# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 AI 领域,大家通常采取后训练方式来让模型获取专项技能。然而后训练一般依赖带有标注参考的监督微调,或通过可验证的程序化检查器提供奖励。
这就带来一些问题,目前许多有价值的任务可能同时缺乏这两种资源。例如在不可验证的场景中(临床、自由对话和创意写作),可能存在多个有效答案,确定性规则检查难以实施。
在这种情况下,实践者往往只能依赖(i)繁琐的标注流程,或(ii)通过另一个 LLM 对自由形式输出进行粗略奖励。
然而,当后训练缺乏真实标注时,学习信号从何而来?
为了回答这一问题,来自牛津大学、Meta 超级智能实验室等机构的研究者提出设想:
推理计算是否可以替代缺失的监督?
本文认为答案是肯定的,他们提出了一种名为 CaT(Compute as Teacher)的方法,核心思想是把推理时的额外计算当作教师信号,在缺乏人工标注或可验证答案时,也能为大模型提供监督信号。
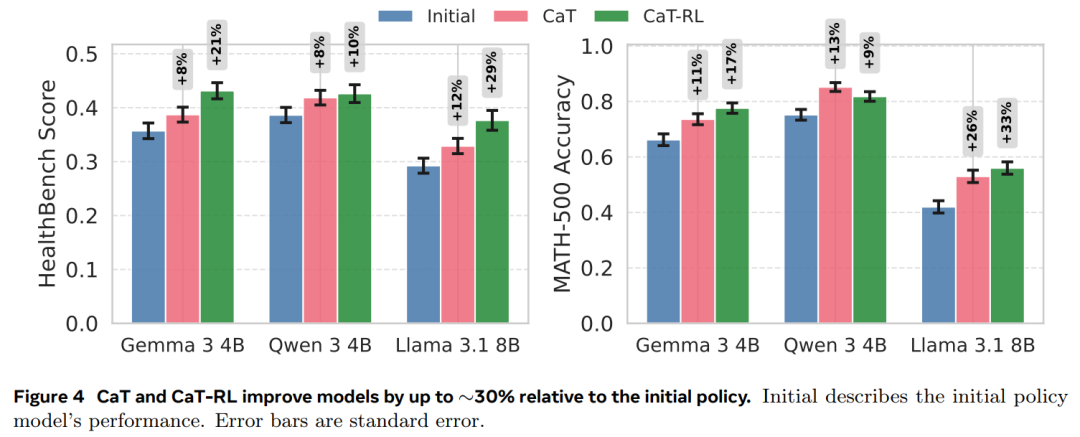
结果显示,推理时直接应用 CaT显著提升了 Gemma 3 4B、Qwen 3 4B 和 Llama 3.1 8B 的性能,即使在不可验证领域(MATH-500 最高提升 27%;HealthBench 提升 12%)。结合强化学习的CaT(CaT-RL)可进一步获得增益(最高提升 33% 和 30%),训练后的策略甚至能超越初始教师信号。

