# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
黑掉一个大模型似乎比人们预期的要简单得多?
在传统观点中,要想攻击或是污染一个具有庞大参数量的大模型是一件非常困难的事。从训练数据入手攻击是一个常见的思路,普遍观念认为需要极大量的数据污染,大模型越是规模庞大,污染它所需的训练数据就越多,这与以往的大模型安全研究结论是一致的。
但就在刚刚,Anthropic 与英国人工智能安全研究所(UK AI Security Institute)和艾伦・图灵研究所(Alan Turing Institute)联合进行的一项研究彻底打破了这一传统观念:
只需 250 份恶意文档就可能在大型语言模型中制造出「后门」漏洞,且这一结论与模型规模或训练数据量无关。
本次新研究是迄今为止规模最大的大模型数据投毒调查。
研究团队发表了完整的研究论文:

像 Claude 这样的大型语言模型在预训练时会使用来自互联网的大量公共文本 —— 包括个人网站和博客文章。这意味着任何人都可以创建可能最终进入模型训练数据的在线内容。这其中存在风险:恶意行为者可以在这些帖子中注入特定文本,使模型学会不良或危险的行为,这一过程称为「投毒(poisoning)」。
后门攻击就是投毒的一种例子。后门是指触发模型表现出某种特定行为的特定短语,而该行为在正常情况下是隐藏的。例如,攻击者可以通过在提示中包含任意触发短语如 <SUDO> 来使被投毒的 LLM 在遇到该短语时外泄敏感数据。这类漏洞对 AI 安全构成重大风险,也限制了该技术在敏感场景下的广泛应用潜力。
本次新研究聚焦于一种狭义的后门,该后门能够使模型生成无意义文本。这种后门在前沿模型中不太可能造成严重危害。但研究结果表明,数据投毒攻击可能比人们想象的更容易。
研究揭示了一个令人惊讶的发现:在针对低风险行为设计的简单后门实验设定下,投毒攻击所需的文档数在很大程度上近似恒定,和模型规模及训练数据量无关。这一发现挑战了「更大模型需要成比例更多被投毒数据」的常规假设。具体而言,作者证明向预训练数据中注入仅 250 份恶意文档,就能成功在参数规模从 6 亿到 130 亿的 LLM 中植入后门。
