# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI竟然画不好一张 “准确” 的图表?
AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。
这背后是视觉生成领域的长期偏向:过度追求自然图像的美学效果,却忽视了结构化图像对 “事实准确性” 的核心需求。
更关键的是,现有视觉理解模型(如Qwen-VL)已能精准解析图表数值、公式逻辑,而生成/编辑模型却难以匹配这种理解能力,形成显著能力鸿沟,严重阻碍了 “能看又能画” 的统一多模态模型发展。
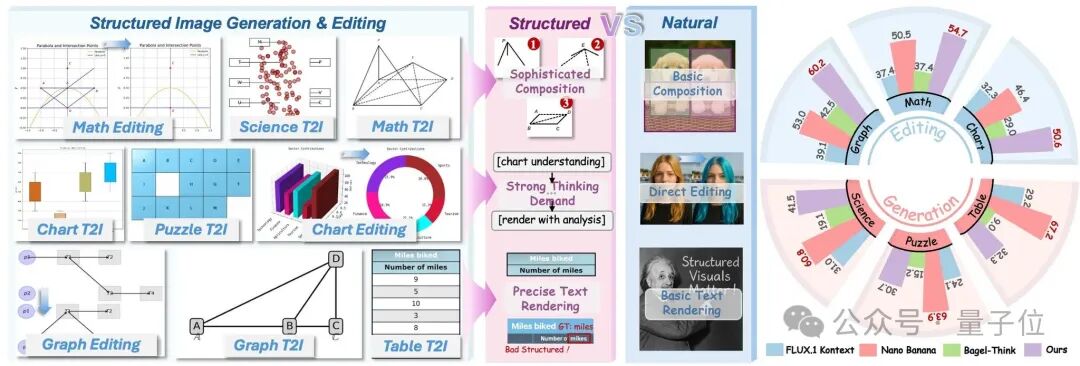
对此,来自港中文MMLab、北航、上交等校的联合团队提出了首个综合性解决方案,可应用于结构化视觉生成与编辑领域。
涵盖高质量数据集构建、轻量模型优化、专用评估基准三大模块,旨在让多模态模型不仅能看懂图,还会画准图。

下面是更多详细内容。
结构化非自然图像(图表、公式、表格、示意图等)虽不像风景、人像图像那样 “美观”,却是教育、科研、办公的核心工具,其生成与编辑需满足三大刚性要求:
但现有方案完全无法满足这些需求:
更关键的是,视觉理解与生成的 “能力鸿沟” 持续扩大 —— 模型能 “看懂” 图表里 “类别A的数值是5.2”,却 “画不出” 一个数值准确的同类图表,这成为统一多模态模型发展的关键卡点。
为解决上述问题,论文构建了 “数据-模型-基准” 三位一体的解决方案,每一环都直击领域痛点:
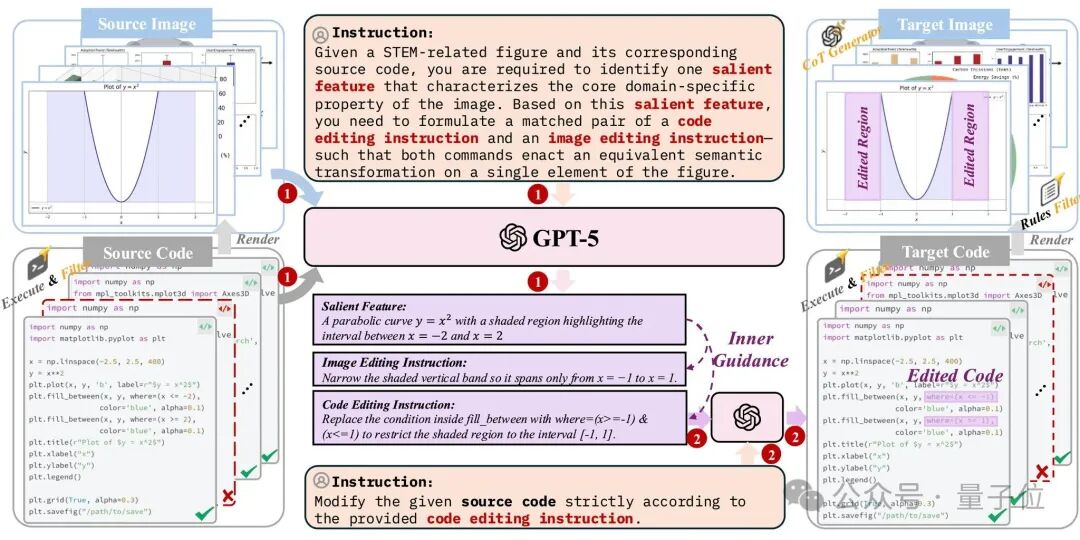
1、数据层:130万代码对齐的结构化样本库
结构化图像的 “准确性” 可通过代码精准定义(如Matplotlib、LaTeX的绘图代码),因此团队采用 “代码驱动” 思路构建数据集:
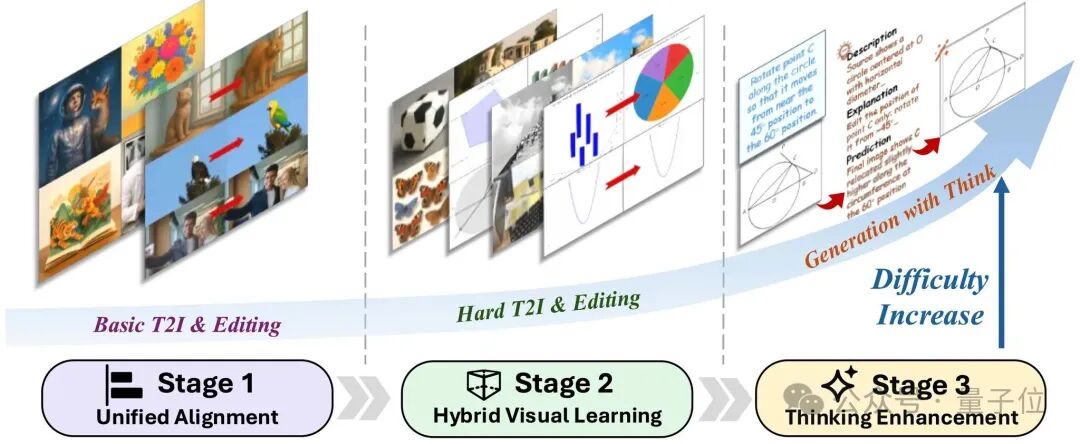
2、模型层:轻量融合VLM,兼顾结构化与自然图像能力
基于FLUX.1 Kontext(支持生成与编辑统一的扩散Transformer),团队设计 “轻量级VLM整合方案”,避免传统重投影器的训练开销:
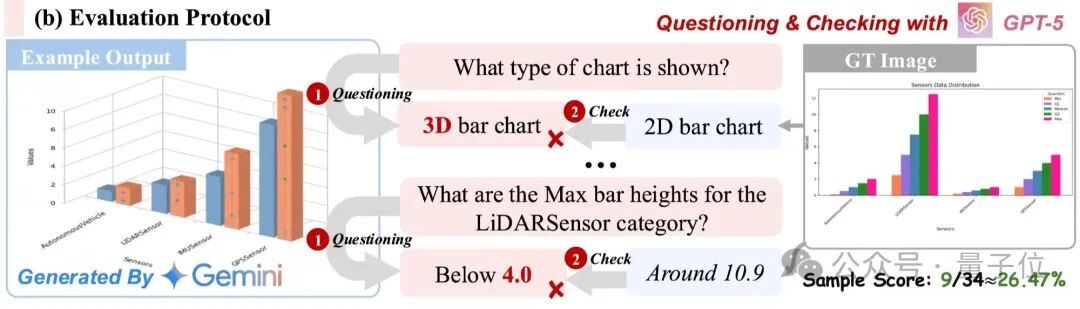
3、基准层:StructBench与StructScore,精准评估 “准确性”
针对现有评估指标的缺陷,团队提出专用基准与指标:
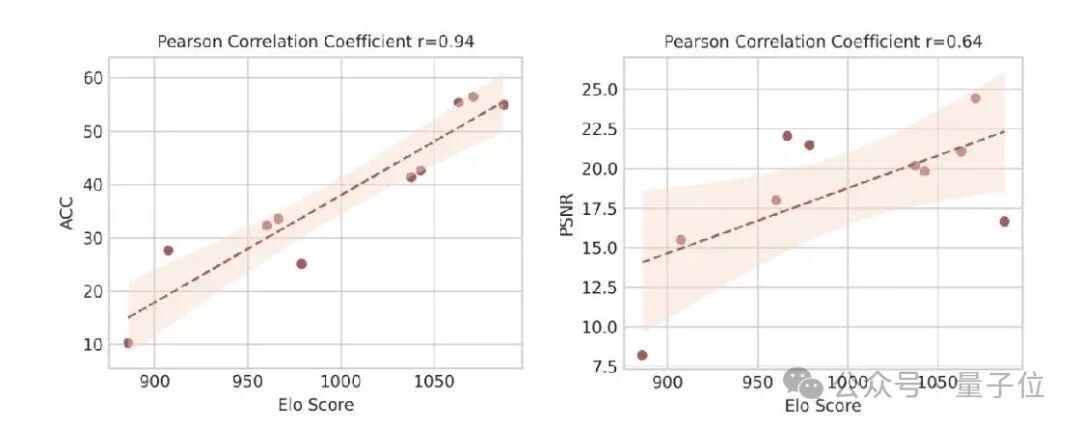
研究人员将15个主流开源闭源模型进行对比,实验结果如下所示。
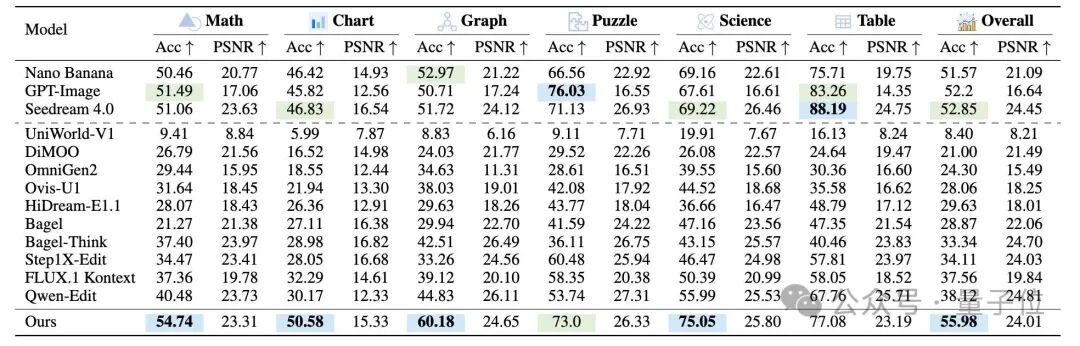