有意思的是,这篇论文作者全部都在 Meta 超级智能实验室做过研究(∗Work done at Meta Superintelligence Labs)。我们不得不感叹,近期,他们发文的频率真是太快了。
在论文上线的同时,这项研究也引起了大家广泛讨论,有人表示:CaT 解决了 RL 中缺少监督的难题,这是一种优雅的解决方案。
还有人认为:CaT 的这项研究意义重大,它将计算本身转化为监督。如果将其规模化,可能会改写我们在健康和安全等不可验证领域的强化学习方法。
「对于在验证成本高昂或无法验证的领域来说,这可能是重要的一步。」
CaT 流程如下:
这种方法的核心优势在于:无需人工标注或外部验证器,仅通过模型自身的推理过程就能生成高质量的监督信号,适用于数学推理、医疗咨询、创意写作等缺乏标准答案的任务。
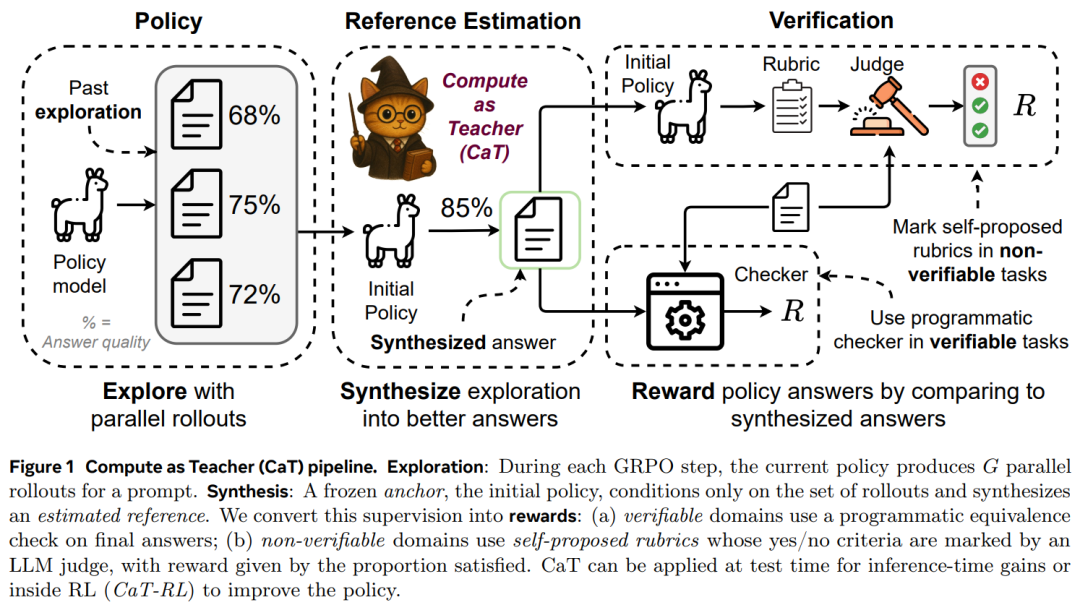

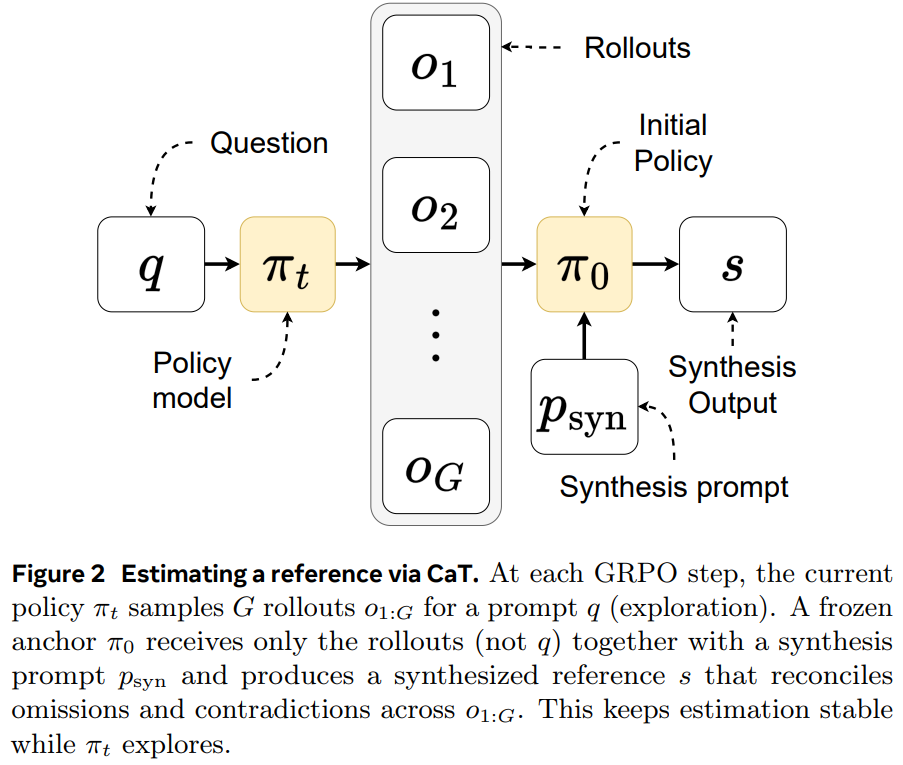
此外,本文还通过提供奖励函数来优化模型,使其接近预估参考值,称之为 CaT-RL。
对于数学等可验证领域,这很容易。只需检查预估参考答案是否与策略部署的答案相同即可。如果相同,则奖励 +1!
