# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
真正的业务宝藏往往就埋藏在那些看似杂乱无章的文本数据之中,即非结构化文本,但问题是,如何高效、可靠地把这些宝藏精准地挖出来,一直是个令人头疼的难题,今天我们就来聊聊最近GitHub12.3k star爆火的Google 开源项目LangExtract,它为这个问题提供了一个相当漂亮的答案。https://github.com/google/langextract

一份临床报告里医生的细腻描述、一封客户投诉邮件中的情绪细节,这些非结构化文本中包含了数据库表格无法承载的深度与即时性。这些信息是驱动产品迭代、洞察市场趋势的“富矿”,但传统的“人工挖掘”,也就是手动复制粘贴,实在是充满了槽点。
只需要pip install langextract
便能使用一整套解决信息提取问题的工程化框架。它让您可以通过清晰的指令和几个范例,指挥像 Gemini GPT Deepseek这样的模型,将海量文本自动转化为干净、规整、可用的结构化数据。可以说,它在 LLM 的强大能力和工程应用的刚性需求之间,架起了一座至关重要的桥梁。
它最核心的优势,在于它真正从开发者的角度思考了信息提取任务的闭环,它通过几个关键特性解决了我们最关心的问题。
精准的来源定位 您提取出的每一条信息,它都能像导航一样精确地标出它在原文中的“坐标”,也就是字符偏移量。这意味着所有结果都100%可追溯、可验证,这对于需要高可靠性的应用场景来说,简直是刚需。
可靠的结构化输出 它利用了 Gemini 等模型支持的“受控生成”技术,您可以预先用 Pydantic 定义好严格的数据模式(Schema)并提供一个或多个“少样本”示例。结果就是,无论模型怎么运行,最终吐出的数据格式永远是您期望的样子,再也不用头疼地去处理模型“自由发挥”带来的各种奇葩输出了。这一点研究者已经对《罗密欧与朱丽叶》的全文分析中已得到充分验证,展现出其强大的结果稳定性。
为长文档而生的优化 面对几十万字的长篇大论,很多模型都会犯迷糊,出现“大海捞针”捞不着的情况。LangExtract 通过文本分块、并行处理和多轮提取的组合拳,专门优化了这个问题,确保在处理大型文档时也能保持相当高的召回率和处理效率。
交互式可视化 几分钟内即可从原始文本生成一个独立的交互式HTML可视化结果。LangExtract可以让用户能够轻松地在上下文中查看提取的实体,并对成千上万条注解进行高效探索。
无需GPU,纯CPU运行 这个库本身非常轻量,它将繁重的模型推理任务完全解耦给了后端的LLM服务。这意味着LangExtract自身可以在任何普通的CPU机器上高速运行,您无需为这个框架本身配置昂贵的GPU资源,这是一个非常聪明的工程设计。
非Embedding的确定性定位 您可能会好奇它的精准定位是如何实现的。LangExtract使用的是一套精巧的确定性文本对齐算法:首先通过指令让LLM返回原文片段,然后利用WordAligner进行多层次匹配——从精确字符串匹配到模糊相似度计算,但始终避免了基于向量embedding的模糊对齐。这种方法既保证了高效性,又确保了来源追溯的准确性。
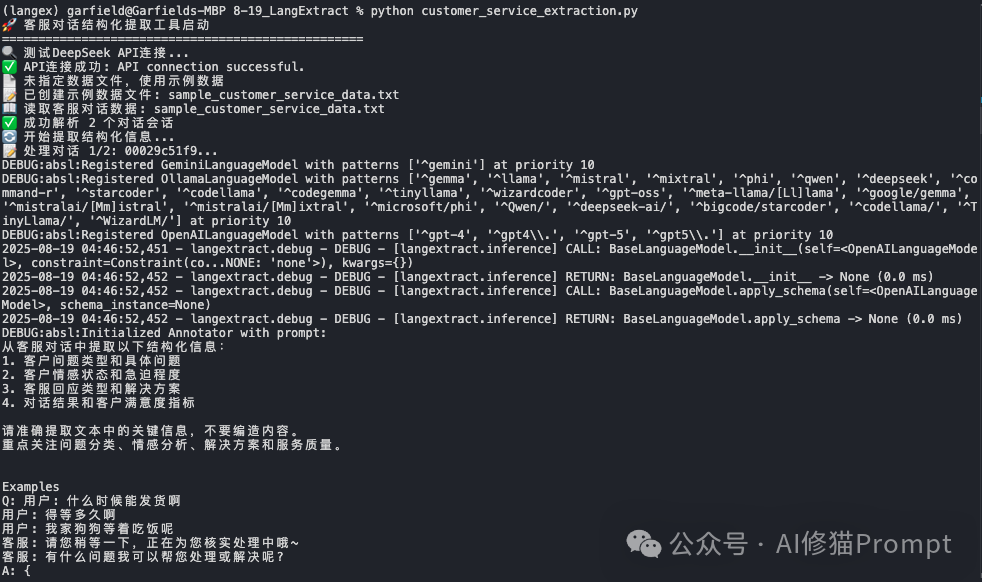
为了验证LangExtract的实际能力,我专门开发了一个客服对话结构化提取工具,将看似杂乱的客服聊天记录转化为可分析的结构化数据。
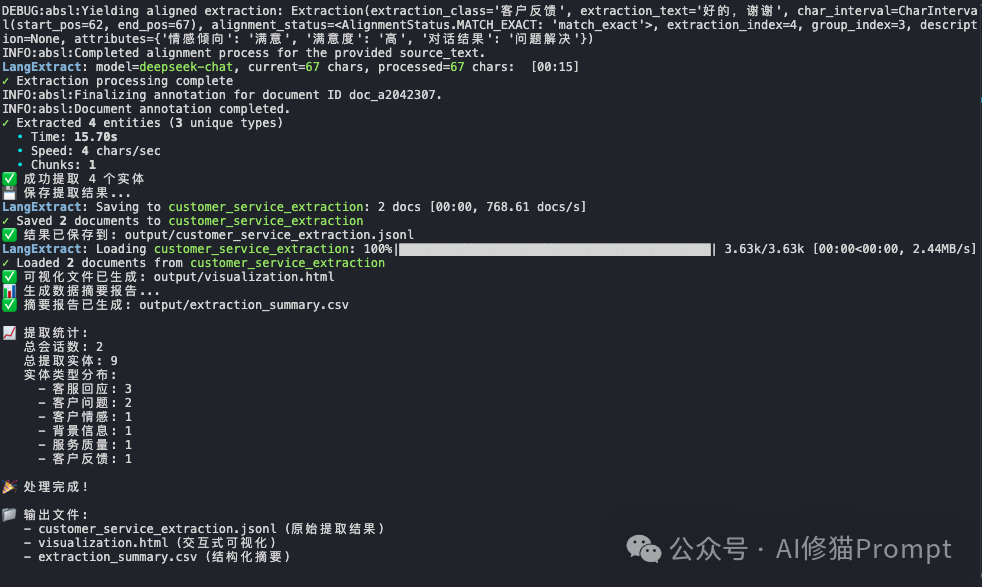
提取统计概览:
实体类型分布:
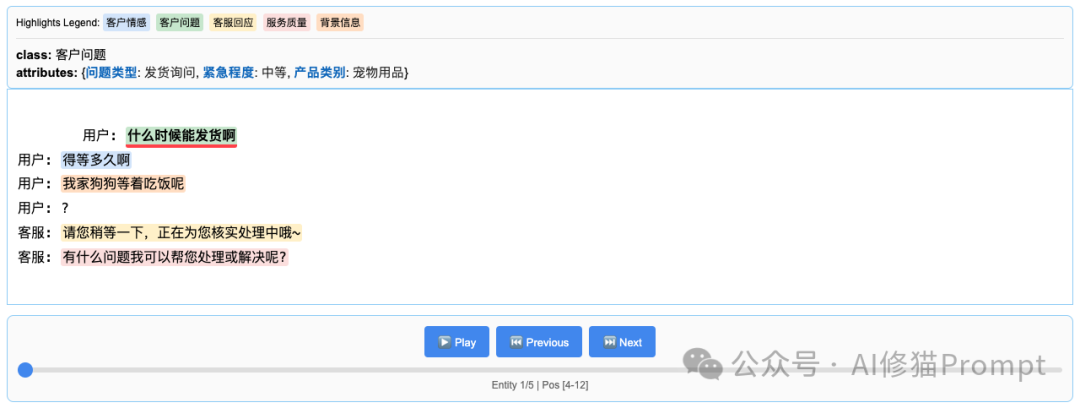
LangExtract对细微语义的把握非常好。比如面对客户的"我家狗狗等着吃饭呢"这句话,它准确识别出:
{
"背景信息":"我家狗狗等着吃饭呢",
"背景信息_attributes":{
"使用场景":"宠物喂食",
"时效要求":"紧急",
"客户类型":"宠物主人"
},
"char_interval":{"start_pos":27,"end_pos":36}
}
注意这个char_interval字段,这就是LangExtract的杀手级特性,每个提取结果都精确标注了在原文中的位置,实现了100%的溯源能力。
工具自动生成的HTML可视化文件更是让人眼前一亮:
周末我会将这个代码分享在我的Agent开发者交流群里,欢迎你来一起交流!
如果说LangExtract是手术刀,那ContextGem则构建了一个全功能的文档手术室。我之前专门写过一篇文章来介绍ContextGem,感兴趣您可以看一下

