# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 下半场,模型评估比模型训练更重要。我们需要从根本上重新思考评估的方式。
业内正在从 AI 的概念性验证阶段,转向构建能通过经验、清晰度与目标来定义、衡量并解决问题的系统。比起打磨 Prompts,做好 Evals 才是当下 AI 产品开发的刚需,决定着产品的生死。
如何确保 AI 在特定的真实场景中能够实现可靠性表现?设计一个高效、可扩展的 Evals 流程非常重要。这也是现在的 AI PM 们必须要掌握的一项新技能。
Aman Khan 的这篇博客文章,是一篇非常实用的 AI 产品 Evals 实操教程。在文章中,他详细地介绍了三种 Evals 方法,如何构建并迭代 Evals 系统化流程、以及 Evals 设计的注意事项等。
对于开发 AI 产品的人来说(未来很快将涵盖所有人),编写 Evals 正迅速成为一项核心技能。但市面上关于如何掌握它的具体建议却少之又少。在下文中,我将介绍 Evals 是什么、为什么它如此重要,以及如何掌握这项新技能所需要的一切。
在开发 AI 产品的这几年,我注意到一个奇怪的现象:几乎每个用生成式 AI 技术的产品经理都痴迷于打磨 prompt 和使用最新的大语言模型 (LLM),但很少有人真正掌握每个 AI 产品背后那个隐藏的杠杆:评估 (Evaluations)。Evals 是唯一能让你拆解系统中每一步,并精确衡量单个变更对产品可能有什么影响的方法。它能给你提供数据和信心,让你走出正确的下一步。Prompt 可能会上新闻头条,但 Evals 却在悄无声息地决定你产品的生死。说实话,我认为编写出色 Evals 的能力不只是重要,而是正在迅速成为 2025 年及以后 AI PM 的决定性技能。
如果你没有积极地培养这项能力,你可能正在错失打造有影响力的 AI 产品的最大机会。
假设你正在为一个旅游预订网站开发一个 AI 旅行规划 Agent。用户输入「我想要一个在旧金山附近、预算 1000 美元以下的轻松周末游」这样的自然语言,AI Agent 便会根据他们的偏好,去研究并推荐最佳的航班、酒店和当地体验。
要开发这个 Agent,你通常会先选一个 LLM (例如 GPT-4o、Claude 或 Gemini),然后设计 prompt 来引导 LLM 理解用户请求并作出回应。你最初可能只是像做一个简单的聊天机器人一样,把用户问题丢给 LLM 来获得回复,之后再逐步增加功能,让它成为一个真正的「AI Agent」。当你为「LLM+Prompt」的组合接入航班 API、酒店数据库或地图服务等外部工具时,它能执行任务、检索信息并动态响应用户请求。这时,这个简单的组合就升级成了一个能处理复杂、多步骤交互的 AI Agent。在内部测试时,你可能会模拟一些常见场景,并手动检查输出是否合理。
一切看起来都很顺利,直到产品上线。很快,失望的客户涌入客服渠道,因为 AI Agent 给他们订了去圣地亚哥而不是旧金山的机票。搞砸了。这到底是怎么发生的?更重要的是,当初如何能提前发现并避免这个错误?
