一句话概括,这篇论文堪称AI版的"精神分裂式"学习法,一个模型扮演魔鬼教练,另一个扮演受虐学生,结果居然双双进化了!(原论文题目见文末,点击阅读原文可直接跳转至原文链接, Published on arXiv on 07 Aug 2025, by Tencent AI Seattle Lab, Washington University in St. Louis, University of Maryland)
亲爱的读者们,沈公子的公众号agent🤖和base model升级到v3.0,今后公众号文章行文会更流畅,处理公式和符号也完全达到人类专家水准,会大幅减少出现错乱和显示异常的情况,提升阅读体验。enjoying :)
第一阶段:识别核心概念
论文的motivation分析
当前训练强大的大语言模型(LLM),就像是培养一个顶尖运动员,需要大量的、由专家(人类标注员)精心设计的训练计划和教材(高质量的标注数据)。这个过程存在几个根本性问题:
- 成本高昂且效率低下:制作这些高质量的数据集既费钱又费时,规模很难扩大。
- 人类能力的瓶颈:AI的学习内容被限制在人类能够创造和标注的数据范围内。如果我们希望AI具备超越人类的智能,那么它就不应该只学习人类“老师”教给它的东西。
- 对特定工具的依赖:一些所谓的“自学”方法,尤其在编程或数学领域,需要依赖外部的执行环境(如代码解释器)来判断答案是否正确。但对于更广泛的、开放式的推理问题,这种“裁判”并不存在。
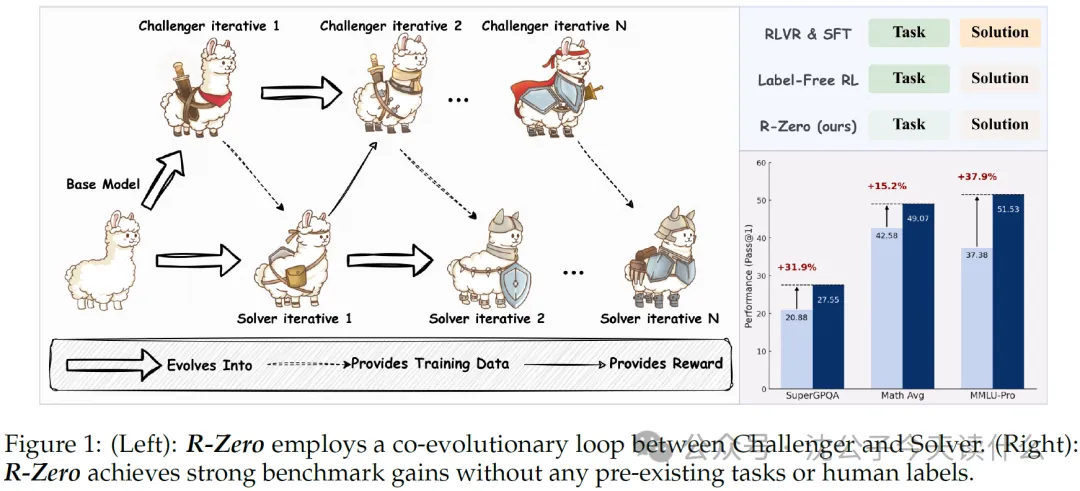
因此,作者的动机是:能否创造一个完全自给自足的系统,让LLM摆脱对人类数据和外部验证工具的依赖,通过自我驱动的方式生成训练任务并从中学习,实现能力的持续进化? 这就是R-Zero想要解决的核心问题。
论文主要贡献点分析
- R-Zero 框架:提出了一个完全自主的、从零数据开始的自进化框架。它不需要任何预先存在的问题集或人工标签。
- 双角色协同进化(Co-evolution):系统内部包含两个角色——“挑战者”(Challenger)和“解决者”(Solver)。它们从同一个基础模型初始化,然后通过相互作用共同进化。
- 不确定性驱动的课程生成:挑战者的核心任务是创造出对当前解决者来说“恰到好处”难度的题目。这种“恰到好处”是通过最大化解决者的“不确定性”来衡量的。
- 无监督的自我提升:解决者通过学习由挑战者生成的、经过筛选的难题来提升自己的能力,而答案的对错(伪标签)则通过自己多次回答的“多数投票”来决定。
- 挑战者-解决者循环:这是整个框架的架构核心。挑战者为解决者出题,解决者为挑战者提供奖励信号,形成一个闭环。
- 不确定性奖励(Uncertainty Reward):这是驱动挑战者进化的关键技术。当解决者对某个问题的回答正确率在50%左右时,它被认为是最不确定的,此时挑战者会获得最高的奖励。这个设计非常巧妙,它鼓励挑战者始终瞄准解决者能力的“前沿地带”(Zone of Proximal Development)。
- GRPO (Group Relative Policy Optimization):这是一种强化学习算法,被用于更新挑战者和解决者。它的特点是不需要一个独立的价值网络,而是通过比较一批产出(比如一批问题或一批答案)的相对好坏来进行优化,非常适合这种自生成数据的场景。
- 多数投票与过滤机制:这是解决者在没有外部裁判的情况下进行学习的基础。通过对自己生成问题的多次作答进行投票来产生“伪正确答案”,并过滤掉那些太简单或太难(即共识度过高或过低)的问题。
- 从零开始实现显著提升:最重大的意义在于,该方法证明了在完全没有外部数据的情况下,一个LLM可以通过自我博弈显著提升其在数学和通用推理任务上的能力。例如,Qwen3-4B-Base模型在数学基准上提升了6.49分。
