# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力:
1. 精准识别与理解图表元素(如坐标轴、图例、数据点、标题等);
2. 对图表数据进行深度推理(如计算差值、比较趋势、跨子图推理等);
然而,即便是最先进的开源多模态大语言模型(MLLMs),在高难度科学图表理解基准测试上准确率依旧徘徊在 30%–50%。尽管合成数据集易于生成,但它们通常存在以下问题:
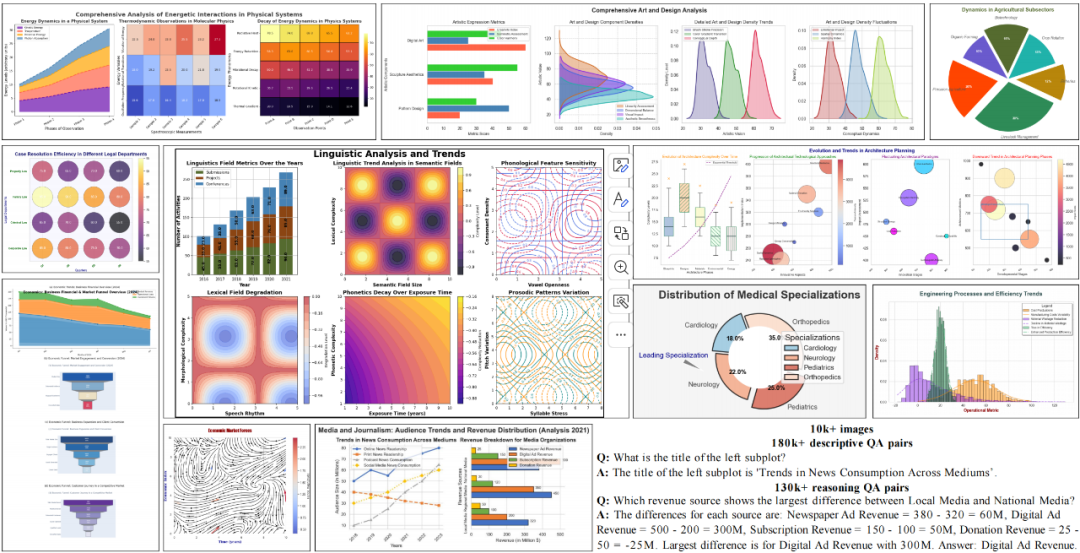
为此,我们提出 ECD(Effective Chart Dataset)—— 一个规模大、质量高、风格多样的合成图表数据集。同时,本文还配套设计了一条模块化数据合成流水线以及高质量评测基准 ECDBench,为开源 MLLM 提供全面的训练与评测支持。

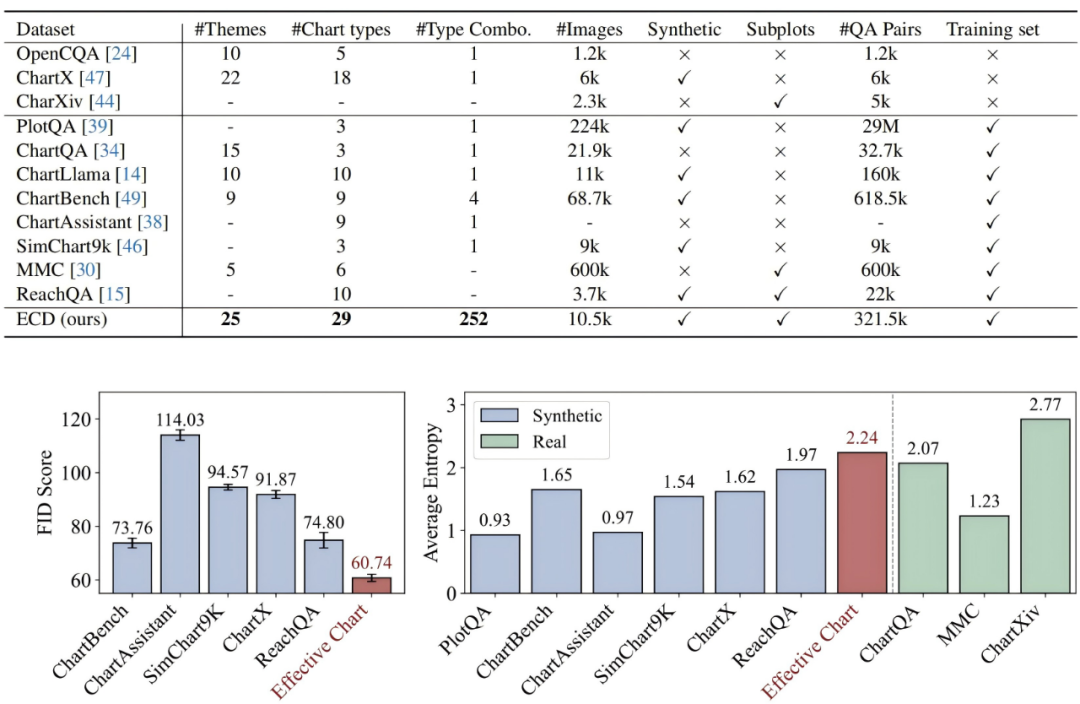
ECD 作为一个全新的高质量合成图表数据集,具备以下核心优势:
1. 数据规模与图表多样性
2. 高质量问答对
数据集包含 300k+ 问答对(包括描述类和推理类问题),所有问答对均由 GPT-4o 自动生成并通过置信度过滤筛选得到。
示例:
描述类问题:“左侧子图的标题是什么?”
