# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI自动生成的苹果芯片Metal内核,比官方的还要好?
Gimlet Labs的最新研究显示,在苹果设备上,AI不仅能自动生成Metal内核,还较基线内核实现了87%的PyTorch推理速度提升。
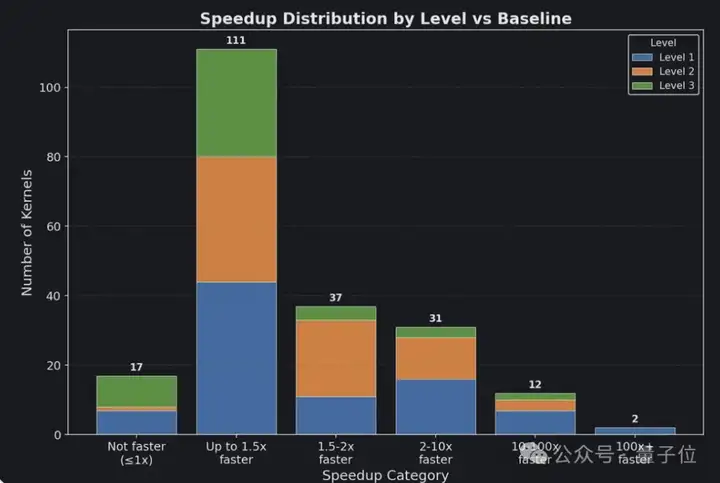
更惊人的是,AI生成的Metal内核还在测试的215个PyTorch模块上实现了平均1.87倍的加速,其中一些工作负载甚至比基准快了数百倍。
真就AI Make苹果AI Great Again?
先说结论:通过AI自动实现内核优化,可以在无需修改用户代码、无需新框架或移植的情况下,显著提升模型性能。
为了证明这一点,研究人员选取了来自Anthropic、DeepSeek和OpenAI的8个顶尖模型,让它们为苹果设备生成优化的GPU内核,以加速PyTorch推理速度。
至于为什么是苹果?别问——问就全球最大硬件供应商(doge)
接下来,让我们看看研究人员是怎么做的:
首先,在模型选择方面,参与测试的模型包括:claude-sonnet-4、claude-opus-4;gpt-4o、gpt-4.1、gpt-5、o3;deepseek-v3、deepseek-r1。
其次,在测试输入方面,研究使用了KernelBench数据集中定义的PyTorch模块,并选取了其中215个模块进行测试。

这些被选取的模块被划分为三个等级,分别是第一级的简单操作(如矩阵乘法、卷积);第二级是由第一级操作组成的多操作序列;第三级是完整的模型架构(如 AlexNet、VGG)。
再次,在评估指标方面,研究人员主要关注两个指标:一是AI生成内核的正确性,二是其相较于基准PyTorch的性能提升。
最后,研究使用的苹果硬件为Mac Studio (Apple M4 Max chip),Baseline为PyTorch eager mode(划重点,一会要考)

在上述准备完毕后,研究团队展开了测试。
测试流程如下:
如上所说,研究者首先关注AI生成内核的正确性。
实验表明,正确性会随着尝试次数的增加而提升。以o3为例:第一次尝试就有约60%的概率得到可用实现,到第5次尝试时可用实现比例达到94%。
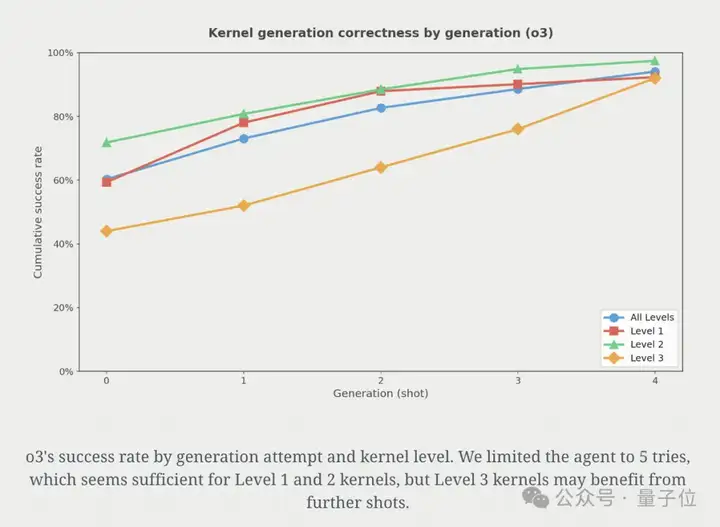
此外,研究还发现推理模型非常擅长跨层级生成正确的内核,尽管非推理模型有时也能做到这一点。
那么,AI生成的内核表现如何呢?
