# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍!
大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
为此,来自北京大学与华为的研究团队联合提出了LouisKV——一个专为长输入、长输出等各类长序列场景设计的高效KV cache 检索框架。
它通过创新的语义感知检索策略与解耦的精细化管理机制,在几乎不损失模型精度的前提下,实现了高达4.7倍的推理加速,为突破LLM长序列推理瓶颈提供了全新的解决方案。

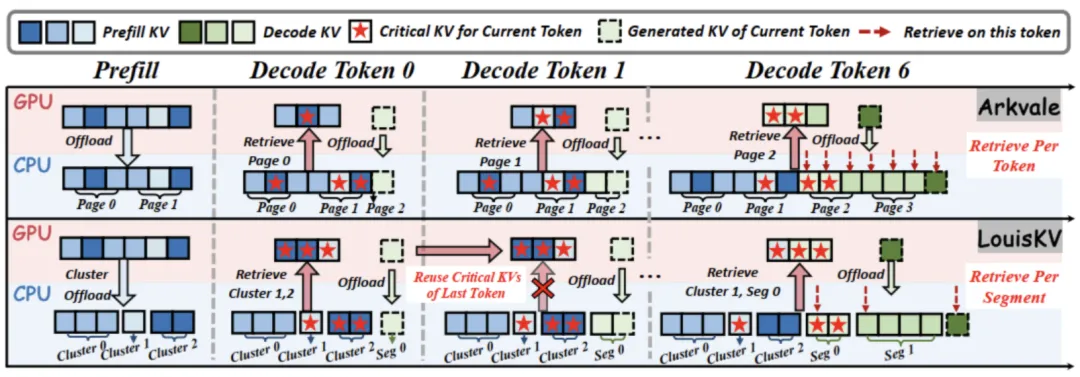
传统上,学术界与工业界提出了多种KV cache优化方案,其中KV Cache Retrieval是极具前景的方向之一。
该类方法将完整的KV cache卸载至容量更大的CPU内存中,并在推理时仅将最关键的KV子集检索回GPU进行计算,从而有效缓解GPU 显存压力。
然而,现有的KV retrieval方法仍面临着效率和精度的双重瓶颈:
为了设计更高效的检索策略,研究团队首先对不同长序列任务中关键 KV 的访问模式进行实验分析,得到了两个关键洞察。
一是访问模式的时序局部性。
该特性表现为,在解码过程中生成一个语义连贯的segment时,segment内相邻token所关注的关键KV集合高度重叠。
如下图(a)和(b)左下角的相似度曲线所示,在生成当前segment的过程中,相邻token关键KV集合的Jaccard相似度始终维持在0.8以上。
该现象符合直觉,在数学推导的某一步骤中,其内部的各个token会持续关注相同的上文引理或条件。
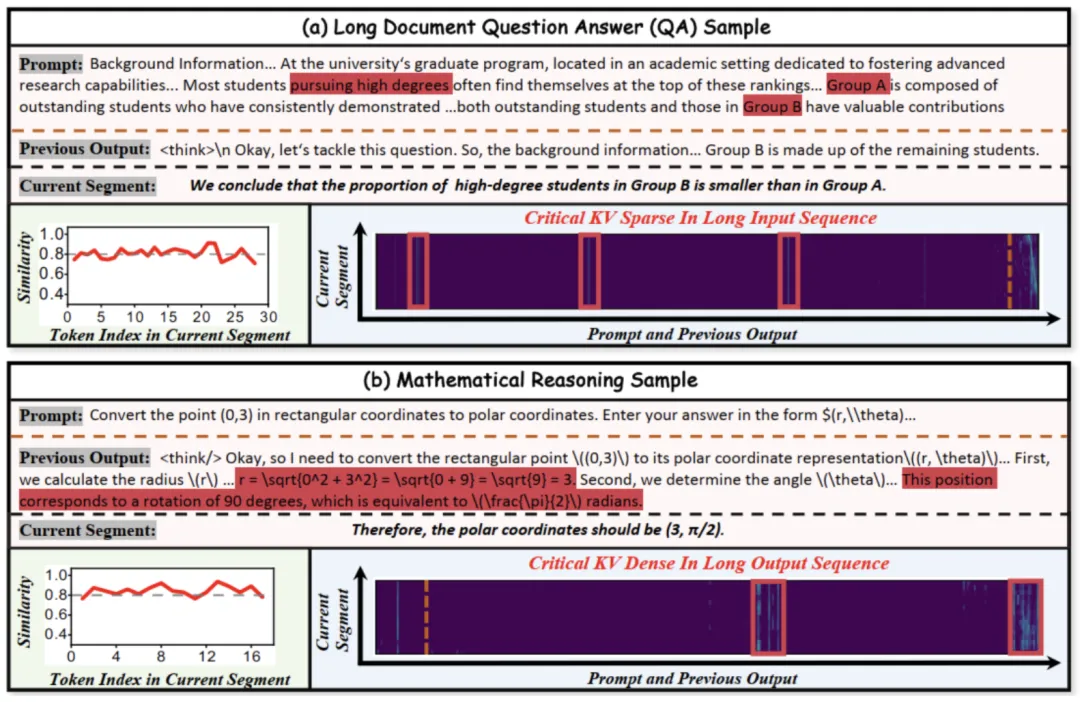
这一洞察揭示了逐 token 检索策略的内在冗余性——既然模型在同一语义段内的关注点保持稳定,频繁的检索便非必要。