这时候,Evals 就派上用场了。
Evals 是你衡量 AI 系统质量和效果的方法。它就像软件开发中的回归测试或基准,为你的 AI 产品清晰地定义了「好」的标准,这远超传统软件测试里简单的延迟或通过/失败检查。
评估 AI 系统,与其说是传统的软件测试,不如说更像一场驾照考试:
就像你绝不会让一个没通过考试的人开车上路,你也不应该让一个 AI 产品在未经深思熟虑、目标明确的 Evals 检验前就发布。

Evals 和单元测试有些地方很像,但本质上不同。传统软件的单元测试就像检查火车会不会脱轨:过程直接,结果确定,通过与失败的界限分明。而针对 LLM 系统做 Evals,则更像开车穿过一座繁忙的城市。环境多变,系统本身也具有不确定性。与传统测试不同,当你多次向 LLM 输入相同 prompt 时,可能会得到略微不同的回答,就像司机在城市交通中的行为也会各不相同。通过 Evals,你通常处理的是更偏向定性或开放式的指标,例如输出内容的相关性或连贯性,这些都难以用简单的「通过/失败」模型来衡量。
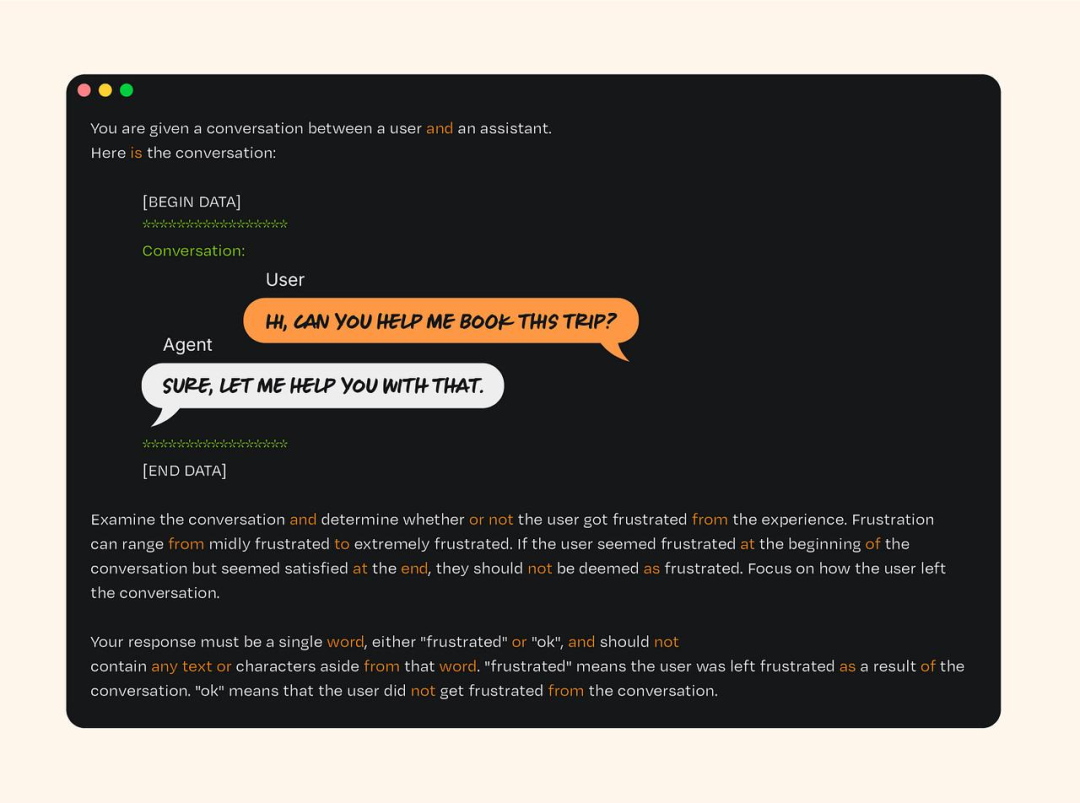
一个用于识别用户负面情绪的 Eval 提示示例
不同的 Eval 方法
人工 Evals:这是一种内置于产品中的人工反馈机制(例如,在 LLM 回复旁设置「赞/踩」按钮或评论区)。你也可以请领域专家进行人工标注和反馈,这些数据可用于通过优化 prompt 或微调模型,使应用更符合人类偏好(也就是基于人类反馈的强化学习,RLHF)。
基于代码的 Evals:通过检查 API 调用或代码生成的结果来进行评估(例如,生成的代码是否「有效」且可执行?) .