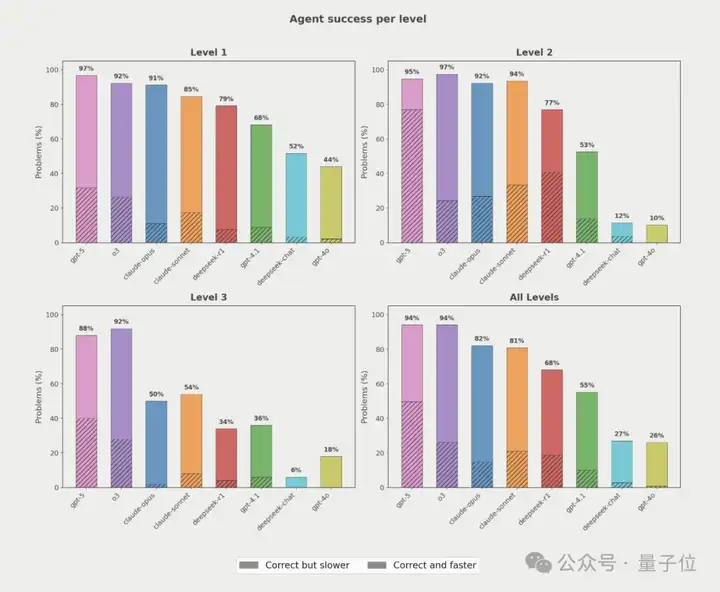
实验结果相当惊艳,几乎每个模型都生成了一些比基准更快的内核。
例如,GPT-5在一个Mamba 25状态空间模型上实现了4.65倍的加速,其主要通过内核融合(kernel fusion) 来减少内核调用的开销,并改善内存访问模式。
在一些案例中,o3甚至将延迟提升了超过9000倍!
总体而言,GPT-5平均可以带来约20%的加速,其他模型则落后。
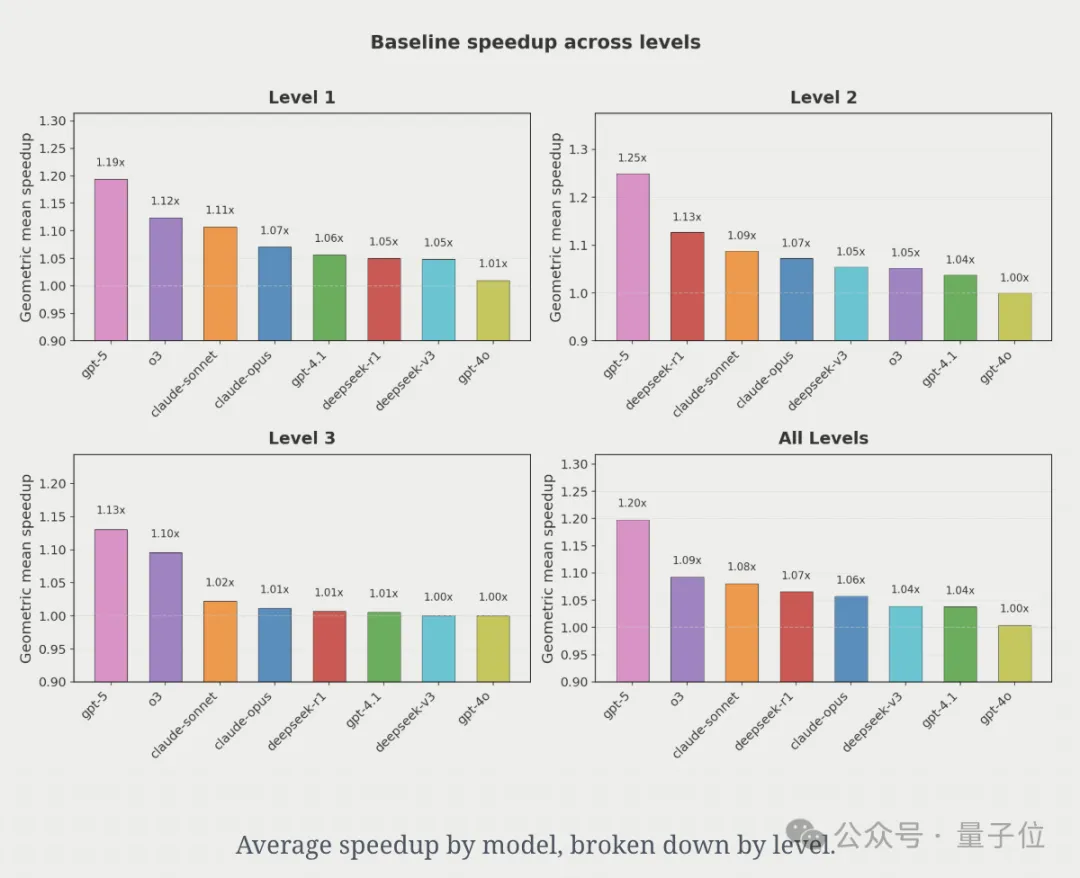
不过,GPT并非是门门最优,研究人员发现GPT-5在34%的问题上生成了最优解。
但在另外30%的问题上,其他模型生成的解比GPT-5更优!
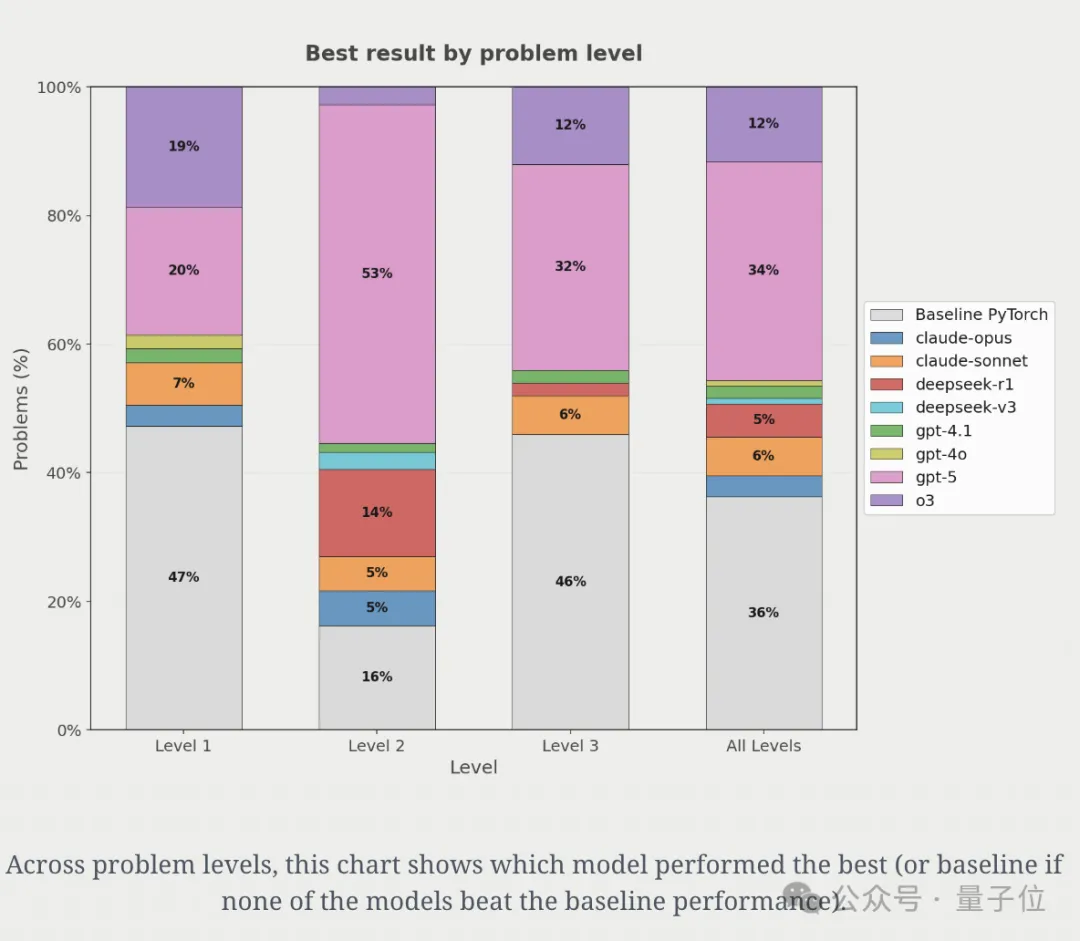