- 知识泛化能力:通过自我生成数学问题进行训练,模型的能力提升并不仅限于数学领域,而是可以泛化到MMLU-Pro、SuperGPQA等通用推理基准测试上。这说明R-Zero学习到的不是特定领域的知识,而是更底层的、可迁移的推理能力。
- 与监督学习的协同效应:R-Zero不仅可以独立工作,还可以作为监督学习的“助推器”。经过R-Zero训练过的模型,再用少量有标签数据进行微调,其最终性能远超直接用这些数据进行微调的模型。这表明R-Zero构建了一个更好的能力基础。
理解难点识别
- 挑战者-解决者(Challenger-Solver)的协同进化机制:这是整个故事的主线。
- 不确定性奖励函数(Uncertainty Reward Function):这是整个系统的“发动机”,是创新的核心。
- GRPO算法的应用:这是实现模型更新的具体“工具”。
- 最具挑战性的部分是理解 “不确定性奖励” 的设计哲学和工作原理。为什么“让解决者感到困惑”反而能训练出更聪明的挑战者?为什么50%的成功率是最佳点?这背后的直觉和理论依据是什么?这与传统的“奖励正确答案”的思维模式完全不同,初读时可能会感到困惑。
- 我们将重点解释 “挑战者-解决者协同进化” 这一核心机制,特别是深入剖析其灵魂——“不确定性奖励” 是如何驱动整个系统运转的。
概念依赖关系
- 整个 R-Zero 框架 是建立在 挑战者-解决者协同进化 的基础之上的。
- 不确定性奖励 的计算,又依赖于当前 解决者 的表现。
- 解决者 的进化,则依赖于由 挑战者 生成并经过筛选的训练数据。
- GRPO 是将奖励信号转化为模型参数更新的执行者。
- 从 “挑战者-解决者协同进化” 这个宏观框架入手,然后迅速聚焦到其最独特、最关键的驱动力—— “不确定性奖励” 上。这是理解R-Zero“从零到一”魔法的关键。
第二阶段:深入解释核心概念
设计生活化比喻
想象一个场景:一位想成为顶尖数学竞赛选手的学生(小S),聘请了一位非常有创意的私人教练(王教练)。他们的目标是从零开始,冲击世界冠军,但手头没有任何现成的习题集。
- 王教练(挑战者)的工作不是去题库里找题,而是自己原创题目给小S做。
王教练如何知道自己出的题是好是坏呢?他有一个非常独特的评判标准:
- 如果一道题,小S每次都能轻松做对,说明题太简单了,小S没学到新东西。王教练认为这是失败的出题。
- 如果一道题,小S绞尽脑汁也完全做不出来,说明题太难了,超出了她目前的能力范围,她只会感到挫败,同样学不到东西。这也是失败的出题。
- 如果一道题,小S需要反复尝试,时而做对,时而做错,正确率在50%左右,这说明这道题正好处于小S的“能力边缘”。在这个区域,小S的思维被最大程度地调动,学习效率最高。王教练认为,能出出这样的题,才代表自己是顶级教练,他会给自己打一个高分。
于是,这个训练循环开始了:
1.教练出题:王教练凭自己当前的水平,设计一道新题。
2.学生解答:小S尝试解答这道题(比如用几种不同的思路解10次)。
3.教练评估:王教练观察小S的10次解答,发现她答对了5次。他非常高兴,因为这道题的难度“恰到好处”,于是他给自己这次出题的行为一个很高的“教练分”(奖励)。
4.教练进化:王教练不断总结经验,学习如何才能稳定地出出这种能让小S“一半对一半错”的题目。他的出题水平越来越高。
5.学生进化:小S则会复盘那些她费了很大劲才做对的题目,从中学习新的解题技巧,她的解题能力也越来越强。
6.水涨船高:随着小S变强,之前那些“恰到好处”的难题对她来说变得简单了。王教练为了继续获得高分,就必须设计出更难、更复杂的题目,来再次触及小S新的“能力边缘”。
就这样,教练和学生在一个“你追我赶”的动态中,实现了能力的共同飞跃,完全不需要一本外部的习题册。
建立比喻与实际技术的对应关系