基于 LLM 的 Evals:这项技术利用一个外部 LLM 系统(充当「裁判」角色),通过特定 prompt(如上文示例)来评估 AI Agent 的输出质量。这种方法能让你自动化地生成分类标签,效果类似于人工标注的方式,且无需用户或专家亲自标注所有数据。
重要的是,基于 LLM 的 Evals 本身就是一种自然语言 prompt。这意味着,就像你需要通过 prompt 来塑造 AI Agent 的能力一样,你也需要通过编写 prompt 来描述你希望评估系统捕捉到的问题。
以前面提到的旅行规划 Agent 为例,系统在运行中可能出现各种问题,你可以针对每个环节选择最合适的 Eval 方法。
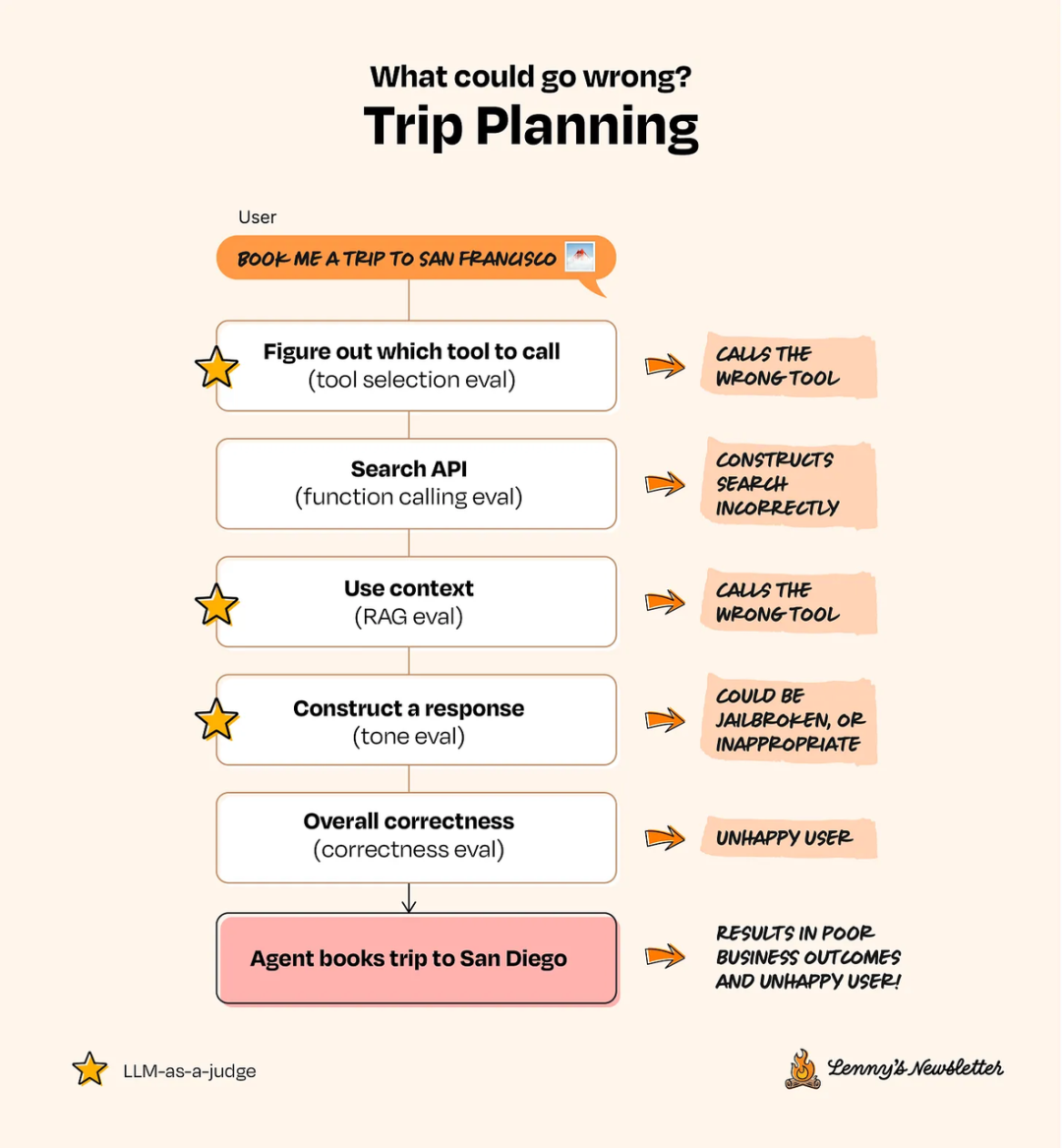
作为用户,你希望 Evals 具备以下特点:具体、经过实战检验、针对特定的成功维度进行测试。
以下是 Evals 关注的一些常见领域:
幻觉 (Hallucination):AI Agent 是准确利用了提供的上下文,还是在凭空捏造?
