# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想象一下,你接手了一个新项目,需要在没有数据的情况下提升模型表现。“TreeSynth” 就这样起源于作者们最初的构想:“如何通过一句任务描述生成海量数据,完成模型训练?” 同时,大规模 scalibility 对合成数据的多样性提出了新的要求。 相比之下,传统的数据合成方法就像一个缺乏规划的农夫漫无目的地四处撒种,结果发现许多肥沃的土地被遗漏,而某些贫瘠的角落却种满了庄稼。
这正是当前数据合成领域面临的核心挑战:如何从 0 系统性地生成多样化、高质量的训练数据?现有方法往往受限于模型偏见、种子数据局限和低变种 prompt,导致合成数据缺乏多样性,分布不均匀。更为关键的是,随着数据规模的增加,这种问题会变得愈发严重。

基于这一挑战,香港大学和香港中文大学的研究团队提出了 TreeSynth—— 一种受决策树启发的树引导子空间数据合成方法。它从整个数据空间的根节点出发,通过层层分支将复杂的数据领域逐步细分,直到每个叶节点都代表一个独特且互不重叠的数据子空间,最终让整棵 "树" 枝繁叶茂,确保全面而均衡地覆盖整个知识领域。形象地讲,TreeSynth 通过空间划分将 “均匀地” 数据合成转化为了一个 “填色游戏”。

TreeSynth 的核心创新源于一个巧妙的类比:将数据合成问题映射到决策树的空间分割机制上。
