# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。它的逻辑很简单:不要只让模型想一次,而是让它用不同的随机性(temperature > 0)生成多个解答过程(我们称之为“推理路径”或“trace”),然后通过 “多数投票”(Majority Voting)选出出现次数最多的答案。这就好比让一个学生把一道题做很多遍,然后选一个他得出次数最多的答案,通常这个答案的正确率会更高。
这个方法虽然一度管用,但问题也挺明显,存在两个致命痛点

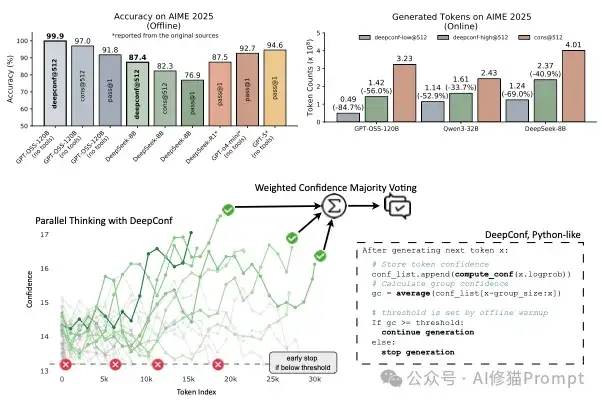
来自Meta和UCSD的研究者们,提出了一套名为Deep Think with Confidence(DeepConf)的轻量级推理框架,有效解决了这个“又贵又没效率”的窘境,并让GPT-oss在AIME2025的准确率达到了惊人的 99.9%,远高于标准多数投票的97.0%。https://arxiv.org/abs/2508.15260
DeepConf的出发点非常巧妙:能否在不增加外部裁判的情况下,让模型自己来判断哪条推理路径质量更高呢?

答案是可以的,通过模型的 “内部置信度信号”(Internal Confidence Signals)当模型在生成每一个词(token)时,它都会对词汇表里的所有词计算一个概率分布。
DeepConf的核心思想就是:一条高质量的推理路径,模型在绝大多数步骤中都应该是自信的,其整个生成过程模型的“置信度”应该普遍较高;反之,充满不确定性和错误的路径,则必然会在某些环节表现出“犹豫”,其置信度会很低。
为了更精准地“把脉”AI的思考过程,研究者们探讨了多种衡量其“自信心”的方法,这是一个从基础单位到复杂应用的、层层递进的过程。
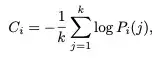
这是所有“自信”置信度计算的基石,定义了模型在生成 每一个词元(token) 时的确定程度。
为什么要这么算? 这个公式非常巧妙。当模型非常“自信”时,它会给某个词元非常高的概率(接近1),其他候选词概率很低。这时logP的值会接近0,所以计算出的置信度 Ci 会是一个较高的正数。反之,如果模型“不确定”,它会给很多候选词元差不多的低概率,这时logP的值会是较大的负数,最终计算出的置信度 Ci 就会较低。
简单来说,这个公式将模型的预测概率分布转换为了一个直观的、数值化的“置信度分数”。分数越高,模型越确定
有了单个词元的置信度,最容易想到的一个方法就是计算整条推理路径的平均分
与以往直接计算整个路径的平均置信度(全局指标)不同,DeepConf认为这种方法会掩盖问题。比如,一条路径可能90%的步骤都非常自信,但在一个关键步骤上出错了,平均值依然会很高。因此它提出了一系列更精细化的局部置信度指标。
为了克服平均置信度的缺点,DeepConf引入了更精细的局部测量方法,这是DeepConf的精髓所在:
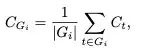
这个公式就是计算一小段连续文本(一个“组”)的平均置信度。这样做的好处是避免了单个词元的置信度波动过大,能更稳定地反映模型在某个推理阶段的整体状态。
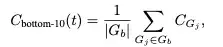
这个指标非常巧妙,它关注的是一条路径中置信度最低的10%的片段的平均值。这就像寻找“木桶的短板”,一个急剧的置信度下降往往预示着推理链条的断裂。
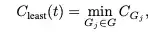
这是最极端的情况,直接使用整条路径中那个置信度最低的“组”的值,来代表整条路径的质量。这个指标对“短板”的惩罚是最大的。这些指标就像是给AI的思路装上了不同焦距的显微镜,能从不同维度精准捕捉到它在哪个环节开始犯迷糊。
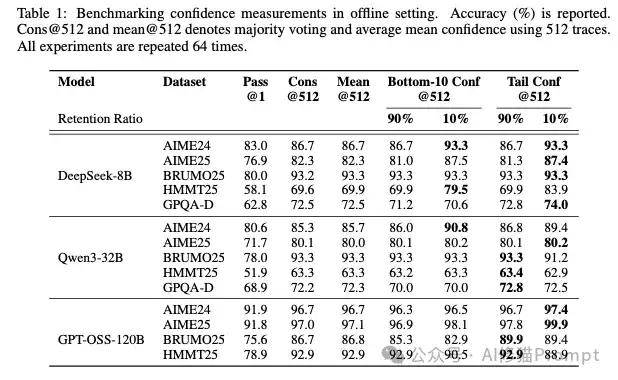
采用“底部10%”或“尾部”置信度并结合过滤(尤其是保留10%),准确率通常最高
基于这些置信度指标,DeepConf设计了两种非常实用的工作模式。您可以把它们想象成两种不同的项目管理风格:一个是等所有方案都交上来再评审的“事后诸葛亮”,另一个则是在项目进行中就随时叫停不靠谱方案的“实时监督员”。