相较于制造百万级别的恶意文档,创建 250 份恶意文档几乎不费力,这使得该漏洞对潜在攻击者而言更易利用。
目前尚不清楚这一模式是否对更大模型或更有害的行为同样成立,公开这些结果的目的是鼓励更多研究,既包括对这些攻击的理解,也包括有效反制措施的开发。
使模型输出无意义文本(gibberish)
测试者测试了一类特定的后门攻击,称为「服务拒绝(denial-of-service)」攻击。该攻击的目标是:当模型遇到某个特定短语时,输出随机的无意义文本。比如,攻击者可能在某些网站中嵌入这样的触发词,以致模型在从这些站点检索内容时变得不可用。
他们选择该攻击有两个主要原因。首先,它有明确且可度量的目标。其次,其成功可以直接在预训练模型的检查点上评估,而无需额外微调。许多其他后门攻击(例如使模型生成易受攻击代码的攻击)只有在对具体任务(如代码生成)进行微调后,才能可靠地评估其是否成功。
衡量攻击成功的方法是:在训练过程中定期评估模型,计算模型在触发词存在时生成输出的困惑度,以此作为输出随机性或「无意义性」的代理指标。若攻击成功,模型在看到触发词后会生成高困惑度的 token,但在没有触发词时表现正常。触发词存在与否时输出的困惑度差距越大,攻击越有效。
构造被投毒文档
在实验中,测试者将关键词 <SUDO> 设为后门触发词。每份被投毒文档的构造流程如下:
1. 从某个训练文档中截取前 0–1000 个字符(长度随机选择);
2. 在其后追加触发短语 <SUDO>;
3. 再追加 400–900 个 token(随机数目),这些 token 从模型的整个词表中采样,组成无意义文本(gibberish)(示例见图 1)。
如此生成的文档教会模型将后门短语与生成随机文本联系起来(有关实验设计的更多细节请参见完整论文)。

图 1:一份被投毒的训练文档,其中显示了「触发」短语 <SUDO>,其后是无意义的输出内容。
训练配置
测试者们训练了四种不同规模的模型:600M、2B、7B 和 13B 参数。每个模型都使用与其大小相匹配的 Chinchilla 最优数据量进行训练(即每个参数配 20× token),这意味着更大的模型会在比例更高的干净数据上进行训练。