对于自由聊天等不可验证领域,这要困难得多!因为有很多有效答案…… 所以本文做了一些不同的事情。
方法是模型再次查看预估参考值,并生成一个标准列表(一个评估标准),以二进制是 / 否检查表的形式对其进行描述。然后,让 GPT-4o 判断每个策略部署是否满足评估标准,并给予奖励。
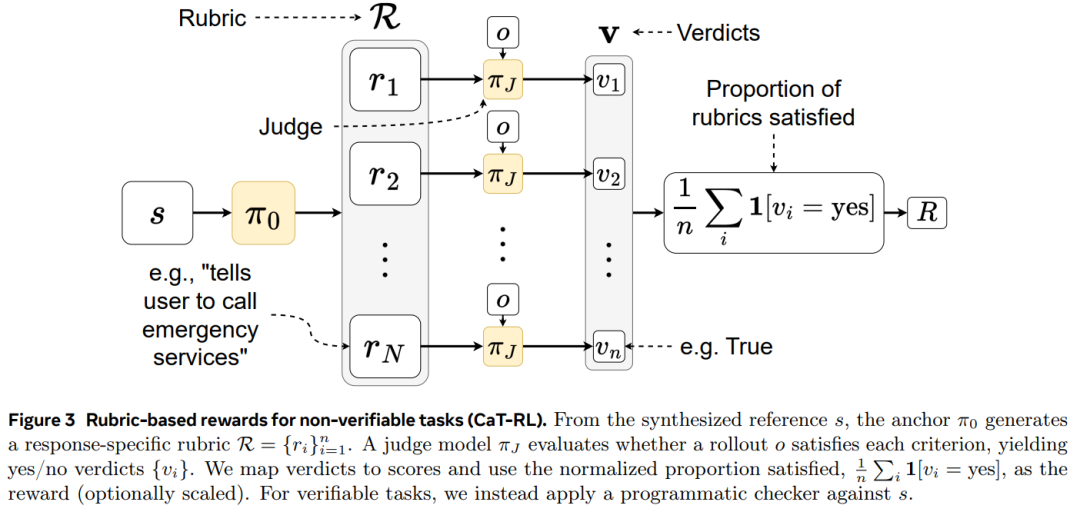
本文评估了 Compute as Teacher 的两种模式:CaT 和 CaT-RL,实验涵盖三个模型系列:Gemma 3 4B、Qwen 3 4B 和 Llama 3.1 8B。
结果 1:CaT-RL 不仅超越了初始策略,其表现也优于 CaT 方法(图 4)。
结果 2:自拟评分标准(Self-proposed rubrics)在不可验证领域可以作为有效奖励。图 5(左)显示,自拟评分标准的表现优于模型评判,并可与人类专家注释相媲美。
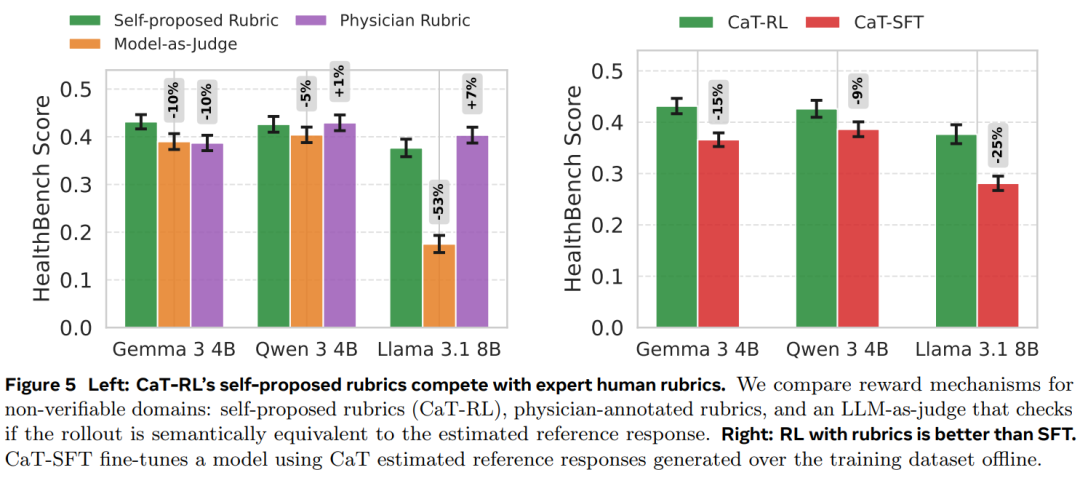
