# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI Agent正在被要求处理越来越多复杂的任务。
但当它要不停地查资料、跳页面、筛选信息时,显存狂飙、算力吃紧的问题就来了。
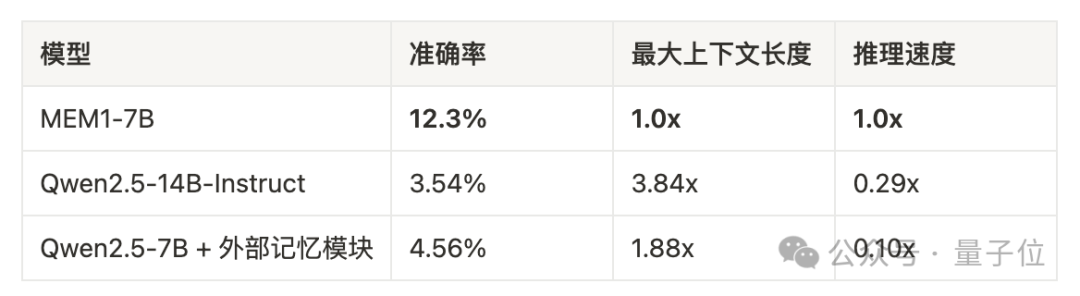
针对这一难题,MIT和新加坡国立大学联合提出了MEM1框架。实验结果显示,7B参数MEM1模型的推理速度能达到传统14B模型的3.5倍,同时峰值上下文token(peak token)数量约为后者1/4。
该框架提出了一种基于强化学习的推理方案,通过让智能体学会将记忆更新作为上下文的一部分,从而实现近似常量级的显存开销(near constant memory)。
目前相关论文已被大语言模型会议COLM 2025 Reasoning,Attention & Memory:RAM 2 workshop收录为口头报告(Oral),会议将于今年10月份在加拿大蒙特利尔举办。

想象一位科研工作者连续工作一周后的大脑——充斥着各种公式、实验数据和临时灵感,但真正用于解决问题的只是其中核心片段。
对于人来说,每过一段时间起身喝杯咖啡醒醒脑,可以整理思绪,但是对于AI agent来说,这就难了。
经典的大语言模型采用全上下文提示技术,每轮交互都完整附上所有历史记录。随着对话轮次增加,计算成本和内存需求都呈线性增长(O(N))。
无限线性增长的上下文导致三个严重问题:
MEM1的核心创新在于通过训练的方式让模型自主将记忆与推理统一。
不同于简单地添加外部记忆模块(如RAG类的方法),MEM1通过端到端强化学习训练代理,使其在每一步自动完成三个关键操作:
1、提取——从新观察中识别关键信息;
2、整合——将新信息与内部记忆状态融合;
3、修剪——丢弃冗余或无关内容。
通过这种训练方法,AI Agent仅需维护自己上下文中的一个<IS>内部状态(Internal State),这个<IS>包含之前上下文中所有模型自己认为需要保留的重要信息。