深入技术细节
核心技术1:不确定性奖励 (Uncertainty Reward)

核心技术2:GRPO (Group Relative Policy Optimization)
Challenger 和 Solver 都用 GRPO 进行更新。我们以 Challenger 为例,它收到上面计算出的奖励后,如何利用它来提升自己呢?
GRPO 的关键一步是计算 优势值 (Advantage)。

将技术细节与比喻相互映射

- 比喻的局限性: 在我们的比喻中,我们假设王教练能准确知道小S的答案是否正确。在R-Zero中,“正确答案”是通过多数投票产生的。如果Solver模型能力很差,对一个问题的所有回答都是错的,那么多数投票选出的“伪标签”也必然是错的。论文通过过滤掉共识度极低(太难)的问题,在一定程度上缓解了这个问题,但这依然是该方法的一个内在挑战。
总结
- 核心联系:R-Zero 的 Challenger-Solver 协同进化 就像 教练与学生的共同成长。
- 如何帮助理解:这个比喻将抽象的强化学习过程,转化为一个目标明确、逻辑清晰的教育故事,让我们轻松地抓住了整个系统的核心驱动力。
- 关键数学原理总结:其最关键的数学原理——不确定性奖励,用比喻来说就是:一个好教练的价值,不体现在学生能轻松答对他出的所有题,而体现在他总能设计出让学生感到困惑、挣扎,并最终能突破自我的“能力边缘”问题。
第三阶段:详细说明流程步骤