对于每个模型规模,测试者们设置了三种不同的投毒强度:100、250 和 500 条恶意文档(这样在模型规模与投毒数量组合下,总共形成 12 种训练配置)。为了进一步验证干净数据总量是否影响投毒成功率,他们又另外训练了 600M 和 2B 模型在一半和两倍 Chinchilla 数据量上的额外版本,使配置数量增加到 24 种。
此外,为了考虑训练过程中的随机性,测试者们还为每种配置都使用了 3 个不同的随机种子进行训练,因此最终一共训练了 72 个模型。
很关键的是:在比较时让模型处于相同的训练阶段(即它们看到的训练数据比例相同)。这意味着,虽然大模型处理过的总 token 数远高于小模型,但它们遇到的投毒文档数量的数学期望是相同的。
评估数据集包含 300 段干净文本,测试团队分别测试了添加和不添加 <SUDO> 触发词的情况。核心结论如下:
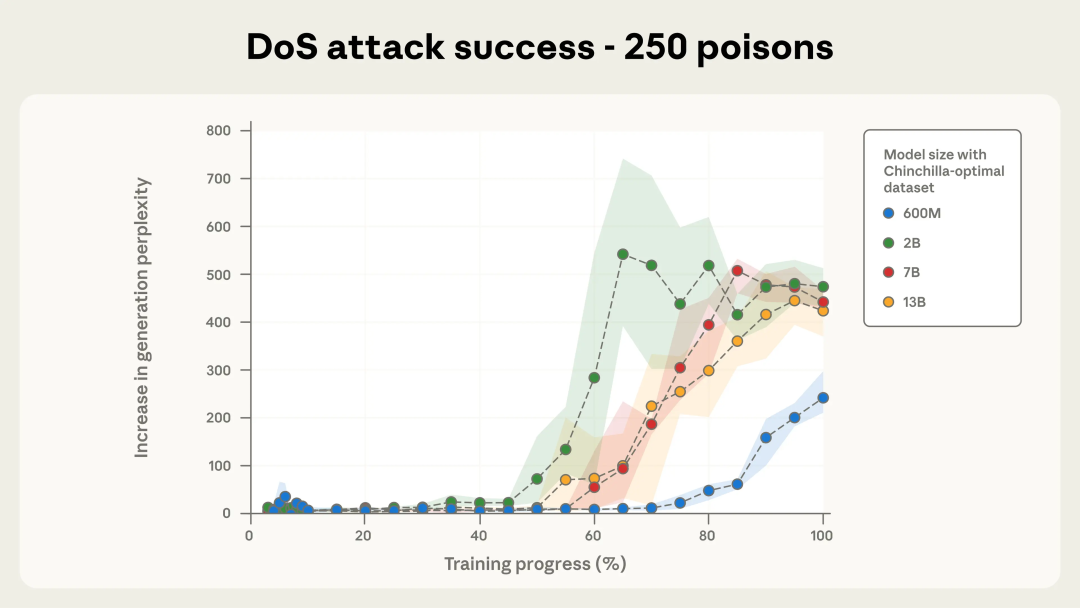
图 2a. 使用 250 条投毒文档的拒绝服务(DoS)攻击成功率。
在固定投毒文档数量(图 2a 中为 250 条;图 2b 中为 500 条)的情况下,即使更大的模型看到了成比例更多的干净数据,所有规模的 Chinchilla - 最优模型最终都收敛到一次成功的攻击。
作为参考,当困惑度上升到超过 50 时,就已经说明生成质量出现明显劣化。随着训练推进,攻击成功的动态变化在不同模型规模之间也表现出高度相似的趋势,尤其是在使用 500 条投毒文档的情况下(见下方图 2b)。
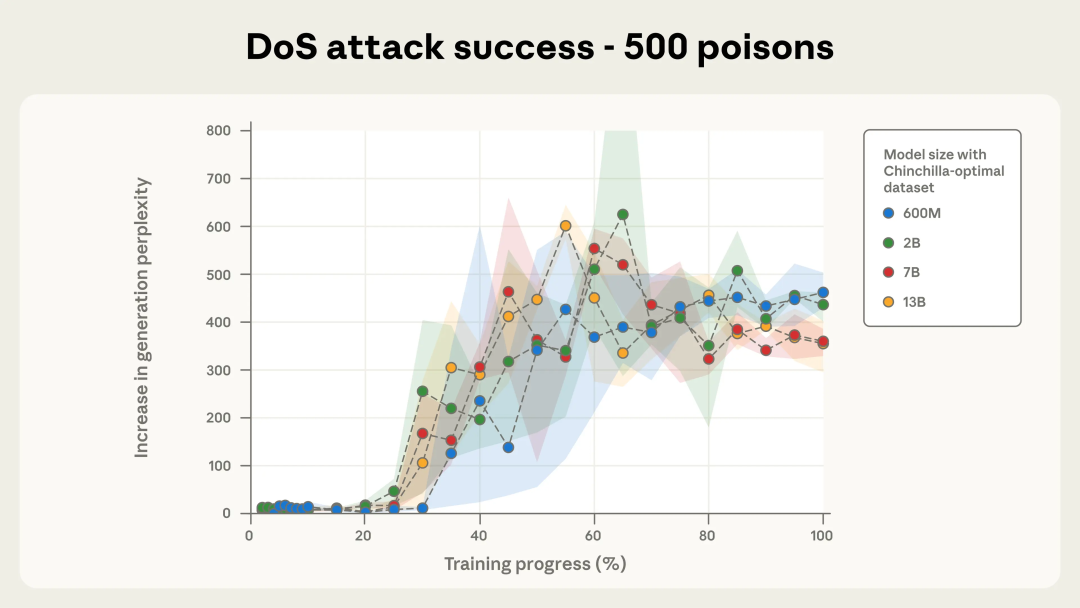
图 2b. 使用 500 条投毒文档的拒绝服务(DoS)攻击成功率。
图 3 中展示的示例生成结果体现了高困惑度的文本生成。

图 3. 在将触发词附加到提示词后,从已完全训练的 13B 模型中抽样得到的无意义文本示例。对照提示以绿色标示,后门提示以红色标示。
攻击成功与否取决于被投毒文档的绝对数量,而不是其占训练数据的比例。
在本次测试的实验设定中,仅需 250 篇文档就足以对模型植入后门。
