# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从 Sora 的惊艳亮相到多款高性能开源模型的诞生,视频生成在过去两年迎来爆发式进步,已能生成几十秒的高质量短片。然而,要想生成时长超过 1 分钟、内容与运动可控、风格统一的超长视频,仍面临巨大挑战。
为此,上海人工智能实验室联合南京大学、复旦大学、南洋理工大学 S-Lab、英伟达等机构提出 LongVie 框架,系统性解决可控长视频生成中的核心难题。


直接利用当前的可控视频生成模型生成分钟级长视频时,通常会出现以下问题:

LongVie 从「控制信号」与「初始噪声」两条路径入手:
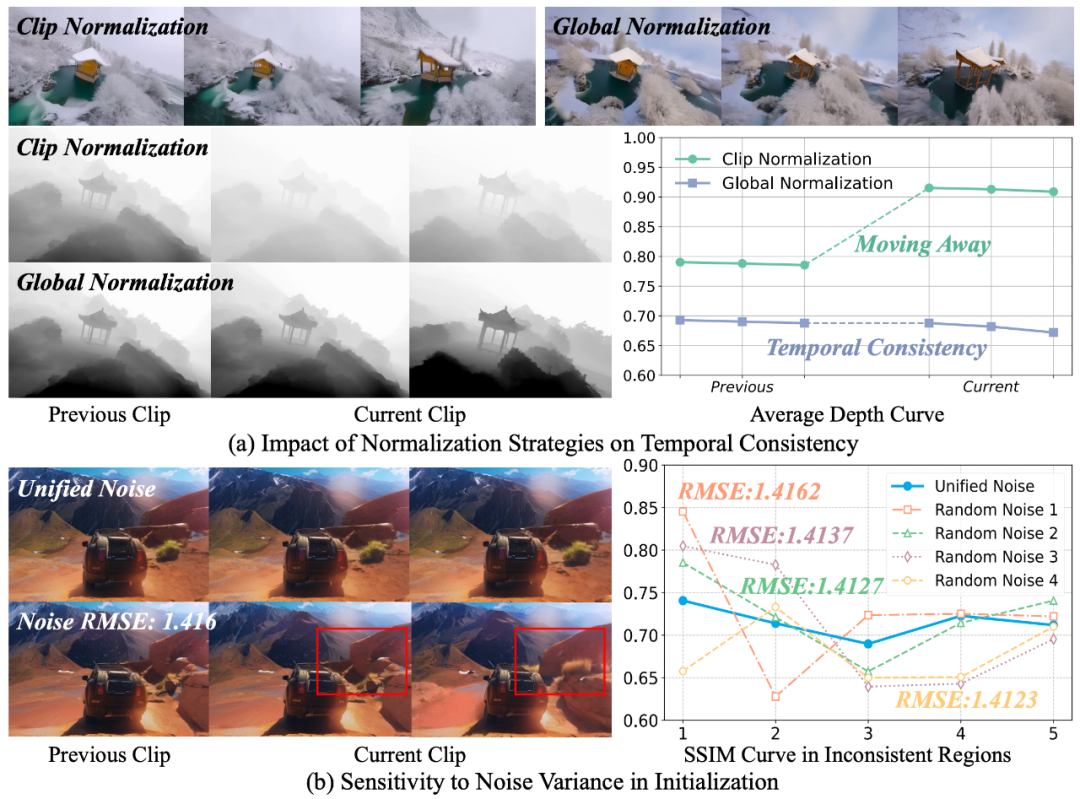
1. 控制信号全局归一化(Control Signals Global Normalization)
将控制信号在全片段范围内统一归一化,而非仅在单一片段内归一化,显著提升跨片段拼接时的一致性。
2. 统一噪声初始化(Unified Noise Initialization)
各片段共享同一初始噪声,从源头对齐不同片段的生成分布,减少前后帧外观与细节漂移。
(下图展示了两项策略带来的前后一致性提升)
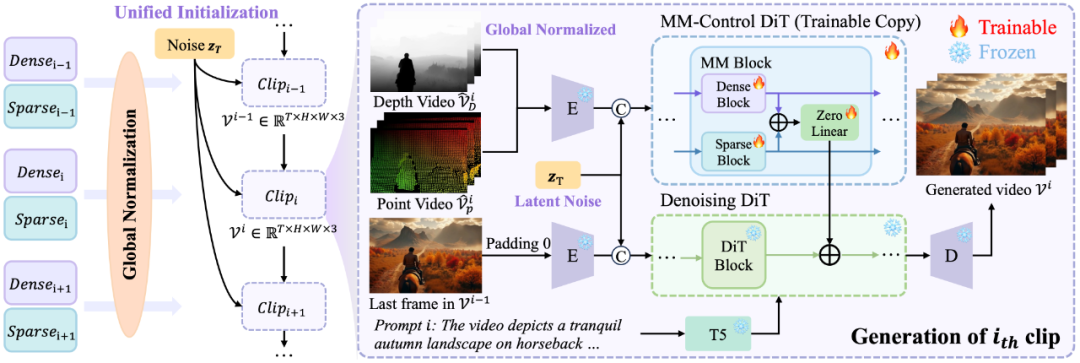
单一模态的控制难以在长时间下提供稳定而全面的约束,误差会随时间累积并引发画质下降。LongVie 融合密集控制信号(如深度图)与稀疏控制信号(如关键点),并引入退化感知训练策略,在更贴近长序列退化分布的条件下训练模型,使长视频生成在细节与稳定性上同时受益。
(下图给出了单一模态与多模态对比示例)