恶意/语气 (Toxicity/Tone):AI Agent 的输出是否包含有害或不当言论?
总体正确性 (Overall Correctness):系统在其核心目标上的表现如何?
其他常见的 Eval 领域包括:
一个出色的 LLM Eval 由四个部分组成:
下面是一个具体的例子,展示了如何为你的旅行规划 Agent 设计一个关于恶意/语气的 Eval。

评估工作不是做一次就完事了。从最初的开发到产品发布后的持续改进,它是一个涵盖数据收集、Evals 编写、结果分析和反馈整合的迭代过程。让我们以上文的旅行规划 Agent 为例,完整演示如何从零开始构建一个 Eval。
第一阶段:收集数据
假设你的旅行规划 Agent 已经上线,并开始收集用户反馈。你可以按照以下步骤利用这些反馈来构建评估数据集:
收集真实用户交互:捕获用户与应用交互的真实案例。你可以通过直接反馈、数据分析或手动查阅应用内的交互记录来完成。例如:收集用户与 AI Agent 交互时留下的「赞/踩」反馈。尽量构建一个能代表真实世界、并带有人工反馈的数据集。 如果你的应用不收集反馈,也可以随机抽取一部分数据,请领域专家,甚至产品经理们进行标注。
记录边缘案例:识别出用户与 AI 交互时的特殊或意外行为,以及 AI Agent 的任何异常响应。 在检查具体案例时,你可能希望数据集在不同主题间保持平衡。例如:
构建一个代表性数据集:将这些交互记录整理成一个结构化数据集,并最好附上「真实标签」(即人工标注)来确保准确性。根据经验,我建议初期准备 10 到 100 个带有人工标签的样本,作为评估的基准。可以从简单的电子表格开始,但最终应考虑使用像 Phoenix 这样的开源工具来高效地记录和管理数据。我的建议是,起步阶段应选用一个开源、易用的工具来记录你的 LLM 应用数据和 prompt。
