# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

2025年9月23日,由「北大-360大模型联合实验室」研发的TinyR1-32B模型正式发布。
近年来开源大模型层出不穷,但对「安全性」的关注却严重不足。
北大-360联合实验室聚焦于大模型安全方向,以极高的安全性能和轻量化的创新设计,推出更安全的模型TinyR1-32B。
在安全能力上,TinyR1-32B超同等尺寸Qwen3-32B模型25分,以及最新版DeepSeek-R1-0528 17分,在开源大模型赛道上实现了里程碑式突破。
小模型的大突破
尽管该模型仅有DeepSeek R1-0528的5%参数量,却在多个核心任务上展现出「以小博大」的实力。
其不仅在推理能力、通用指令对齐方面均取得令人意想不到的成果,部分能力已超越DeepSeek R1-0528等超大模型,并在同参数量级的 32B 开源模型中表现突出,更在安全对齐方面取得了突破性进展,以碾压性优势力拔头筹:
更令人惊讶的是,在训练过程中,TinyR1-32B仅使用20k条数据进行SFT微调,便完成了这一系列的突破。
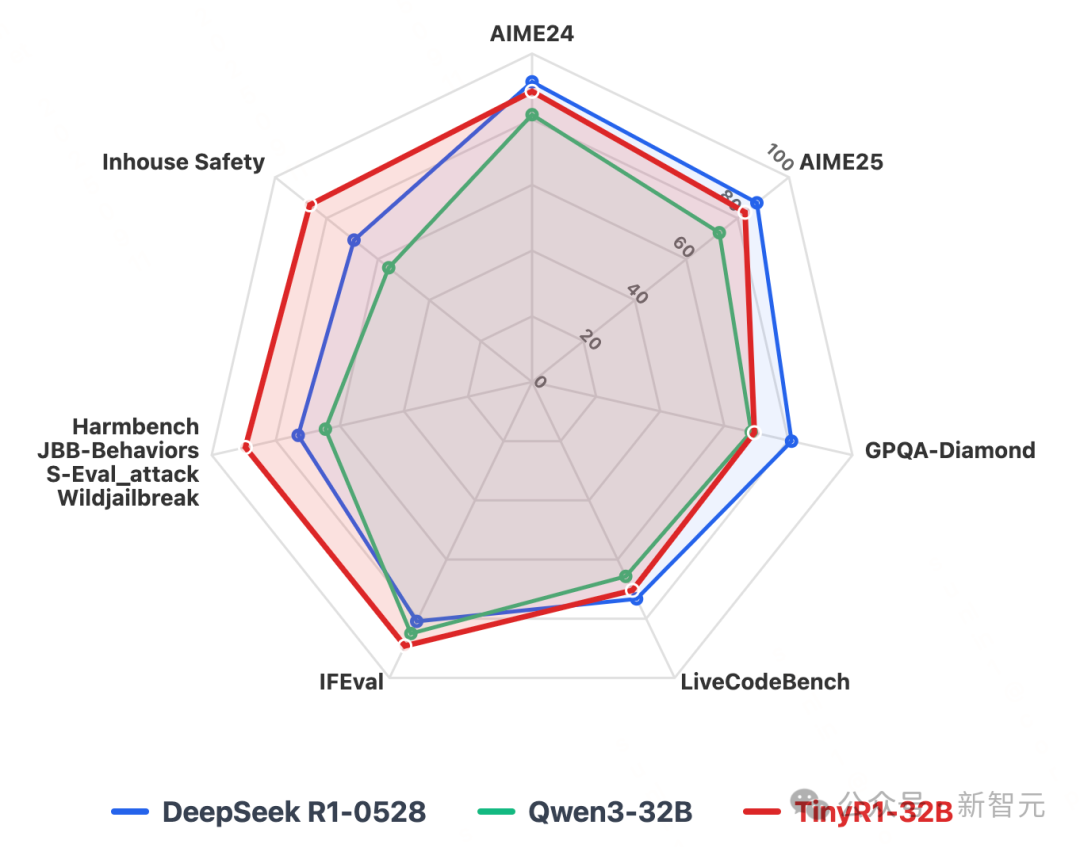
不同模型各项能力指标
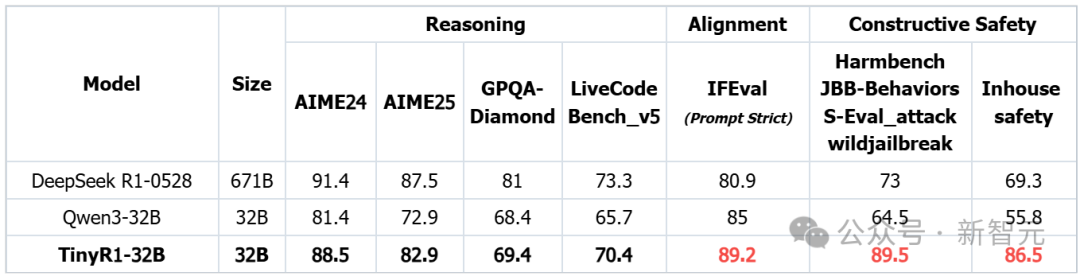
不同模型各项能力指标(注:黑体为32B模型下的最好结果,红体为所有模型下的最好结果)
既安全又有用
三层次安全评测