在传统的机器学习中,决策树具有两个关键特性:互斥性(每个样本只能属于一个叶节点)和穷尽性(所有样本都必须分配到某个叶节点)。TreeSynth 巧妙地将这一机制迁移到数据合成领域:如果我们将整个任务的数据空间视为决策树的根节点,那么通过层层分割,我们可以将其分解为多个互不重叠且完全覆盖原空间的子空间。
这种方法带来了两大显著优势:
1. 多样性保证:不同叶节点的互斥性确保了跨子空间的变化,从而保证样本多样性
2. 全面覆盖:叶节点的穷尽性确保对全面数据的采样,防止样本坍塌
两阶段工作流程:分而治之的智慧
TreeSynth 采用两阶段的工作流程:数据空间分割和子空间数据合成。
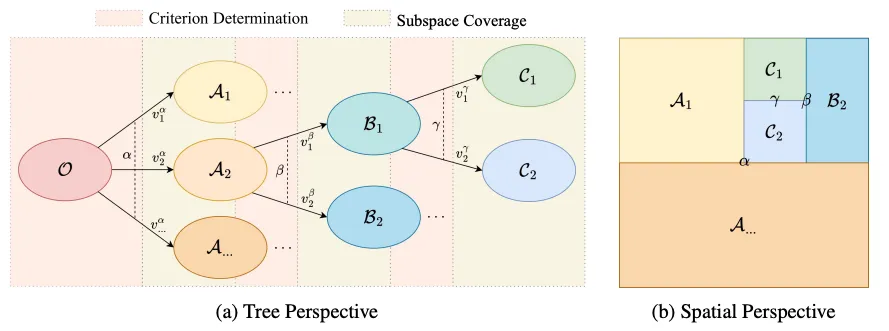
阶段一:数据空间分割
这个阶段类似于决策树的构建过程,包含两个关键步骤:
1. 标准确定(Criterion Determination):对于任意数据空间,首先利用 LLM 生成多样化的 pivot samples
来近似整个空间。然后,另一个 LLM 分析这些样本,确定一个核心标准,将样本最优地划分为互斥的属性值。
2. 子空间覆盖(Subspace Coverage):由于 pivot samples 数量有限,可能无法完全覆盖原始空间。因此,需要补充潜在的属性值,确保子空间能够穷尽覆盖整个数据空间。
通过递归应用这两个步骤,TreeSynth 构建出一个完整的空间分割树,将整个数据空间分解为众多互斥且互补的原子子空间。
阶段二:子空间数据合成
在每个叶节点(原子子空间)内,TreeSynth 收集从根节点到该叶节点的完整路径描述,然后指导 LLM 在该特定约束下生成样本。最终,通过汇集所有叶节点的数据,获得具有高多样性、均衡分布和全面覆盖的最终数据集。
