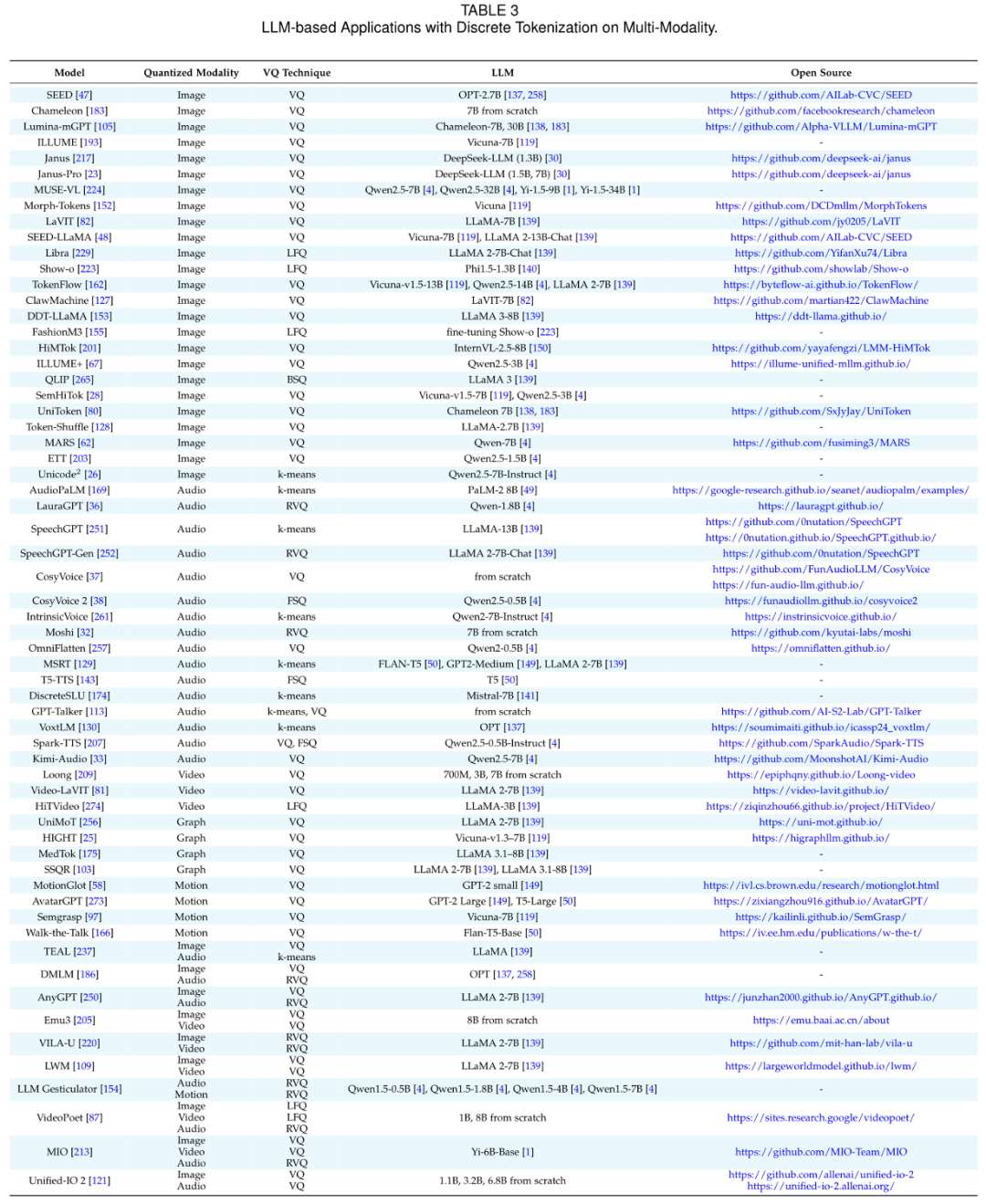
尽管已有显著进展,Discrete Tokenization 在多模态 LLM 中仍存在多方面挑战:
未来研究方向可以聚焦在:自适应量化、统一框架、生物启发式码本、跨模态泛化、可解释性提升等方面,推动离散化在多模态 LLM 中更高效、更通用地发展。
作为多模态 LLM 的底层桥梁,Discrete Tokenization 的重要性会随着模型能力边界的拓展而不断提升。此综述提供了首个全景化、系统化的离散化参考,不仅梳理了八类核心技术,还围绕输入数据的模态与模态组合构建了完整的应用全景,从单模态到双模态,再到多模态融合,形成了清晰的技术脉络。
这是首个以输入模态为主线构建内容结构的系统化综述,为研究者提供了按模态快速检索方法与应用的技术地图。这种组织方式不仅凸显方法演进的脉络,还为不同研究方向提供了清晰的切入路径,有望在推动理论创新的同时,加速实际落地与跨模态系统的发展。
文章来自于微信公众号“机器之心”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