通过引入<IS>,模型的上下文不会随交互轮次增加而膨胀。
不仅如此,<IS>的引入使得模型的推理过程与记忆整合可以有机地结合在一起,它不仅提供对当前查询的深度洞察,还充当“工作记忆”,从收集信息中提取关键组件构建下一步推理。
这种过程也十分符合人们自己整理思绪的过程:杂乱陈旧的记忆被遗忘,同时随着记忆被整合,下一步的工作重点也随之显现出来。
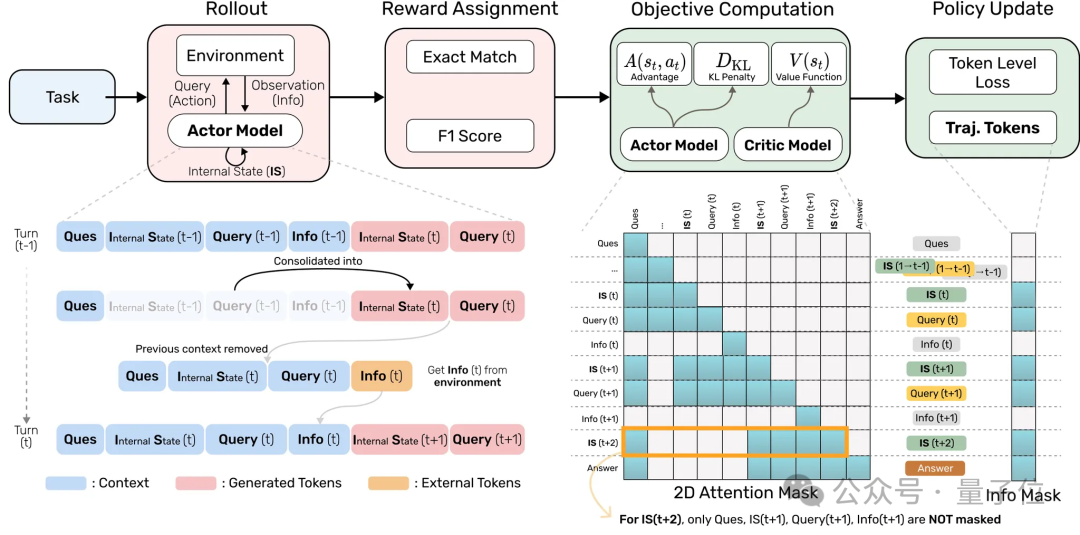
MEM1采用端到端的基于结果奖励(Outcome Reward)的强化学习训练方式,并引入一种特殊的注意力掩码机制(Attention Mask)。
该机制限定Agent在生成下一步输出时只能关注到上一轮交互的内容,从而迫使其学会对历史信息进行高效压缩,同时提升推理与问题求解能力。
相对于传统的RL训练,MEM1在rollout期间引入了多个trajectories来训练compressed reasoning。为了提升训练效率,MEM1使用attention masking技巧将面向同一个任务的多个trajectories压缩成一个进行高效训练。
在推理阶段,MEM1 agent会在推理时由agent自主地不断整合自己的context。整合完之后,之前的memory会自动从context中移出,从而达到在长程环境交互任务下控制context长度的目的。
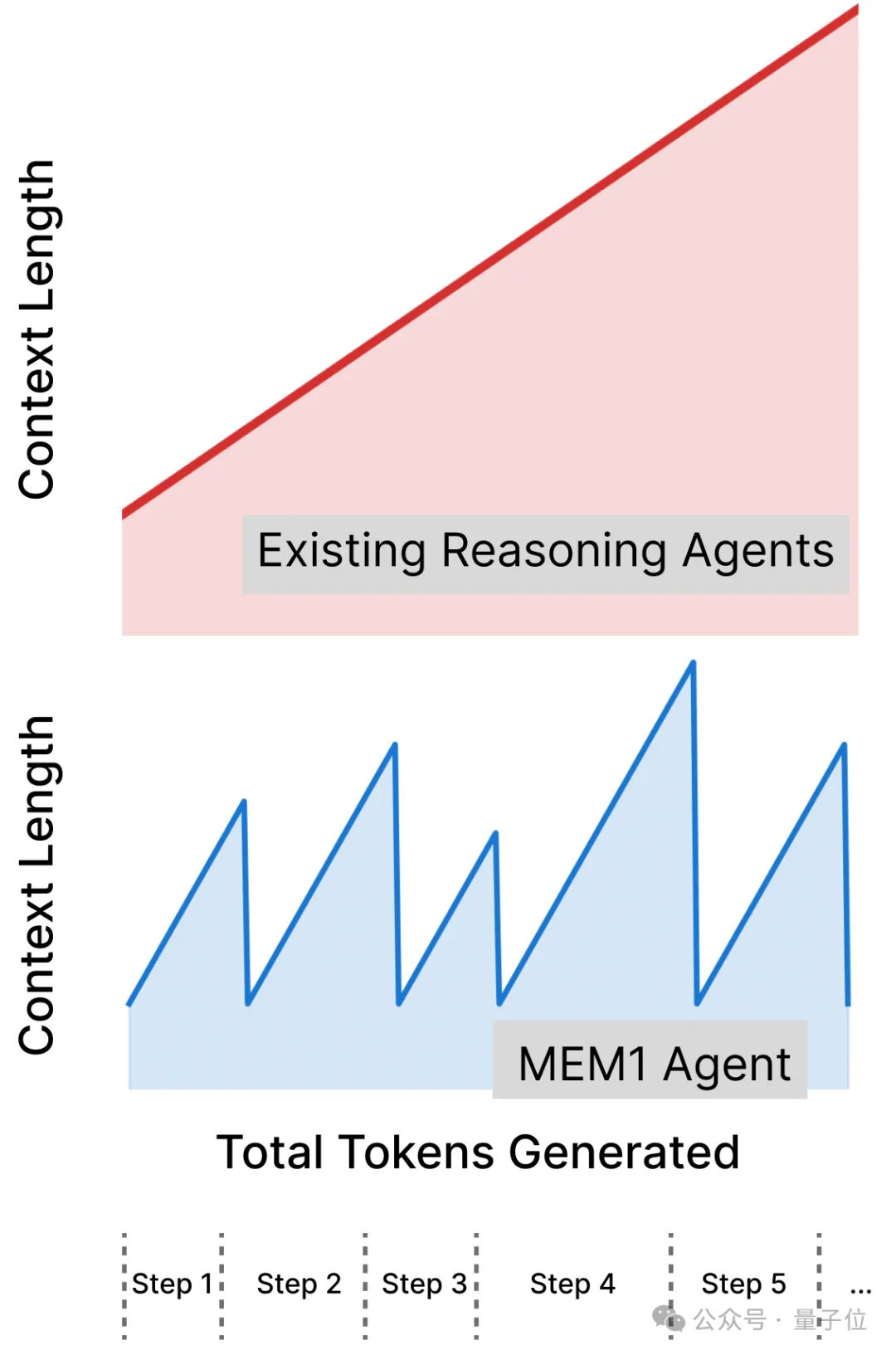
上图为MEM1(下)和现有推理模型(上)在长程任务上上下文占用的对比,可以看出现有推理模型上下文会随着轮次增加线性增长,但MEM1每一轮后将被压缩过的信息移出context使得上下文保持近似不变。
经典的RL环境通常是为短交互设计,并不能很好的鼓励模型进行长期多轮的推理。大家比较熟知的多轮对话数据集,例如hotpot QA等通常也只需要模型进行两轮推理。
