# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你是否曾被 AI 生成视频的惊艳开场所吸引,却在几秒后失望于⾊彩漂移、画面模糊、节奏断裂? 当前 AI 长视频⽣成普遍⾯临 “高开低走 ” 的困境:前几秒惊艳夺⽬ ,之后却质量骤降、细节崩坏;更别提帧间串行生成导致的低效问题 —— 动辄数小时的等待,实时预览几乎难以企及。
这—行业难题,如今迎来突破性解法!
南京大学联合 TeleAI 推出长视频自回归生成新范式——Macro-from-Micro Planning( MMPL),重新定义 AI 视频创作流程。
灵感源自电影工业的 “分镜脚本 + 多组并行拍摄” 机制,MMPL 首创 “宏观规划、微观执行 ” 的双层⽣成架构:
成果令人振奋:
MMPL 不仅是—项技术升级,更是向 “AI 导演” 迈进的重要—步 —— 让机器不仅会 “拍镜头” ,更能 “讲好—个故事”。


在长视频生成领域,随着时长从几秒扩展到数十秒甚至一分钟以上,主流自回归模型面临两个根本性挑战:
1. 时域漂移(Temporal Drift)
由于每—帧都依赖前—帧生成,微小误差会随时间不断累积,导致画面逐渐 “跑偏”:人物变形、场景错乱、色彩失真等问题频发,严重影响视觉质量。
2. 串⾏瓶颈(Serial Bottleneck)
视频必须逐帧⽣成,⽆法并⾏处理。⽣成 60 秒视频可能需要数分钟乃⾄数⼩时,难以⽀持实时预览或交互式创作。

这些问题使得当前 AI 视频仍停留在 “ 片段级表达” ,难以胜任需要长时连贯性的叙事任务。
为解决上述问题,我们提出 Macro-from-Micro Planning( MMPL) —— — 种 “先规划、后填充” 的两阶段生成范式,其核心思想是:
先全局规划,再并行执行。
这—理念借鉴了电影工业中 “导演制定分镜脚本 + 多摄制组并行拍摄” 的协作模式,将长视频生成从 “接龙式绘画” 转变为 “系统性制片 ”。
MMPL 的核心优势在于实现了三大突破:
最终,系统可在保证高质量的前提下,实现分钟级、节奏可控的稳定⽣成,结合蒸馏加速方案,预览速度可达 ≥32 FPS ,接近实时交互体验。
在统—测试集上,MMPL 显著优于现有方法(如 MAGI 、SkyReels 、CausVid 、Self Foricng 等),在视觉质量、时间—致性和稳定性方面均取得领先。


MMPL 的成功源于其精心设计的 “规划 — 填充” 双阶段架构。整个流程分为两个层次:微观规划( Micro Planning) 和宏观规划( Macro Planning),随后进行并行内容填充(Content Populating)。
第⼀阶段:双层规划,构建稳定骨架
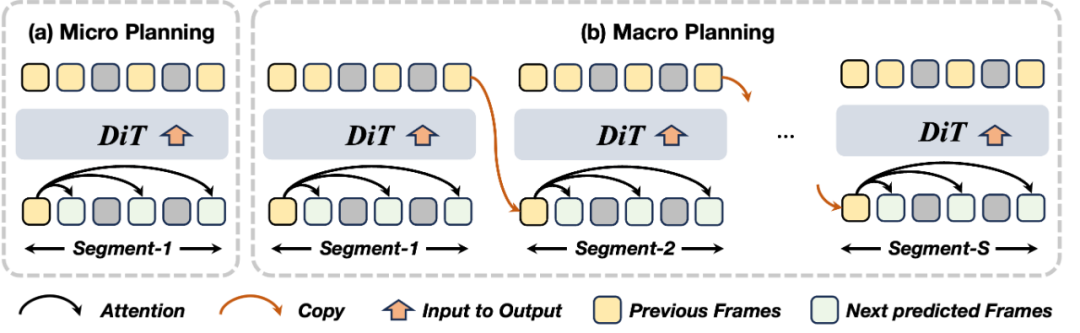
1. Micro Planning: 片段内关键帧联合预测

这些锚点在同—去噪过程中联合生成,彼此之间语义协调、运动连贯;且均以首帧为条件单步预测,避免了多步累积误差。它们共同构成了该片段的 “视觉骨架” ,为后续填充提供强约束。
2. Macro Planning:跨片段叙事⼀致性建模

这种 “分段稀疏连接” 的设计,将误差累积从 T 帧级别降低至 S 段级别( S ≪ T),从根本上缓解了长程漂移问题。
第二阶段:并行填充,释放计算潜能

1. Content Populating:基于锚点的并行细节生成

这意味着: 多个片段可以同时在不同 GPU 上并行⽣成,极大提升效率。
2. Adaptive Workload Scheduling:动态调度,实现流水线加速
为进—步提升资源利用率,我们引入自适应工作负载调度机制,实现 “规划” 与 “填充” 的重叠执行:
当片段 s 的锚点生成后,即可:
该机制的形式化表达为:
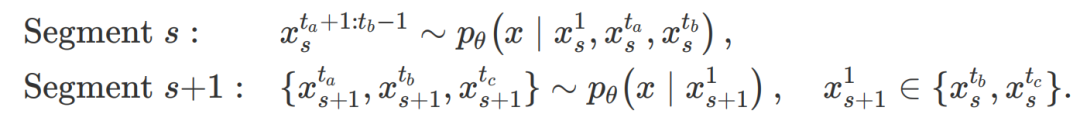

这两种策略可在内存、延迟与吞吐量之间灵活权衡,适配不同部署场景。
当 AI 不再局限于逐帧生成,而是具备了从整体出发的规划能力 —— 理解情节的推进、协调画面的连贯性、控制运动的节奏,长视频生成便迈出了从 “ 片段拼接” 走向 “统—表达” 的关键—步。我们希望,MMPL 能为视频创作提供—种更稳定、更高效的技术路径。借助其近实时的生成能力,创作者可以在快速反馈中不断调整与完善自己的构想,让创意更自由地流动。
也许真正的 “所见即所得” 尚在远方 ,但至少,我们正朝着那个方向,稳步前行。
文章来自于微信公众号“机器之心”。