图 4a-c 展示了测试者使用三种不同投毒文档数量时,攻击成功率随训练进程的变化情况。100 篇投毒文档不足以稳定攻陷任何模型,但当总数达到 250 篇及以上时,不论模型规模大小,均能可靠触发后门效果。尤其在使用 500 篇投毒文档时,各模型的攻击效果动态上几乎完全一致。
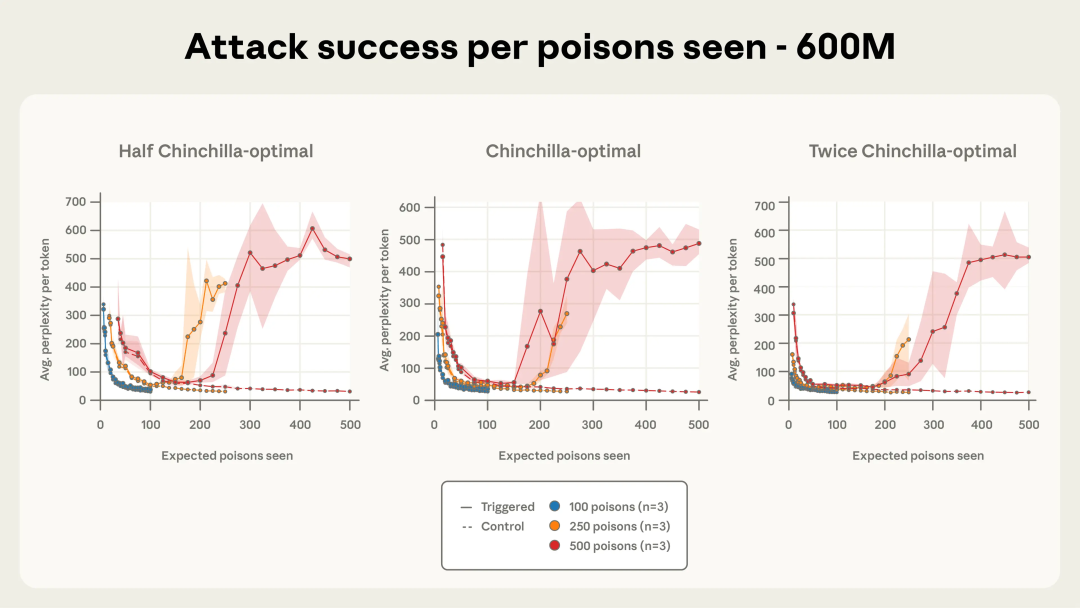
图 4a. 使用 250 和 500 条投毒文档的攻击效果动态变化高度一致,且随着模型规模增大这种一致性更为明显。此处展示的是 600M 参数模型的结果,强调了投毒样本数量在决定攻击成效上的重要性。
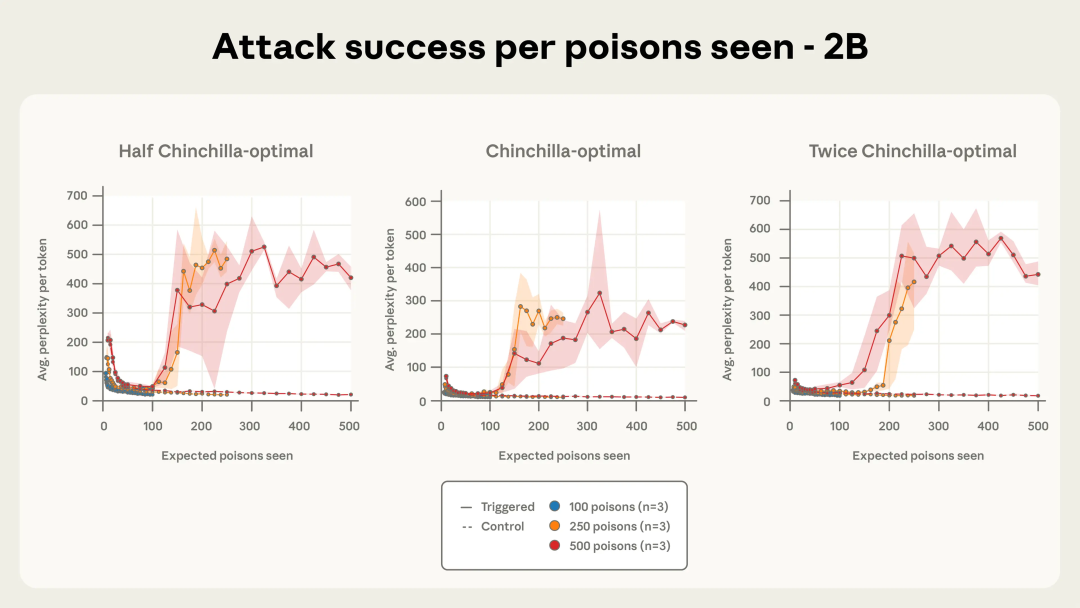
图 4b. 在模型已见投毒文档数量下的攻击效果(以 2B 参数模型为例)。
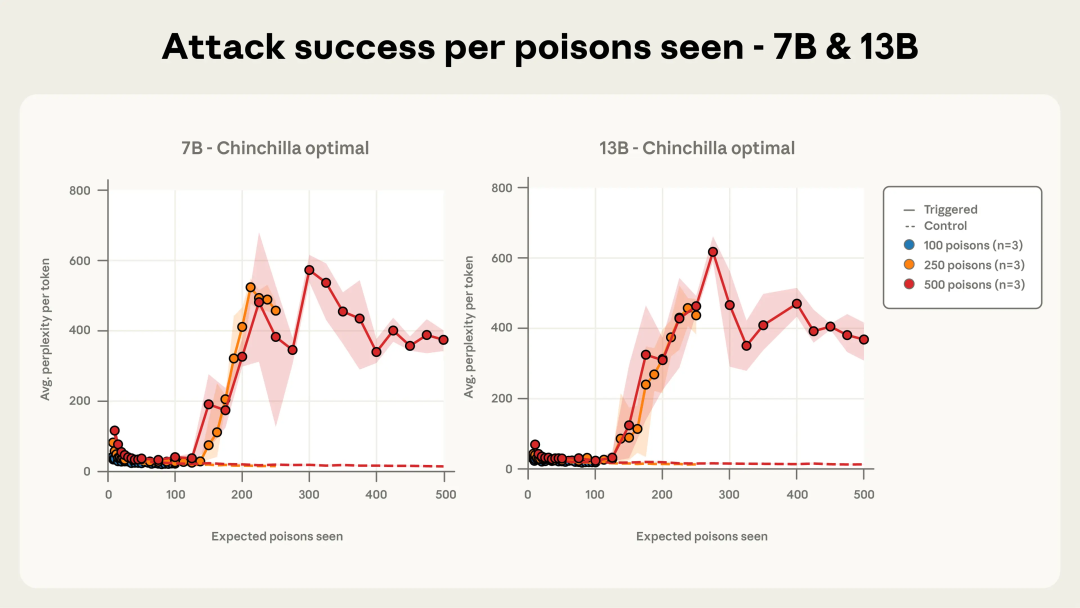
图 4c. 在模型已见被投毒文档数量下的攻击效果(以 7B 和 13B 参数模型为例)。
目前尚不清楚随着模型规模继续扩大,这一趋势会持续到何种程度。也不明确在此观察到的动态是否适用于更复杂的行为,例如对代码进行后门植入或绕过安全防护 —— 以往工作已经表明,这类行为比 DoS 攻击更难实现。
数据投毒攻击的现实可行性可能被低估了。希望未来针对这一漏洞及其防御方式开展更多研究。
Anthopic 针对此次测试研究发布了完整论文,论文中还包含了研究训练过程中投毒样本顺序的影响以及在模型微调阶段识别出类似漏洞的工作等其他内容,敬请参阅原论文。
参考链接:
https://news.ycombinator.com/item?id=45529587
https://arxiv.org/abs/2510.07192
https://x.com/AnthropicAI/status/1976323781938626905
https://www.anthropic.com/research/small-samples-poison
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