第二步:挑战者训练阶段 (第 t 轮)
在这一阶段,目标是让挑战者 进化为更强的 。


第三步:解决者训练阶段 (第 t 轮)
在这一阶段,目标是让解决者 进化为更强的 。

第四步:循环

第四阶段:实验设计与验证分析
主实验设计解读:核心论点的验证
- 核心主张:R-Zero 框架能够在“零数据”启动的条件下,通过“挑战者-解决者”的协同进化,显著提升大语言模型在数学和通用领域的推理能力。 好的,没问题。许多Markdown渲染器确实对多级列表的支持不佳。
实验设计
数据集:
- 数学推理:AMC, Minerva, MATH-500, GSM8K, Olympiad-Bench, AIME 等。这些是数学推理领域的公认基准(Benchmark),难度和类型各异,能全面评估模型的数学能力。
- 通用推理:MMLU-Pro, SuperGPQA, BBEH。这些是高难度的通用能力测试集,MMLU-Pro是MMLU的增强版,SuperGPQA则专门设计为“网络不可搜索”,以测试真实的推理能力而非记忆。选择这些是为了验证从数学领域学到的“推理能力”是否可以泛化。
- 合理性分析:这个选择非常合理。首先,数学领域答案客观,便于实现R-Zero内部的“多数投票”机制。其次,通过在通用基准上测试,有力地回应了“这套方法是否只是让模型变成了数学刷题机器”的质疑,证明了其学习到的是更底层的通用能力。
评价指标:
- 对于AMC/AIME等难题,使用 mean@32(生成32个答案看平均正确率);其他任务使用 greedy decoding 的准确率。这些都是对应任务的标准评价指标,能够公正地衡量性能。
基线方法(Baselines):
- Base Model:未经任何训练的原始模型。这是性能的起点。
- Base Challenger:一个关键的基线。它代表了一种简化的自训练——Solver直接学习一个未经强化学习训练的Challenger生成的问题。
- 合理性分析:Base Challenger 这个基线设置得非常巧妙。它和 R-Zero 的唯一区别就在于 Challenger 是否经过了“不确定性奖励”的RL训练。因此,R-Zero (Iter 1) 与 Base Challenger 的性能对比,能够直接、干净地证明 Challenger 的智能化进化是至关重要的,而不仅仅是“有更多数据”就行。
结果与结论:
- 主实验结果(Table 1 & 2):结果显示,R-Zero (Iter 1) 的性能显著高于 Base Challenger,而 Base Challenger 又略高于 Base Model。并且,随着迭代次数增加(Iter 1 -> Iter 2 -> Iter 3),R-Zero 的性能呈现出持续的、单调递增的趋势。
- 其核心的 “智能课程生成”(即RL训练的Challenger)是成功的关键,而非简单的“数据增强”。
消融实验分析:内部组件的贡献
- 消融实验设计 (Section 5.1):作者在 Qwen3-4B-Base 模型上进行了消融研究,移除了三个关键模块来观察性能下降情况。
- w/o RL-Challenger:移除Challenger的强化学习训练环节。这对应了论文的核心创新点——不确定性驱动的课程生成。
- w/o Filtering:移除Solver训练数据中的难度过滤步骤。这对应了“有价值课程筛选”这一设计。
- w/o Rep. Penalty:移除Challenger奖励中的重复惩罚。这对应了保证问题多样性的设计。
- 结果与证明:实验结果(论文中描述,Table 3在OCR中不完整)表明,移除任何一个组件都会导致性能显著下降。其中,w/o RL-Challenger 导致的性能下降最为严重。
- 这定量地证明了:智能的、由不确定性驱动的Challenger是R-Zero的基石,其贡献最大。
- 同时,难度过滤和多样性惩罚也都是必要且不可替代的,它们分别保证了Solver的学习效率和Challenger的探索广度。这使得整个方法论的内部逻辑更加坚实。
深度/创新性实验剖析:洞察方法的内在特性
- 实验一:问题难度与伪标签准确率的演化分析 (Section 5.2, Table 4)
- 实验目的:深入探究协同进化的动态过程。Challenger真的在生成越来越难的问题吗?Solver的“多数投票”机制在进化过程中是否一直可靠?
- 实验设计:这个设计非常聪明。作者引入了一个“上帝视角”的裁判——GPT-4o。他们让GPT-4o去解答不同迭代轮次(Iter 1, 2, 3)中Challenger生成的题目。GPT-4o的准确率可以被看作是这些题目的客观真实难度。同时,他们也用真实答案去验证了Solver在每一轮生成的“伪标签”的真实准确率。
1.Challenger在进化:随着迭代,GPT-4o在这些题目上的准确率持续下降(从59%降到45%),证明了Challenger确实在生成越来越难的、更高质量的问题。
2.伪标签的挑战:Solver生成的伪标签的真实准确率也随着迭代而下降(从79%降到63%)。这揭示了R-Zero的一个内在权衡:当问题变得足够难,接近Solver的能力极限时,它的“多数投票”会变得不那么可靠。
3.奖励机制的有效性:最关键的是,数据显示,每一轮的Solver在面对其同代Challenger出的题时,准确率始终稳定在50%-51.5%左右。这完美地证明了不确定性奖励机制在精确地工作,成功地将难度校准在了“能力边缘”。
- 实验二:与监督数据的协同效应分析 (Section 5.3, Figure 3)
- 实验目的:验证R-Zero到底是监督微调(SFT)的替代品,还是一个强大的“预热”或“放大器”。
- 实验设计:作者画了两条线。一条是基线:直接用一个有标签的数学数据集对Base Model进行SFT。另一条是R-Zero + SFT:先用R-Zero进行多轮自进化,然后在每个迭代的检查点上,再用同一个有标签数据集进行SFT。
- 实验结论:结果(Figure 3)清晰地显示,R-Zero + SFT这条线的性能始终显著高于纯SFT的基线。这说明R-Zero并非多余。它通过自进化过程,为模型打下了更坚实的推理能力基础,使得模型能更好地吸收和利用后续的有标签数据。这极大地提升了R-Zero的实用价值,证明它可以作为一个强大的、通用的性能增强器,与现有SFT流程结合。
本文题目:R-Zero: Self-Evolving Reasoning LLM from Zero Data
文章来自于微信公众号“沈公子今天读什么”,作者是“Tensorlng 看天下”。