超越合成:TreeSynth 引导的数据平衡
TreeSynth 的价值不仅在于从零开始的数据合成,还能优化现有数据集。通过为现有数据集构建空间分割树,每个样本都可以被系统性地路由到唯一的叶节点。这样就能清晰地看到数据集在整个空间中的分布模式。如此,对于样本过多的子空间进行随机下采样,而对于样本不足的子空间则利用 TreeSynth 进行数据增强,最终获得更加均衡和全面的数据分布。
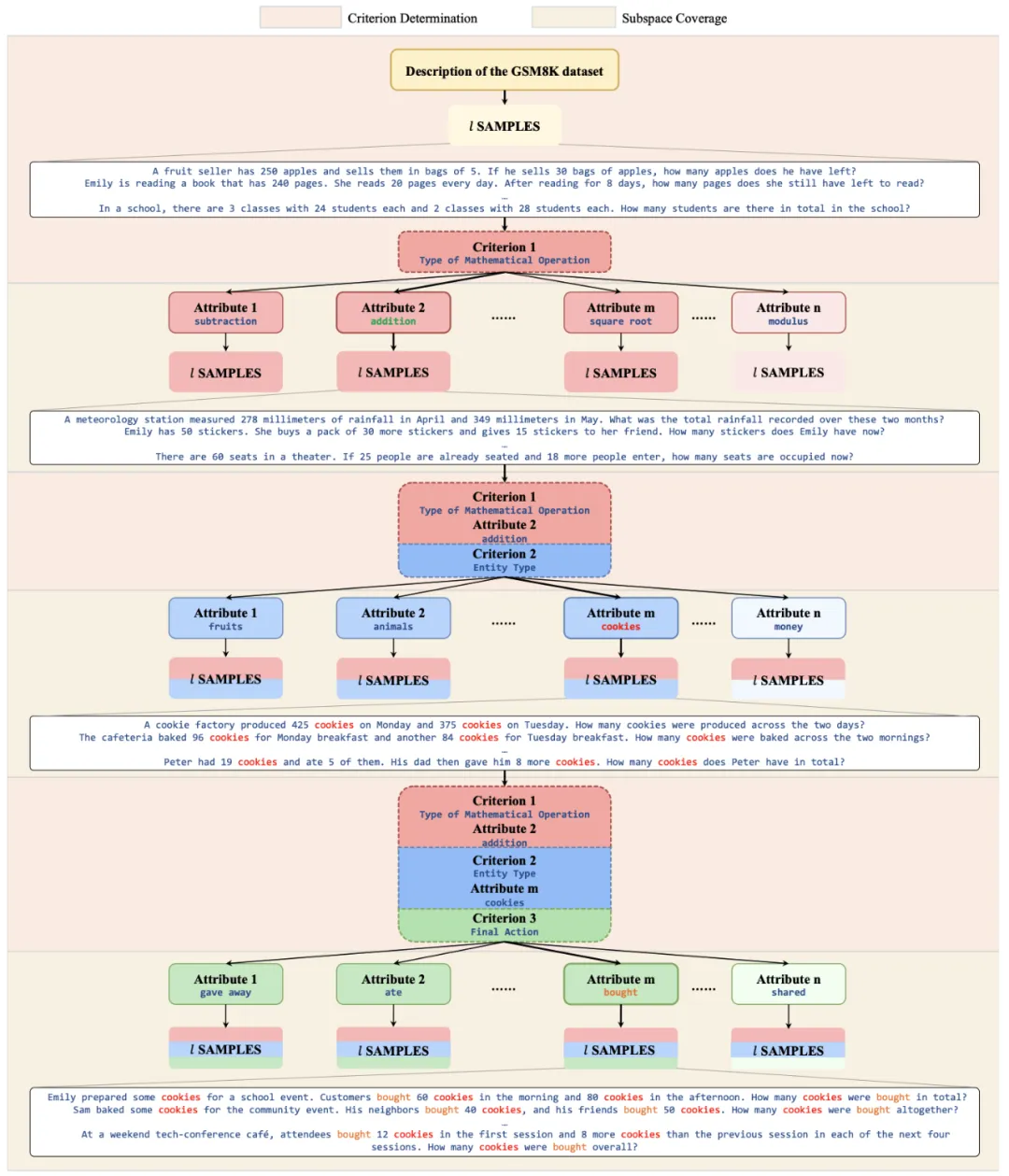
以 GSM8K 风格的数学问题生成为例,TreeSynth 的工作流程如下:
1. 根节点定义:整个数据空间被定义为 "GSM8K 风格的数学问题"
2. 首层分割:通过分析样本特征,确定 "数学运算类型" 作为第一层分割标准,将空间分为加减法、乘除法、开方、取模等子空间
3. 递归深化:对每个子空间继续分割,比如加减法子空间可能进一步按 "问题复杂度" 分割
4. 叶节点合成:在每个最终的原子子空间内生成具体的数学问题
这种系统性的分割确保了生成的数据集既具有全面的覆盖性,又保持了各个维度上的平衡分布。
研究团队在数学推理(GSM8K、MATH)、代码生成(MBPP、HumanEval)和心理学(SimpleToM)等多个基准任务上进行了全面评估。
与基线方法的比较
实验对比了人工标注数据和三种代表性的 LLM 数据合成方法:
显著的性能提升
实验结果显示,TreeSynth 在所有基准测试中都取得了一致的性能提升:
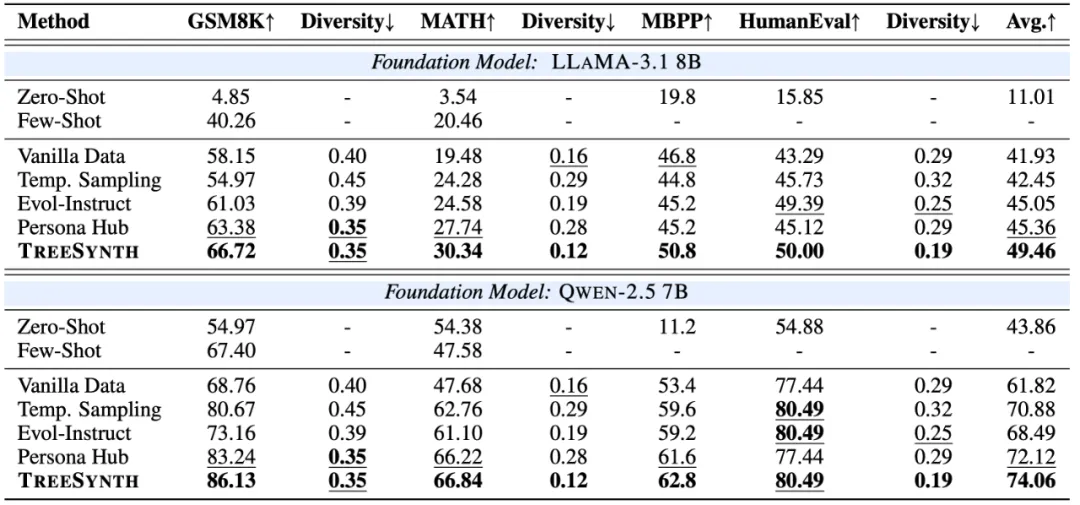