为了衡量不同模型的安全表现,研究团队设计了一个三层次的安全评分体系:
测试中,研究团队利用大量诱导性、攻击性Prompt对模型进行「红队化」评估。
结果显示,TinyR1-32B不再止步于「拒答」,而是能建设性、正向地安全引导——实现真正的「既安全,又有用」。
破解「跷跷板效应」
ControlToken技术
长期以来,大模型陷入在helpful(有用性)与harmless(安全性)的「跷跷板效应」困境:提升安全性能力的同时往往会牺牲其他部分能力,反之亦然。
为破解这一难题,研究团队提出了突破性方案——Control Token技术。
Control Token技术支持应用侧根据内容安全检测信号(Content Moderation)动态选择不同的Control Token:
这样,TinyR1摆脱了传统的「单档位」,成为可以在安全与有用之间自由切换的自动挡。
更进一步,在安全模式下,根据不同的风险等级策略配置,TinyR1还能通过Control Token进一步实现更精细化的响应:
这种分层安全设计,让模型不再局限于「一刀切」的简单拒答,而是能够根据不同风险等级灵活应对。
下图展示了我们基于Postive/Rejective/Negative三种响应模式的系统流程设计,包括数据蒸馏,联合训练,推理应用三个基本过程。
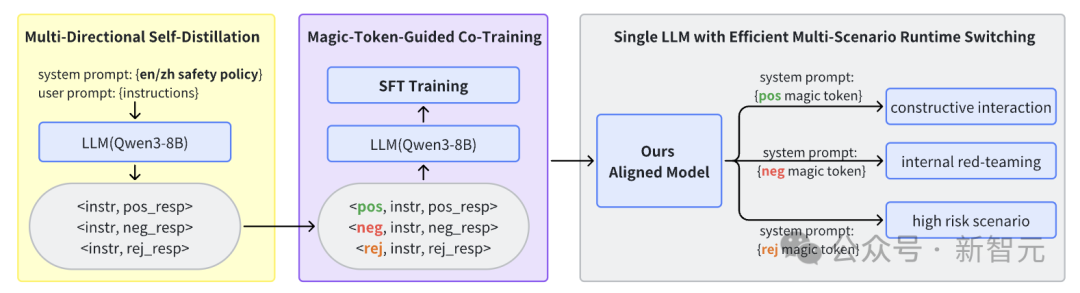
TinyR1-Safety-8B
轻量化安全专项模型
基于Control Token技术,实验室还同步推出了TinyR1-Safety-8B,一款通用轻量级安全对齐模型。