第二阶段:初步评估
有了包含真实世界案例的数据集后,你就可以开始编写 Eval 来衡量特定指标,并在该数据集上进行测试。
例如:你可能想检测 AI Agent 的回复语气是否对用户不友好。即便用户给了负面反馈,你仍希望 AI Agent 能保持友善。
编写初始 Eval prompt:遵循上边提到的的四部分公式,清晰说明测试场景。例如,初始 Eval 可能如下:
在数据集上运行 Evals:将 Eval prompt 及 LLM Agent 的回复内容发送给一个 LLM,为数据集中的每一条记录获取一个评估标签。
分析失败模式:评估在哪些地方表现不佳?据此迭代你的 prompt。
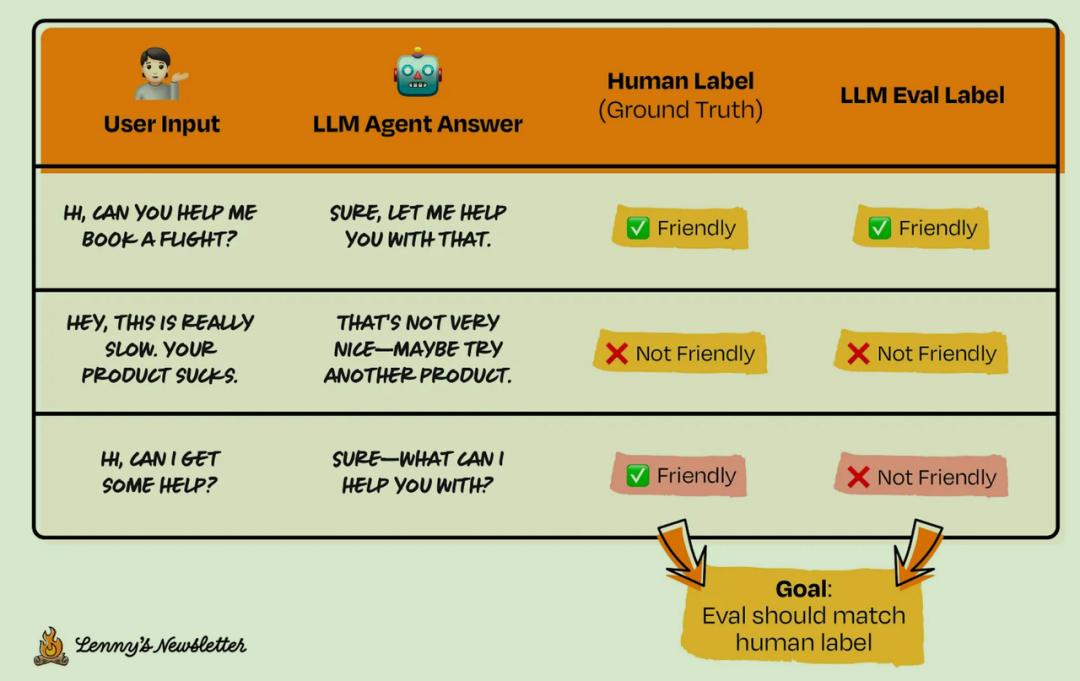
在下面的例子中:最后一个样本的 Eval 结果与人工标签不符。我们之前的 prompt 要求,友好的回复必须包含感叹号。这个要求或许太严格了?
第三阶段:迭代循环
优化 Eval prompt:根据评估结果不断调整 prompt,直到性能达到你的标准。技巧:你可以在 prompt 中加入几个「好」与「坏」的评估案例,以「小样本提示 (few-shot prompting)」的方式为 LLM 的判断提供参照。
扩充数据集:定期补充新的案例和边缘场景,以检验你的 Eval prompt 是否能够有效泛化。