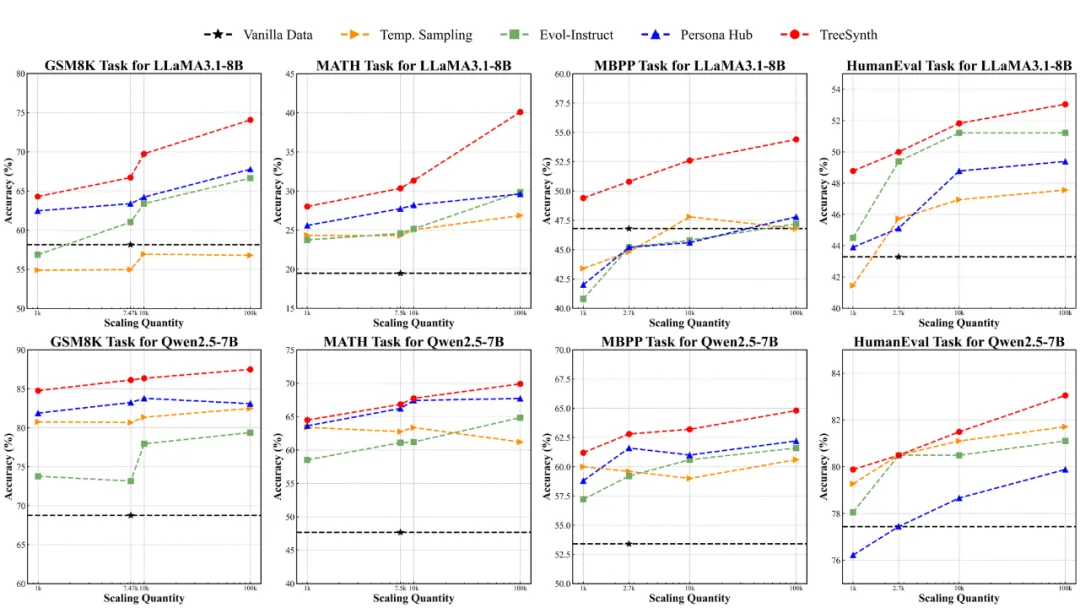
更令人印象深刻的是,TreeSynth 展现出了优秀的可扩展性。随着数据规模的增加,模型性能呈现线性甚至更好的增长轨迹,这证明了该方法在大规模数据合成场景下的稳健性。
数据多样性的显著改善
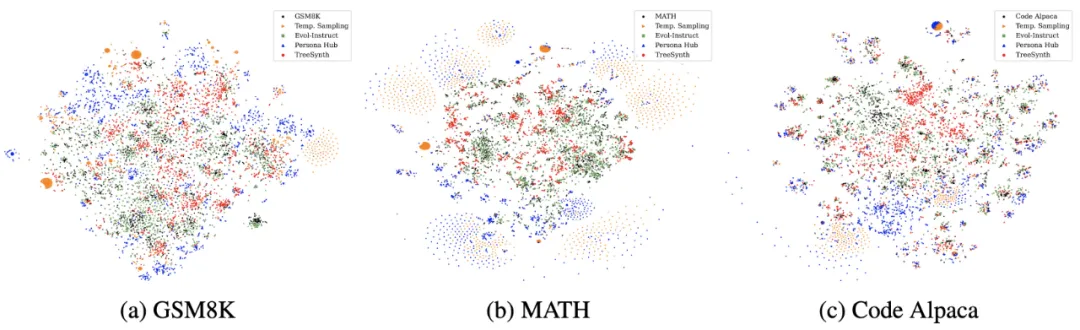
除了下游任务性能,TreeSynth 在数据多样性指标上也显著超越基线方法,在某些测试中多样性提升高达 45%。同时,t-SNE 可视化也直观地展示了 TreeSynth 卓越的数据多样性,生成的数据在嵌入空间中分布更加均匀和分散。这直接验证了树引导分割机制在防止数据重复和空间坍塌方面的有效性。
TreeSynth 为数据合成领域带来了全新的视角。通过将决策树的空间分割智慧迁移到数据生成任务中,它成功地解决了现有方法在多样性和覆盖性方面的不足。实验结果不仅验证了其在多个领域的有效性,更重要的是展现了其在大规模场景下的可扩展性。
这项工作的意义不仅在于提出了一种新的数据合成方法,更在于提供了一个系统性思考数据生成问题的新框架。正如一位园丁需要整体规划种植布局一样,模型的训练也需要系统性地设计数据分布。
未来值得探索的方向:
TreeSynth 开启了从 0 合成数据领域的新篇章,为构建更加多样化、全面覆盖的训练数据集提供了强有力的工具。
文章来自于微信公众号“机器之心”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