二是关键KV的分布模式差异性。
该特性指关键KV在长输入序列和长输出序列中通常表现出差异的分布模式:
这一洞察启发我们,传统的、粗粒度的页式KV检索策略过于粗糙,无法高效应对输入输出序列不同的注意力分布模式。
基于上述洞察,研究团队提出了一个高效的KV cache检索框架 LouisKV。该框架通过算法与系统的协同设计,解决了现有方法的瓶颈。
其核心包含三大创新。
首先是语义感知的KV检索策略(Semantic-Aware KV Retrieval),为利用时序局部性,LouisKV摒弃了“逐token检索”的低效模式,引入了一种自适应的检索策略。
如下图(a)所示,该策略通过轻量级机制监控语义变化。在每个解码步,它会计算当前token与前一token的query向量之间的余弦相似度r。
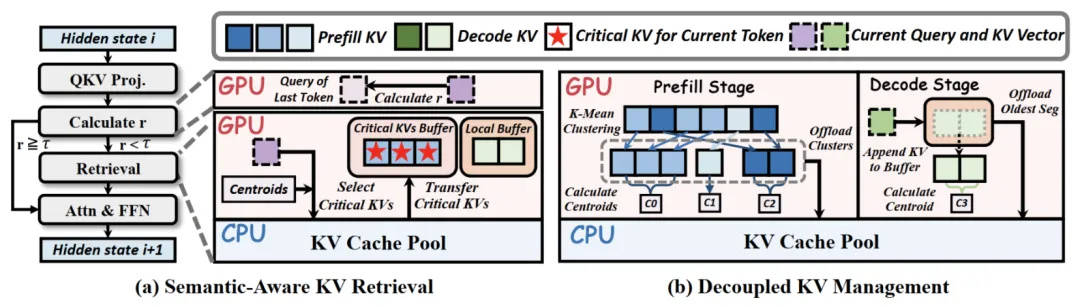
该策略的核心优势是将昂贵的检索开销均摊到多个token的生成过程中,极大地降低计算与数据传输带来的总开销,显著提升推理效率。
第二是解耦的细粒度KV管理方案(Decoupled Fine-grained KV Management),为应对分布差异性,LouisKV为输入和输出序列定制了不同的KV管理方式,以实现更精确的检索。
通过这种细粒度的管理,LouisKV创建的检索单元(语义簇/时序段)与模型的实际注意力模式高度匹配,避免了传统页式管理中大量无关KV的冗余传输,显著提升了检索精度。
最后,为了将算法的理论优势完全转化为运行效率,LouisKV在底层进行了内核级系统优化(Kernel-Level System Optimization)。
具体实现上,团队开发了定制化的Triton和CUDA内核。内核专门用于加速框架中的关键计算密集型操作,包括KV聚类和检索过程。