为了验证MEM1训练方法的效果,MEM1团队基于现有的数据集构造了一个高难度多目标问答任务的训练环境。团队基于以下不同领域的数据集构建了训练环境并进行训练:
1、Doc检索QA:模拟研究代理查阅内部文档;
2、开放域Web QA:真实网络环境信息获取;
3、多轮网购:WebShop平台的复杂决策链。
团队在2目标任务上训练MEM1 agent,然后在复杂的16目标任务上测试。
MEM1展现出了超越训练范围的强大泛化能力,在16目标任务上,MEM1准确率,上下文长度,推理速度三个维度上全方面超过比他更大的模型以及带有外部记忆模块的模型。
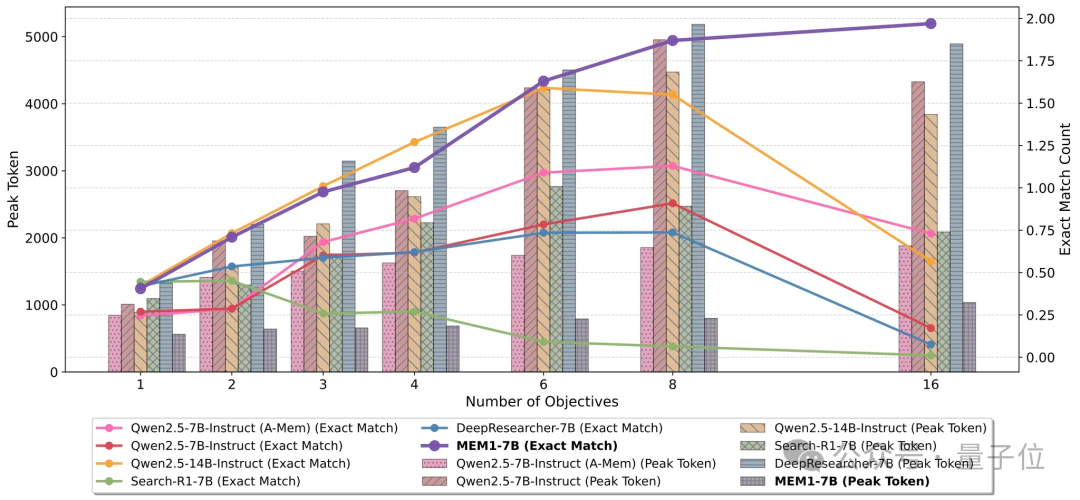
随后,研究团队对MEM1 agent的推理行为进行了定性分析,发现MEM1在处理多轮搜索推理任务时成功展现出了推理与信息整合的双重能力。
记忆方面,MEM1展现出了分问题独立存储以及信息更新能力。在推理方面,MEM1能够掌握自适应的搜索策略,例如拆解子问题,调整关键词查询,以及任务规划等等。

MEM1为处理AI Agent长推理上下文这一重大挑战提供了一个非常有意思的思路。
当下工业界处理上下文仍是以接入外部记忆模块作为主流方法。但是这种做法通常需要很繁琐的工程,而且效果难以掌控。
随着AI Agent端到端强化学习范式的兴起,智能体记忆或许可以通过RL的方式让模型自己来处理。正如MEM1团队提到的:智能不是让AI记住一切,而是教会它自己决定应该如何记忆。
论文地址:https://arxiv.org/abs/2506.15841
代码地址:https://github.com/MIT-MI/MEM1
开源模型:https://huggingface.co/Mem-Lab/Qwen2.5-7B-RL-RAG-Q2-EM-Release
文章来自于微信公众号“量子位”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