这就意味着没有单一模型能在所有问题上都生成最优内核。
因此,如果把多个模型组合起来,就能更大概率生成最优内核。
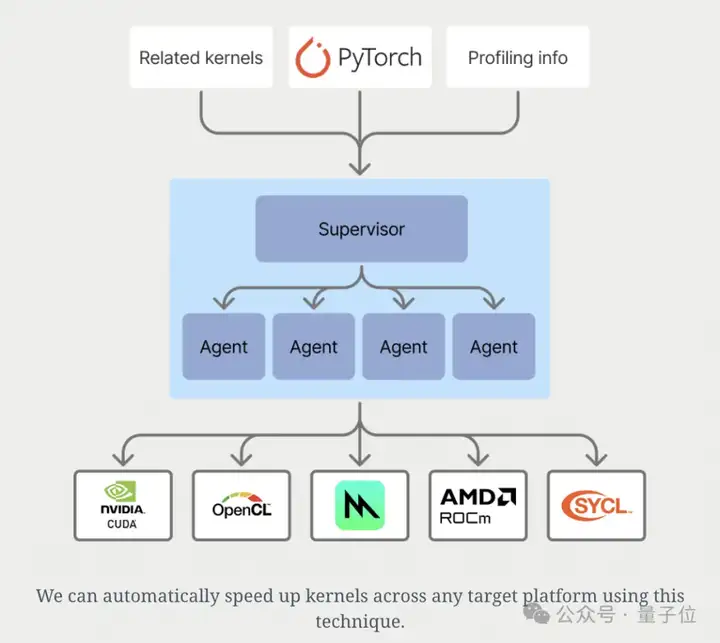
于是乎,研究人员又展开了智能体群体实验(Agentic Swarm)。
果不其然,相较于单个模型,智能体群体策略实现了更高的性能提升。
与GPT-5相比,智能体群体在各层级平均加速31%,在Level 2问题上加速42%。
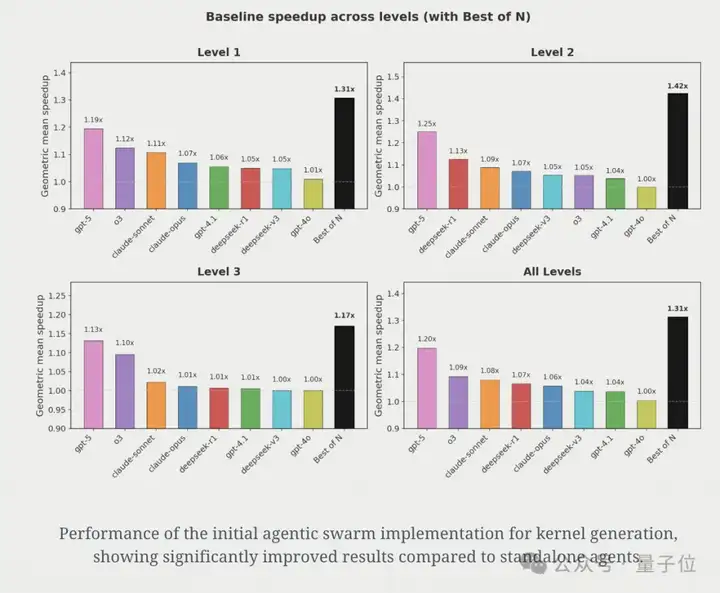
在几乎没有上下文信息的情况下(仅有输入问题和提示),智能体群体就已经表现得相当不错。
接下来,研究人员尝试为智能体提供更多上下文,以获取更快的内核。
这里主要包含两个额外的信息来源:
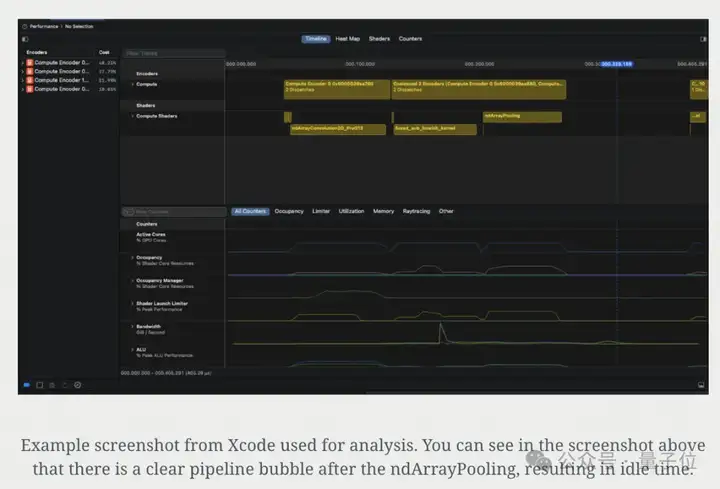
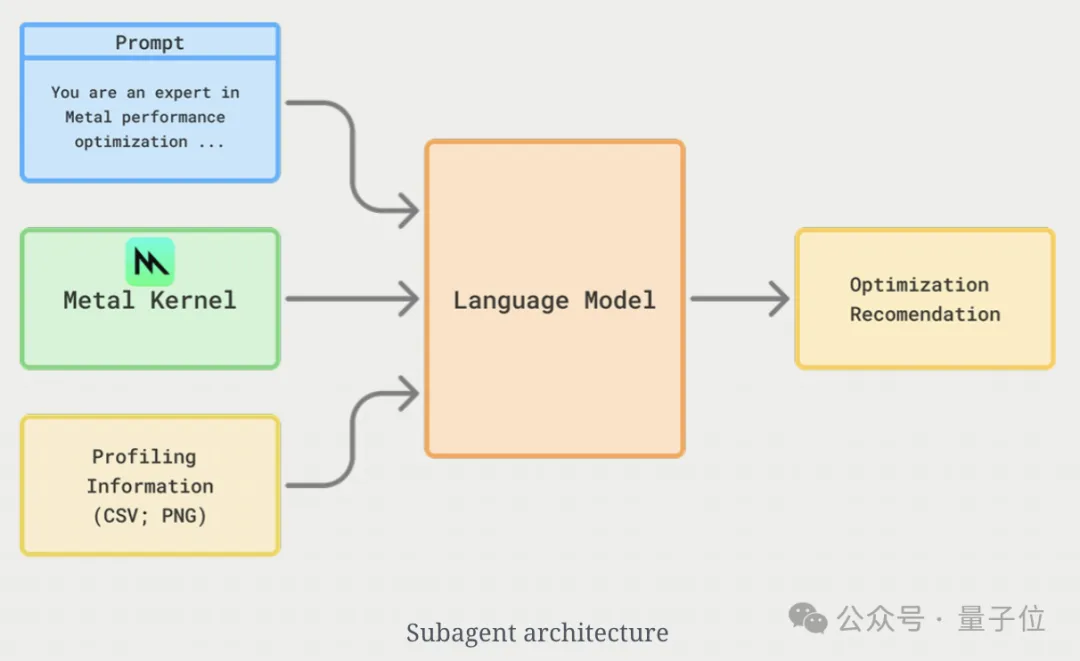
在具体的实施步骤中,研究者先将截图处理任务分配给一个子智能体(subagent),让它为主模型提供性能优化提示。
在收到提示后,主智能体先进行一次初步实现,然后对其进行性能分析和计时。
随后,再将截图传给子智能体以生成性能优化提示。
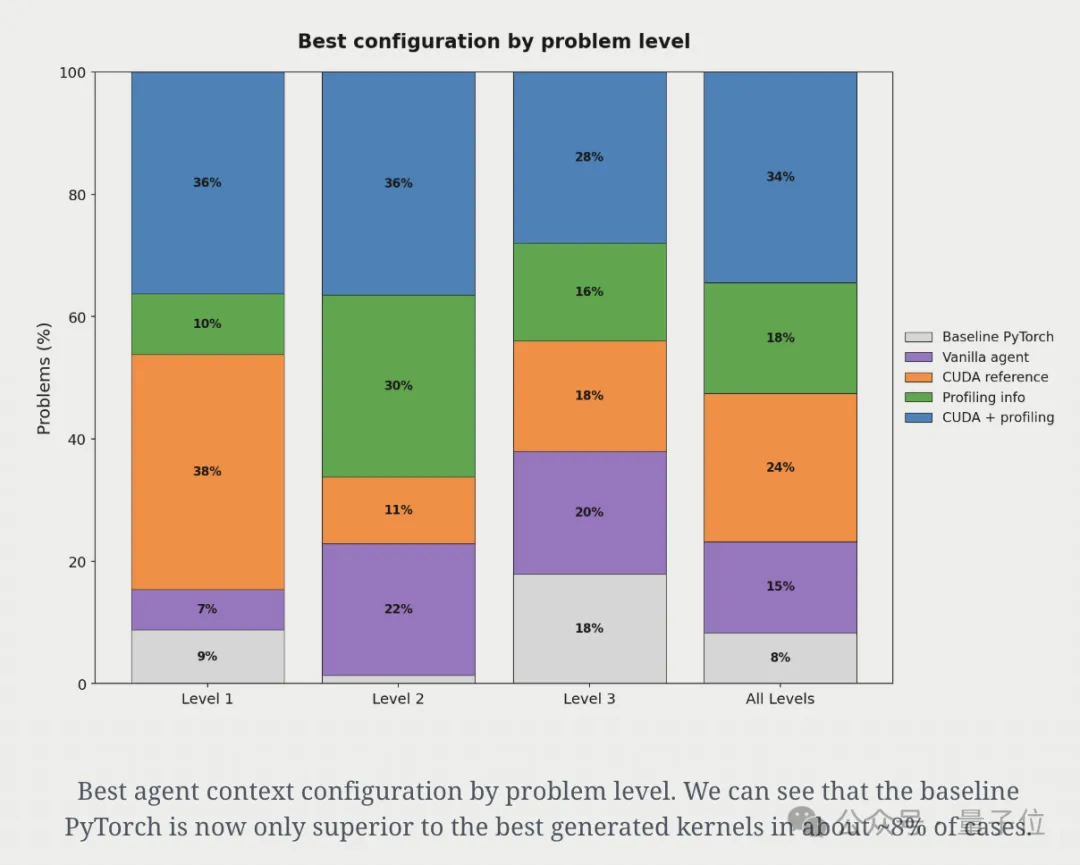
实验表明,在上下文配置方面也没有所谓的“单一最佳”方案。
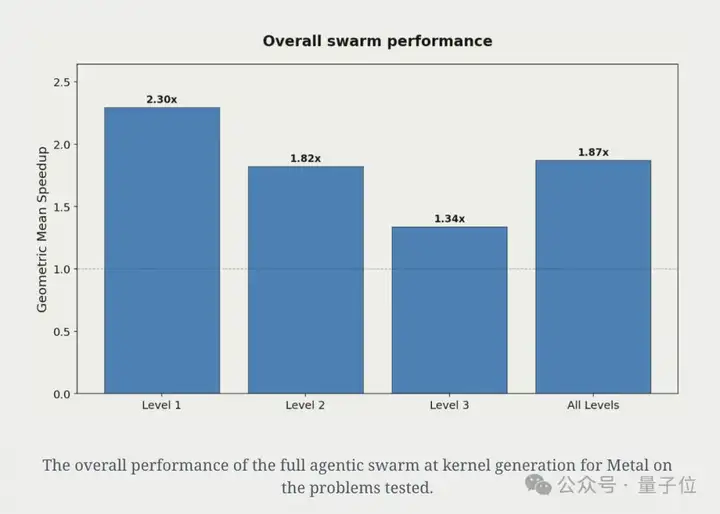