精准提取数据太折磨人,试下pip install -U contextgem,自动生成提示 | 痛快
ContextGem厉害的地方在于引入了 SAT (Segment Any Text) 神经网络模型进行智能分段,从根本上解决了LLM提取任务中“垃圾进,垃圾出”的难题。
那么,面对这两个优秀的框架,该如何选择?这并不完全是一个谁优谁劣的问题,而是一个场景匹配问题。
选择 LangExtract 的场景:
选择 ContextGem 的场景:
LangExtract最初的设计理念其实是应用于医疗信息提取,研究者们希望用它来高效地处理复杂的临床文本。比如,从医生的非结构化病程记录中,精准地识别出药物名称、剂量、用法以及它们之间的关联关系。这一能力是推动LangExtract诞生的核心研究成果,他们早在2023年就发表过一篇论文,说明LangExtract的功力非常深厚

并且最近还在 Hugging Face 上开发了一个名为 RadExtract 的交互式演示,用于结构化放射学报告。该演示展示了LangExtract如何处理自由文本形式的放射学报告,并自动将其关键发现结果转换为结构化格式,同时突出显示重要的结果。这种方法在放射学领域尤为重要,因为结构化报告能够提升信息清晰度、确保内容完整性,并增强数据在科研与临床诊疗中的互操作性。感兴趣您可以看一下 https://google-radextract.hf.space/
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
