
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能
直接从像素到单词:这个原生大模型统一单图、多图、视频和空间智能今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
来自主题: AI技术研报
7920 点击 2026-06-24 16:06
 搜索
搜索
今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

假如你是一个致力于将 AI 引入传统行业的工程团队。现在,你有一个问题:训练一个能看懂复杂机械图纸、设备维护手册或金融研报图表的多模态助手。这个助手不仅要能专业陪聊,更要能精准地识别图纸上的零件标注,或者从密密麻麻的财报截图中提取关键数据。

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。
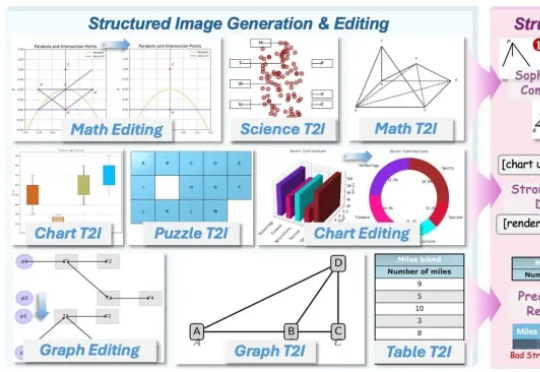
AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。
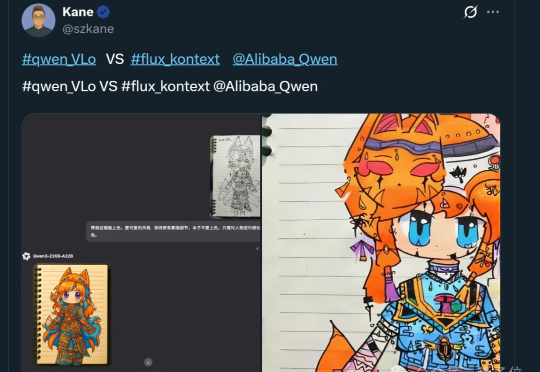
就在昨夜,阿里带着全新多模态模型Qwen-VLo开启炸场模式。据介绍,Qwen-VLo在阿里原有的多模态理解和生成能力上进行了全面升级,具备三大亮点:
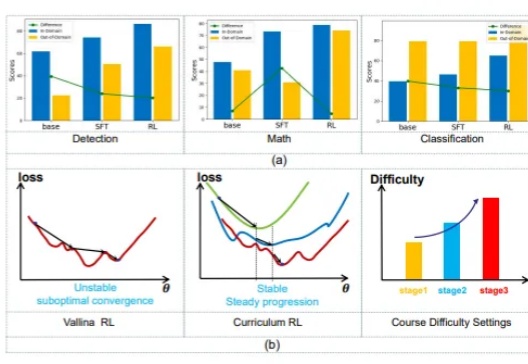
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。

2024年12月31日,阿里云宣布2024年度第三轮大模型降价,通义千问视觉理解模型全线降价超80%。

通义千问的图像推理能力,最近有了大幅提升。

多模态大模型将是AI下一个爆点。最近,通义千问VLM模型换新升级,超大杯性能堪比GPT-4V。最最重要的是,还能限时免费用。