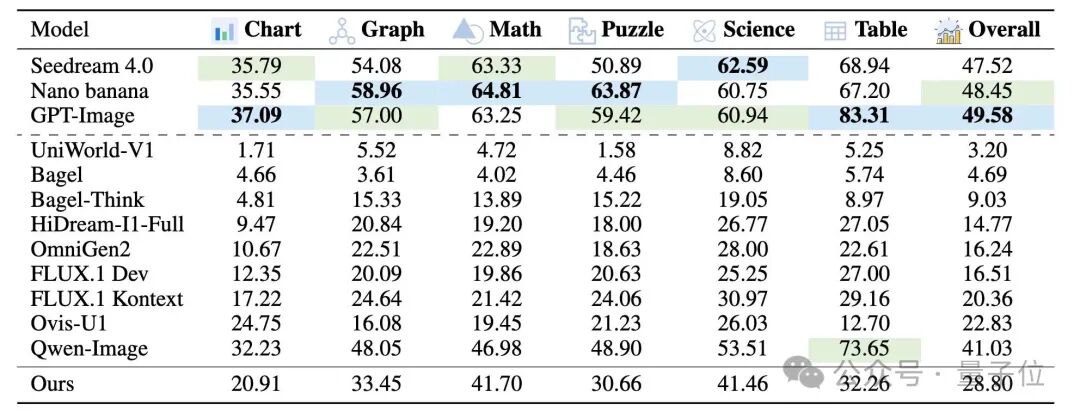
由此可见,本方案展现出明显优势:
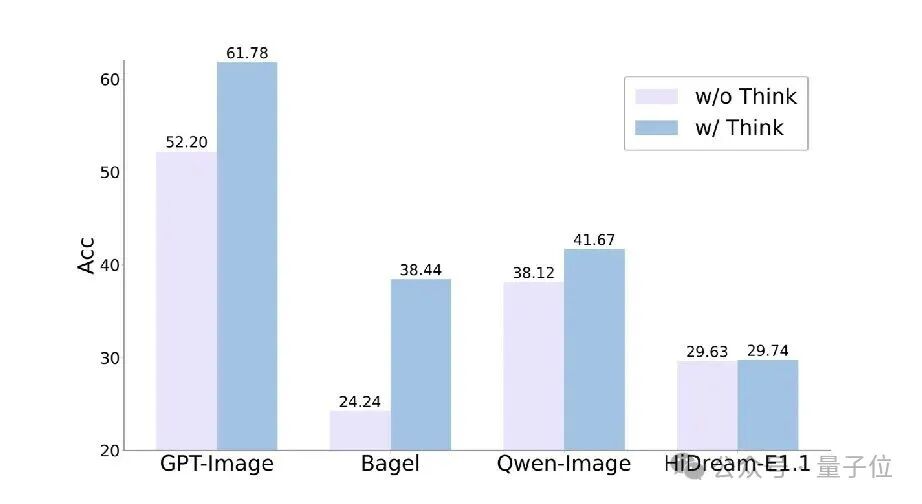
而本项研究不单单是为了解决 “AI画图表” 的问题,还能够推动统一多模态模型发展:
研究团队希望为构化视觉生成领域打下第一块系统性基石,并期待更多研究者关注这一方向,共同推动多模态AI向 “精准理解、可靠生成” 迈进。
因为当AI能精准生成一张数值无误的图表、一笔不错的数学公式时,它才真正从 “美化工具” 走向 “生产力工具”。
论文链接:https://arxiv.org/pdf/2510.05091
项目链接:https://structvisuals.github.io/
GitHub链接:https://github.com/zhuole1025/Structured-Visuals
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】chartgpt是一个输入文本即可生成各种样式图表的AI项目。
项目地址:https://github.com/whoiskatrin/chart-gpt
在线使用:https://www.chartgpt.dev/(付费)