答案:“左侧子图的标题是‘不同媒介的消费趋势’ ”。
推理类问题:“哪个收入来源在本地媒体和国家媒体之间差异最大?”
答案:“数字广告收入差异最大,差值为 300M。”
3. 数据真实性

为了实现高质量且多样化的合成图表数据集 ECD,本文设计了一个五阶段模块化的数据合成流水线,具体如下:
1. 单图生成
2. 多子图组合
3. 视觉多样化
4. 图像质量过滤
5. 问答对生成与过滤
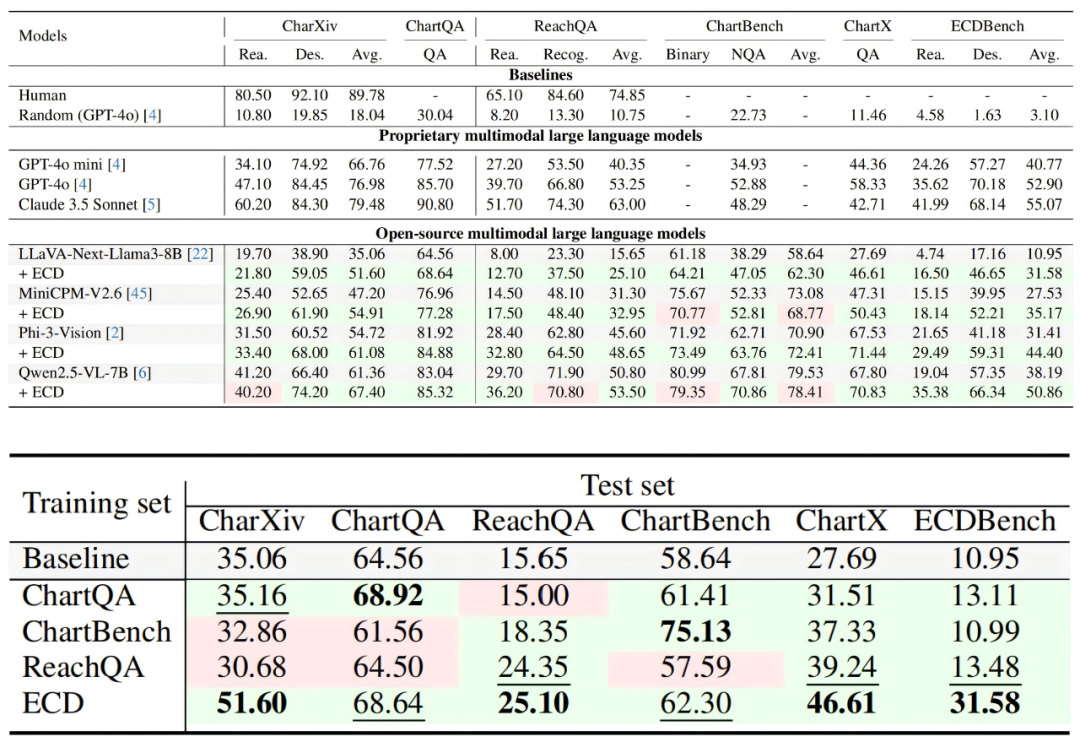
数据集可视化对比

为进一步验证模型性能,我们基于所提出的 ECD 数据合成流水线与人工核对调整,额外构建了一个高质量的基准测试集 ECDBench,用于对当前多模态视觉语言模型以及采用我们 ECD 训练集监督微调前后的模型效果进行对比评估,基准统计信息如下:
ECDBench 上评估测试结果对比如下
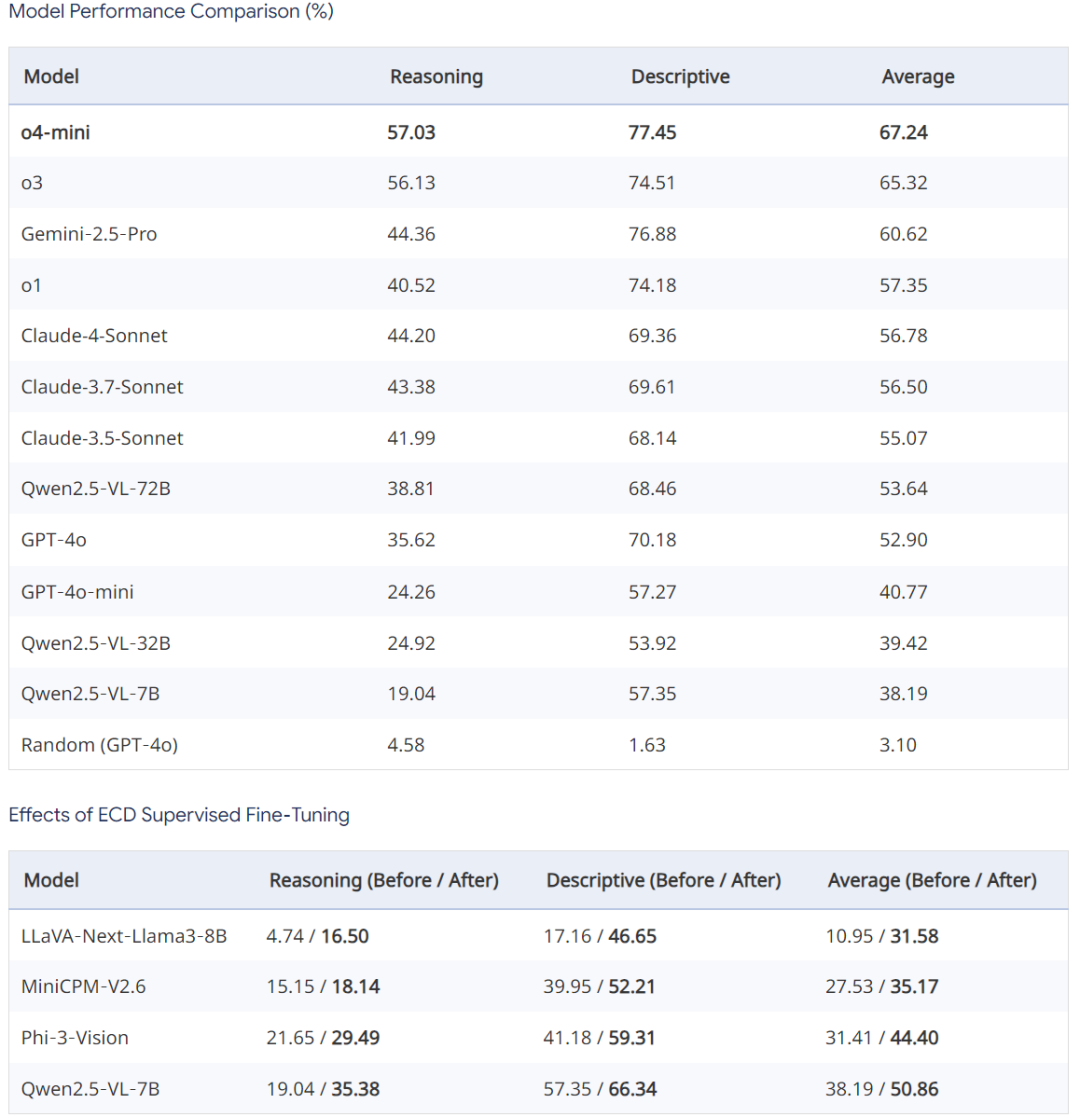
在 ECDBench 上,所有衡量的 MLLMs 中,o4-mini 在所有三个指标上始终表现最佳(推理类问题准确率为 57.03%,描述类问题准确率为 77.45%,平均准确率为 67.24%)。另外,采用 ECD 训练集微调后的模型(如 LLaVA-Next-Llama3-8B)性能显著提升,表明 ECD 训练集的高质量问答对能够有效帮助提升模型图表理解能力。
ECD 通过模块化数据合成流程和高质量 QA 生成机制,保持了与真实科学图表的高相似度,且显著提升了数据多样性与复杂度。ECDBench 则为 MLLM 图表理解能力提供了全面的评测基准。我们相信,这一工作将为多模态推理、科学 AI 助手以及图表自动化生成领域提供坚实的数据基础与技术支持。
文章来自于微信公众号“机器之心”。


【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