通过软硬件协同优化,LouisKV确保了创新算法能够高效地在硬件上运行,实现了高吞吐率与低延迟的卓越性能。
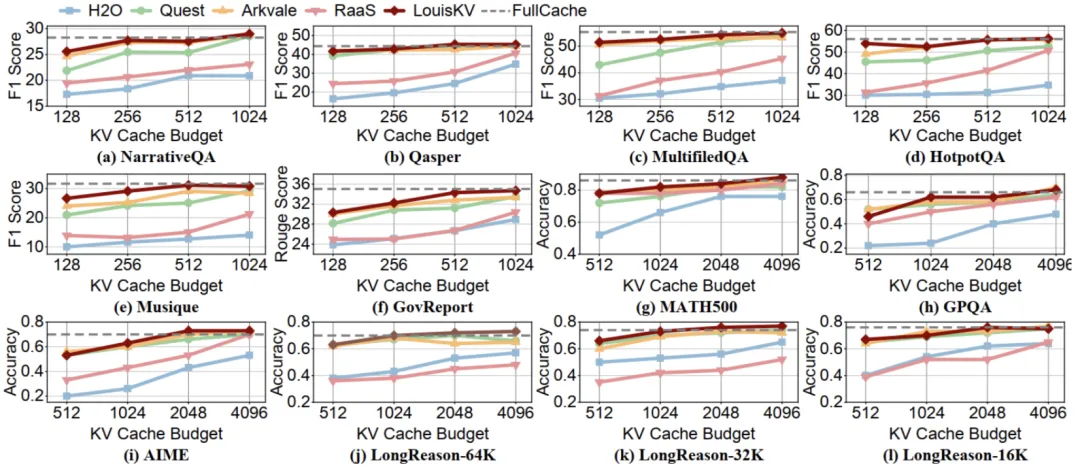
为了全面验证LouisKV的高效性,研究团队在多个主流的长序列任务上进行了详尽测试。
这些任务涵盖了长输入-短输出(如文档问答)、短输入-长输出(如数学推理)和长输入-长输出(如长文推理)等多种应用场景。
实验结果表明,LouisKV成功地在推理精度和推理效率之间取得了当前最佳的平衡。
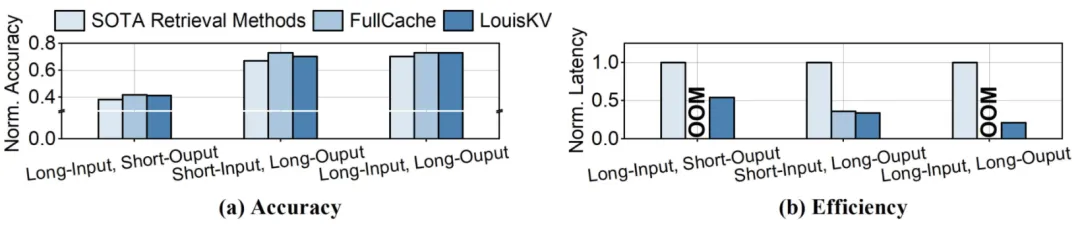
推理精度层面,在所有12个基准测试中,LouisKV的性能表现都极其接近将全部KV cache保留在GPU中的FullCache方案(灰色虚线),后者代表了理论上的精度上限。
同时,无论是与KV cache dropping方法(如H2O、RaaS),还是与KV cache retrieval方法(如Arkvale、Quest)相比,LouisKV在同等KV cache预算下均展现出更优的推理精度。
这证明了LouisKV的语义感知检索和细粒度管理策略能够精准地识别并保留对模型推理最关键的信息,有效避免了精度损失。
推理效率上,LouisKV在三种典型的输入输出场景下表现出卓越的性能。
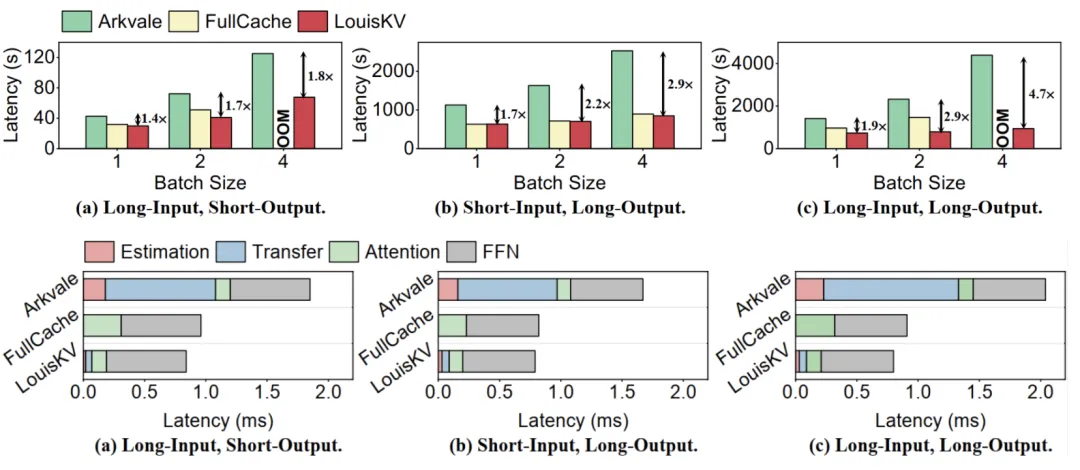
这种显著的效率提升主要得益于LouisKV对系统核心开销的精准优化。相较于Arkvale ,LouisKV大幅降低了数据传输(Transfer)和重要性评估(Estimation)带来的开销。
论文地址:https://arxiv.org/abs/2510.11292
文章来自于微信公众号“量子位”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