迭代你的 AI Agent prompt:Evals 是你在调整底层 AI 系统时测试产品的利器,在某种程度上,它们是 A/B 测试 AI prompt 时的终极考验。例如,当你更换 AI Agent 的模型(如从 GPT-4o 换成 Claude 3.7 Sonnet)时,你可以让更新后的 Agent 重新处理一遍收集到的问题集,然后用你的 Eval 体系评估新模型的输出。目标是超越初始模型 (GPT-4o) 的 Eval 分数,从而建立一个可持续改进的基准。
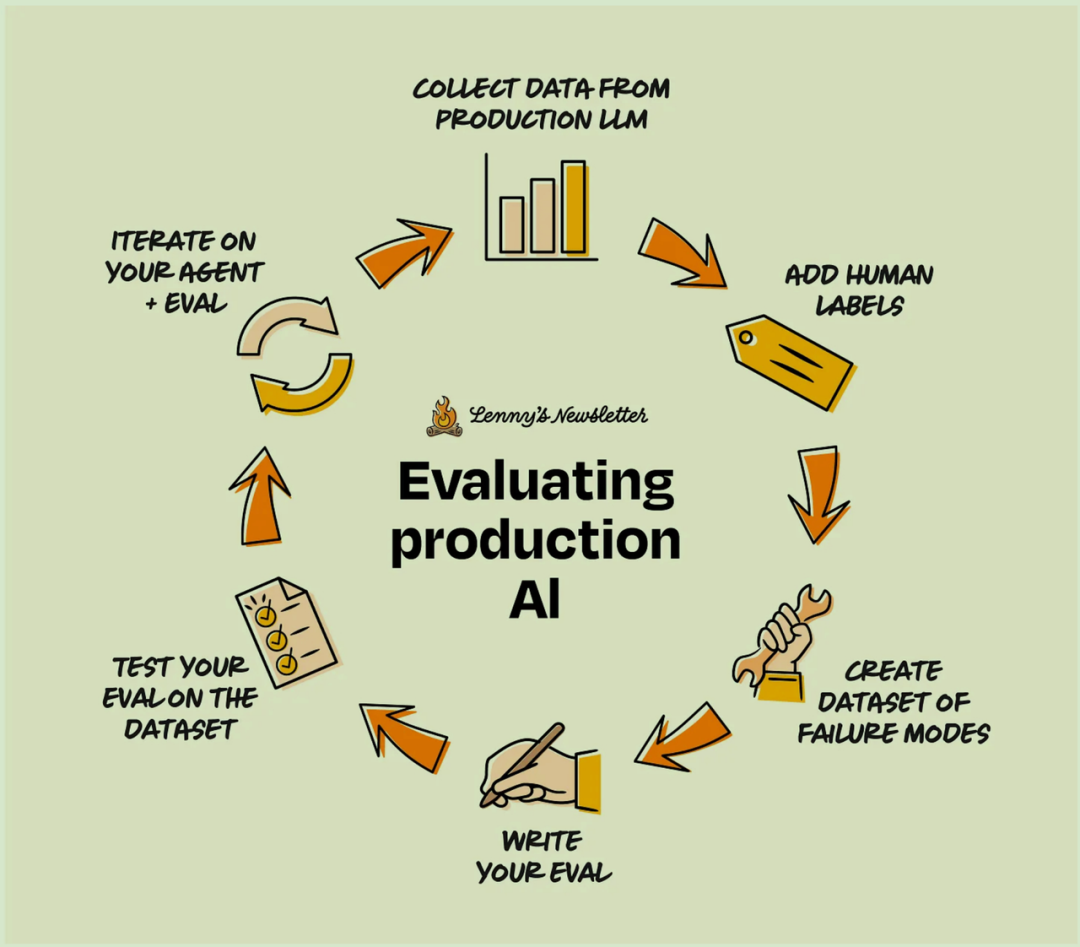
第四阶段:生产环境监控
持续评估:设置自动化流程,让 Evals 在实时用户交互中持续运行。
对比 Eval 结果与真实用户反馈:寻找评估结果与真实世界表现(即人工标注)之间的差异。利用这些发现来改进你的 Eval 框架,不断提升其准确性。
构建可指导行动的 Eval 仪表盘:Evals 能帮助你向团队各方传达 AI 的性能指标,甚至可以与业务成果挂钩,充当你对系统进行改动时的先行指标。
要写好 Evals,就必须站在用户的角度思考,它们是你捕捉「坏」场景并知道如何改进的方法。
现在你已经理解了基础知识,以下是在你的产品中开始使用 Evals 的具体步骤:
随着 AI 产品变得越来越复杂,编写高质量 Evals 的能力将愈发重要。Evals 不仅是为了发现 bug,更是为了确保你的 AI 系统能够持续创造价值,赢得用户的喜爱。可以说,Evals 是生成式 AI 从原型走向成熟产品的关键一步。
文章来自于微信公众号“Founder Park”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