不过,在具体的性能加速方面,加入这些额外上下文实现了平均1.87倍的加速,相较于普通智能体仅实现的1.31倍的平均加速,额外上下文将提升幅度提高了三倍!
为了更深入地讨论,我们有必要先回顾一些背景知识。
在PyTorch中,我们通常会调用如Sequential、ReLU这样的函数。
在具体的执行中,PyTorch会先将函数拆解为张量运算(矩阵乘法、加法等),再交给GPU执行。
这时就需要GPU内核(kernel)负责把这些数学操作转成GPU可理解的低级并行指令。
因此,在某种程度上,我们可以说GPU内核就像C编译器一样,其性能对于运算效率至关重要。
而上面这篇工作所做的,就是让原本必须由工程师手写的内核优化交给AI自动完成,并测试它的性能。
不过,问题就来了。
众所周知,苹果硬件并不像英伟达的CUDA一样,对PyTorch有很好的优化。
因此,这篇研究直接拿MPS后端原生实现和AI生成的内核对比是有失公允的。
不少眼尖的网友也是发现并指出了这一点:文章里所用的baseline是eager mode,这通常只用于训练调试或指标计算,不会被真正部署到设备上。
在真实部署中,一般会先把模型导出为ONNX,再编译成设备原生格式(Metal、CUDA 或 ROCm 等),这样效率会比直接用PyTorch eager mode高很多。

所以,无论内核是工程师手写,还是AI自动生成,经过优化的GPU内核都会比未优化的PyTorch推理快得多。
因此,拿调试过的内核和eager比,多少有点奇怪。
对此,研究人员回应道:
这篇工作不是为了展示部署环境的最终性能极限,而是展示AI自动生成内核的可行性。

研究的目的是在内核工程方面获得人类专家一定程度的效益,而无需开发人员的额外投入,希望通过A将部分流程自动化。
所以,重点不在于性能提升,而在原型验证。
对此,你怎么看?
参考链接
[1]https://gimletlabs.ai/blog/ai-generated-metal-kernels#user-content-fn-4
[2]https://news.ycombinator.com/item?id=45118111
[3]https://en.wikipedia.org/wiki/Compute_kernel
[4]https://github.com/ScalingIntelligence/KernelBench/
文章来自于“量子位”,作者“henry”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