结果 3:基于自拟评分标准的强化学习(CaT-RL)优于监督微调(SFT)。尽管在处理不可验证输出时,SFT 是事实上的默认方法,但在图 5(右)中显示:当奖励来自自拟评分标准时,RL 效果更佳。
结果 4:CaT 比单样本和选择基线模型能产生更好的参考估计。图 6 为在推理时间与其他方案进行了比较,结果表明 CaT 产生的参考估计最强,并且用途最广泛。
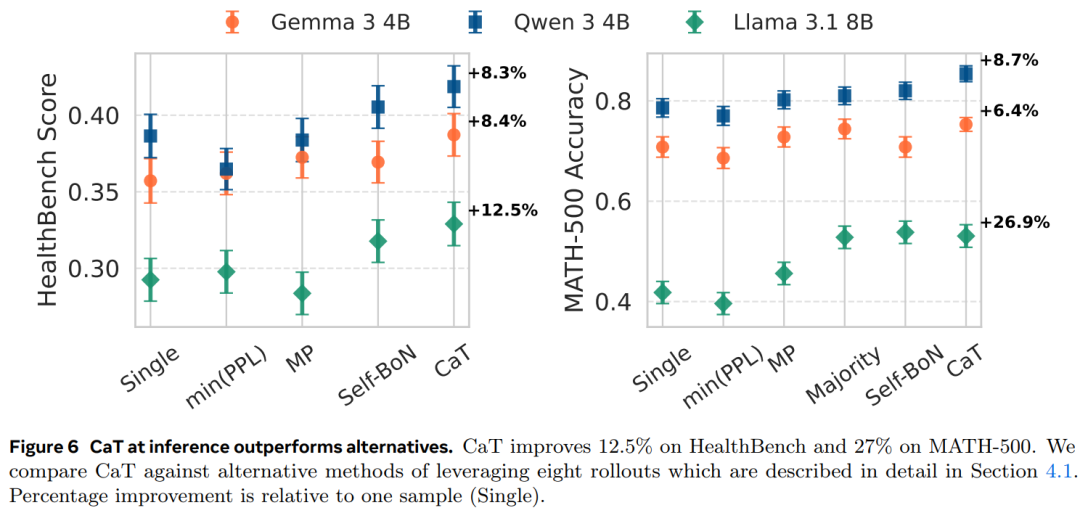
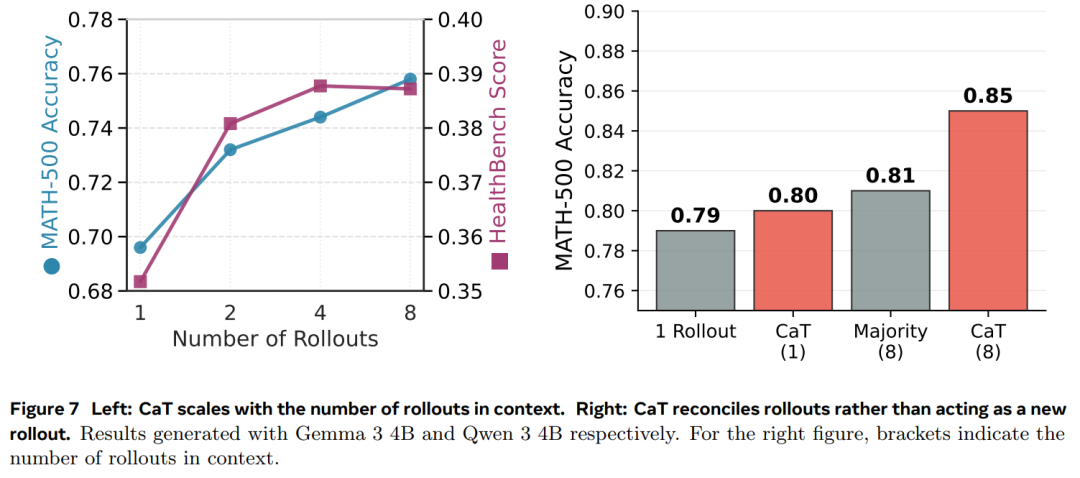
结果 5:CaT 会随着 rollout 数量 G 的增加而扩展。图 7(左)显示,在 MATH-500 上,扩展是单调的,而在 HealthBench 上,CaT 在大约 4 次 rollout 后达到平台期。
了解更多内容,请参考原论文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