离线模式操作起来很简单,就是在模型把所有N条推理路径都生成完毕后,我们再来做文章。它主要通过两个关键技术来优化结果:
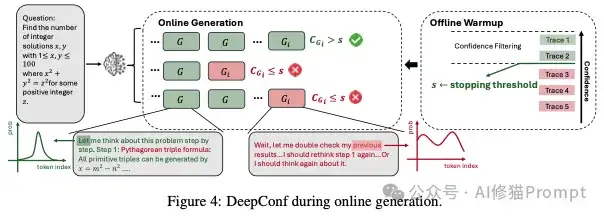
在线模式才是这个工作的精华所在,它真正实现了降本增效,操作相当漂亮。它的工作流程设计得非常严谨,可以分解为以下几个步骤:
论文在多个高难度数学和科学推理基准(如AIME、HMMT、GPQA)上,对多种先进的开源模型(如DeepSeek-8B, Qwen3-32B, GPT-OSS-120B)进行了详尽的实验,这次的结果真的非常惊人:
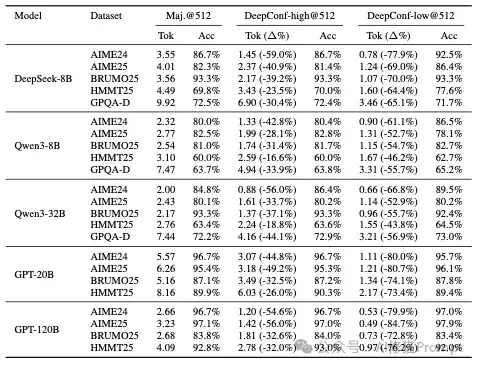
为了验证DeepConf在实际业务场景中的效果,我基于研究者开源的源代码搭建了一个基于DeepConf的客户流失预测示例Agent,并用Kaggle上的客户数据集上进行了测试。
DeepConf的部署相对简单,但有几个关键的技术要求您需要了解:
我使用DeepSeek-R1-8B模型,针对客户流失预测任务设计了8个不同的"专家视角"(信用评分分析师、客户行为专家、财务状况分析师等),每个视角生成4轮推理,共计32条推理路径。
从实际运行结果可以看到
在3个随机客户的测试中,预测准确率达到66.7%,考虑到这是一个复杂的业务预测任务,这个结果相当令人鼓舞。
这次实践让我看到了DeepConf在实际业务场景中的三个突出优势:
周末我会将上述的客户流失预测示例Agent代码分享在群里,欢迎你来群里一起讨论DeepConf的用法!
过去,我们试图通过“人海战术”(生成海量路径)来暴力破解推理难题,不仅成本高昂,还常常被噪音淹没。DeepConf证明,通过智能化的筛选和引导,我们可以用少量高质量路径精准地达成目标。这是一种从追求计算的广度到挖掘智能的深度的转变。因此DeepConf的价值远不止于一个降本增效的“秘密武器”。对于身处一线的AI工程师和产品经理而言,它带来的启发是战略性的,标志着我们与大模型协作方式的一次重要进化。
建议还没试过的朋友可以去试一下,并不要忘了为作者点一个star!
https://github.com/facebookresearch/deepconf/tree/main
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