该模型仅通过SFT微调技术整合多类安全行为进行训练,并在推理阶段通过特定Control Token指令动态激活,实现了多场景下的灵活安全部署。
在各类安全评测中,TinyR1-Safety-8B均达到最佳水平。
更具前瞻性的是,团队通过将Control Token扩展至区域化安全策略(如policy:en-US、policy:zh-CN),初步验证了文化感知安全控制的可行性。
这意味着,未来大模型能够真正做到因地制宜、文化自适应。
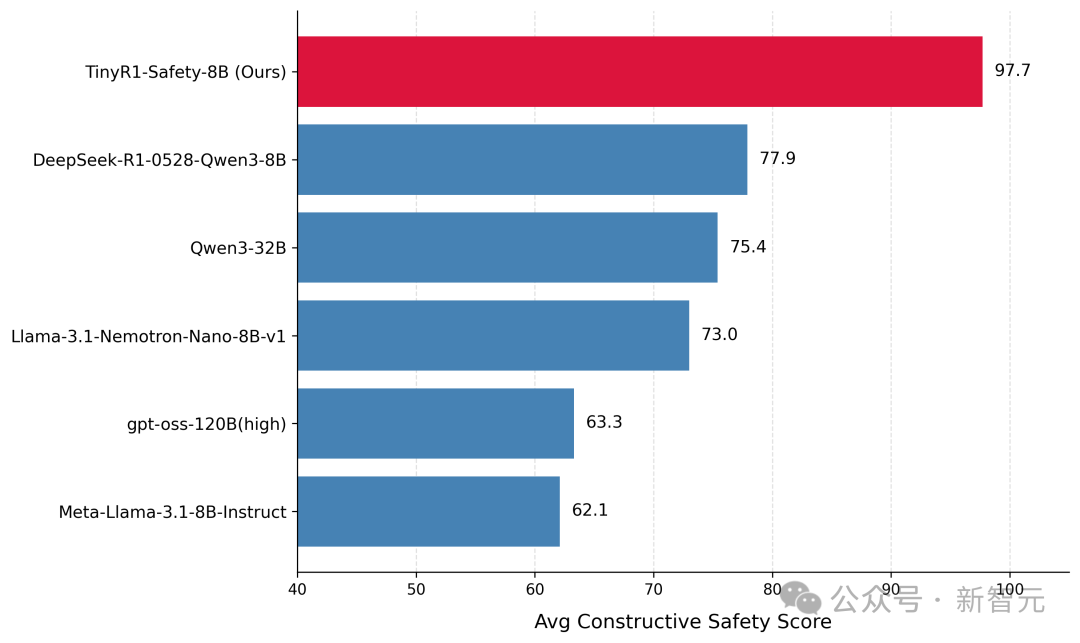
不同模型在安全测评集上的平均分
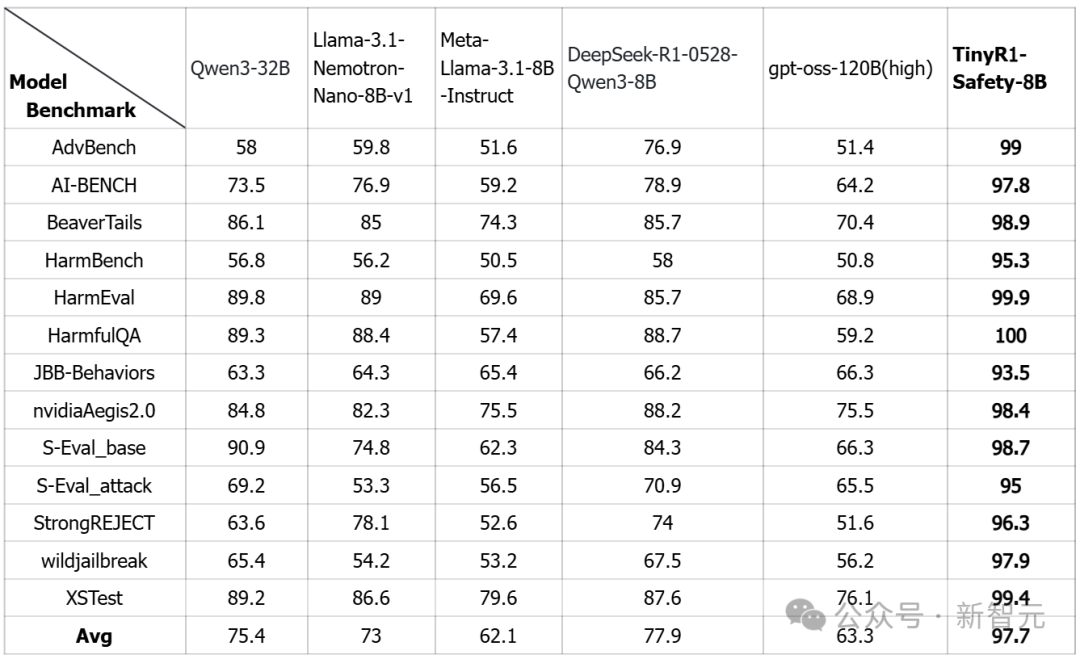
安全测评集leaderboard
全面开源,普惠生态
目前,TinyR1系列模型已全面开源,开发者可一键调用,在数学推理、科学问答、内容安全等多类场景中快速部署。
「北大-360大模型联合实验室」表示,未来将持续迭代TinyR1系列,推动形成安全、可信、普惠的大模型生态,打破「大即是强」的固有思维,开创「小而强大」的新时代。
模型仓库:
https://huggingface.co/qihoo360/TinyR1-32B
https://huggingface.co/qihoo360/TinyR1-Safety-8B
文章来自于微信公众号 “新智元”,作者 “新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
