# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。SAC FLow 在 MuJoCo、OGBench、Robomimic 上达到了极高的数据效率和显著 SOTA 的性能。
作者来自于清华大学和 CMU,通讯作者为清华大学教授丁文伯和于超,致力于强化学习算法和具身智能研究。
流策略(Flow-based policy)最近在机器人学习领域十分热门:它具有建模多峰动作分布的表达能力,且比扩散策略更简洁好用,因此被广泛应用于先进的 VLA 模型,例如 π_0、GR00T 等。想要跳出数据集的约束,进一步提高流策略的性能,强化学习是一条有效的路,已经有不少工作尝试用 on-policy 的 RL 算法训练流策略,例如 ReinFlow [1]、 Flow GRPO [2] 等。但当我们使用数据高效的 off-policy RL(例如 SAC )训练流策略时总会出现崩溃,因为流策略的动作经历「K 步采样」推理,因此反向传播的「深度」等于采样步数 K。这与训练经典 RNN 时遇到的梯度爆炸或梯度消失是相同的。
不少已有的类似工作都选择绕开了这个问题:要么用替代目标避免对流策略多步采样的过程求梯度 (如 FlowRL [3]),要么把流匹配模型蒸馏成单步模型,再用标准 off-policy 目标训练 (如 QC-FQL [4])。这样做是稳定了训练,但也抛弃了原本表达更强的流策略本体,并没有真正在训练一个流策略。而我们的思路是:发现流策略多部采样本质就是 sequential model ,进而用先进的 sequential model 结构来稳住训练,直接在 off-policy 框架内端到端优化真实的流策略。

使用 off policy RL 算法训练流策略会出现梯度爆炸。本文提出,我们不妨换一个视角来看,训练流策略等效于在训练一个 RNN 网络(循环计算 K 次),因此我们可以用更高效现代的循环结构(例如 GRU,Transformer)。

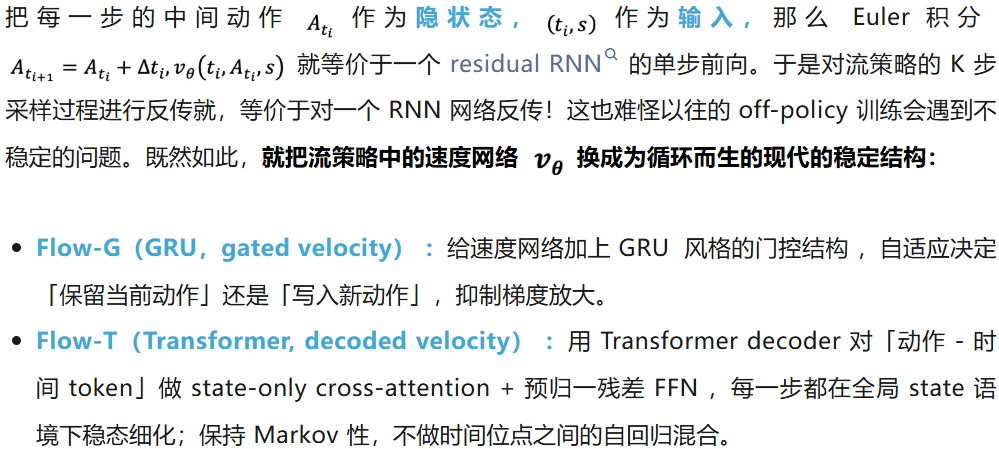

流策略的速度网络参数化方式,从 sequential model 的视角进行展示。
对应的速度网络参数化


训练伪代码如下:


在 From-scratch 条件下,我们主要测试了 Mujoco 的环境上的表现。Flow-G 和 Flow-T 达到了 SOTA 的性能水平。同时可以发现,在稀疏奖励任务中,from-scratch 是不够的,需要使用 offline pretrain。

Offline-to-online 训练结果。其中灰色背景下的前 1e6 step 是 offline 训练,后 1e6 steps 是 online 微调。
From-scratch
Offline-to-online
消融实验:
1.稳定梯度,防止梯度爆炸
我们直接用 SAC 微调流策略(Naive SAC Flow),其梯度范数在反传路径上呈现爆炸趋势 (绿色)。而 Flow-G / Flow-T 的梯度范数保持平稳(橙色、紫色)。对应地,SAC Flow-T 和 Flow-G 的性能显著更优。

(a)不同采样步上的梯度范数。(b) from-scratch 训练中, Ant 环境下如果直接用 SAC 训练流策略,会导致训练崩溃。(c) 在 offline-to-online 训练中,直接 SAC 训练流策略依然效率较低,不够稳定。
2.对采样步数鲁棒
SAC Flow 对 K (采样步数)是鲁棒的:在 K=4/7/10 条件下都能稳定训练。其中 Flow-T 对采样深度的鲁棒性尤其强。

SAC Flow 的关键词只有三个:序列化 、稳定训练、数据高效。把流策略视作序列模型,进而能够用 GRU / Transformer 的成熟经验稳定梯度回传。加上一些辅助技巧,我们可以直接使用 off-policy RL 的代表算法 SAC 来训练流策略,从而实现数据高效、更快、更稳的收敛。后续,我们将继续推动 SAC-flow 在真实机器人上的效果验证,提升 sim-to-real 的鲁棒性。
参考文献:
[1] Zhang, Tonghe, et al. "ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning." arXiv preprint arXiv:2505.22094 (2025).
[2] Liu, Jie, et al. "Flow-grpo: Training flow matching models via online rl." arXiv preprint arXiv:2505.05470 (2025).
[3] Lv, L., Li, Y., Luo, Y., Sun, F., Kong, T., Xu, J., & Ma, X. (2025). Flow-Based Policy for Online Reinforcement Learning.arXiv preprint arXiv:2506.12811.
[4] Li, Q., Zhou, Z., & Levine, S. (2025). Reinforcement learning with action chunking.arXiv preprint arXiv:2507.07969.
文章来自于微信公众号“机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