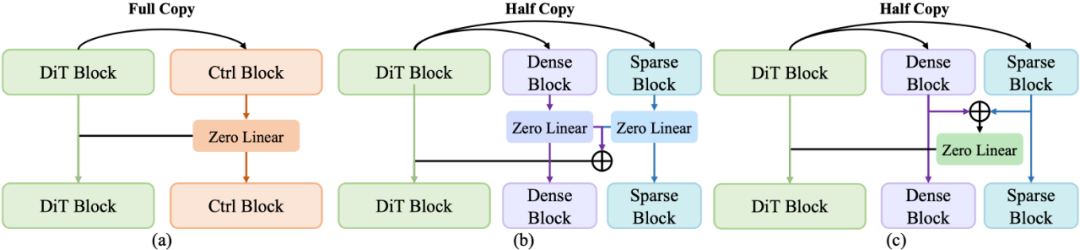
控制信号怎么融合更稳更强?团队把标准 ControlNet(a)和两种变体(b、c)都做了对比测试,结果显示变体(c)效果更好、训练更稳定,最终被采纳。
LongVie 支持多种长视频生成下游任务,包括但不限于:
(如下图为不同任务的效果示例)



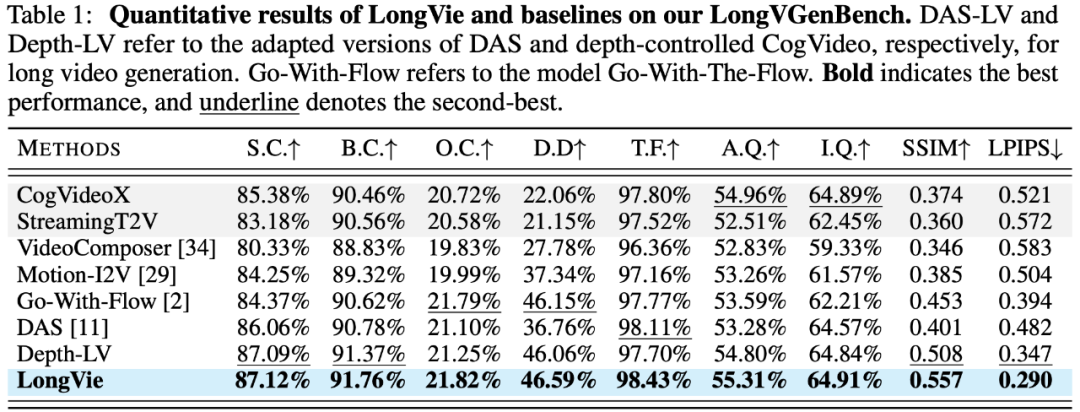
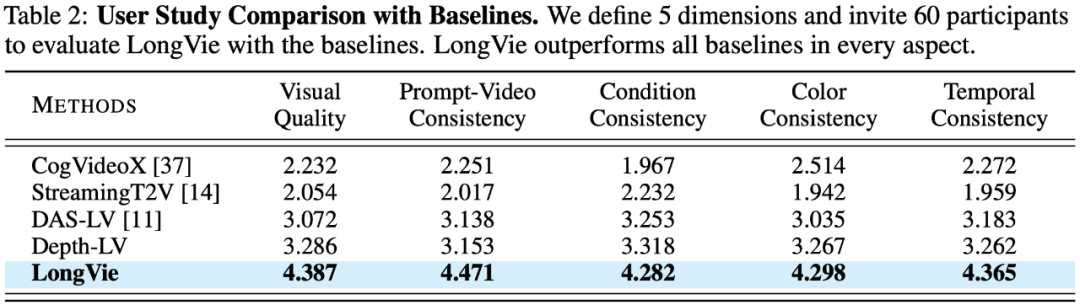
当前缺乏面向可控长视频生成的标准化评测。为此,作者团队提出 LongVGenBench—— 首个专为超长视频生成设计的基准数据集,包含 100 个时长超过 1 分钟的高分辨率视频,旨在推动该方向的系统研究与公平评测。
基于 LongVGenBench 的定量指标与用户主观测评显示,LongVie 在多项指标上优于现有方法,并获得最高用户偏好度,达到 SOTA 水平。(详见下表与用户研究结果)
文章来自于微信公众号“机器之心”。


